不同場景下MySQL的遷移方案
阿新 • • 發佈:2018-12-30
一 為什麼要遷移
MySQL 遷移是 DBA 日常維護中的一個工作。遷移,究其本義,無非是把實際存在的物體挪走,保證該物體的完整性以及延續性。就像柔軟的沙灘上,兩個天真無邪的小孩,把一堆沙子挪向其他地方,鑄就內心神往的城堡。
生產環境中,有以下情況需要做遷移工作,如下:
1.磁碟空間不夠。比如一些老專案,選用的機型並不一定適用於資料庫。隨著時間的推移,硬碟很有可能出現短缺;
2.業務出現瓶頸。比如專案中採用單機承擔所有的讀寫業務,業務壓力增大,不堪重負。如果 IO 壓力在可接受的範圍,會採用讀寫分離方案;
3.機器出現瓶頸。機器出現瓶頸主要在磁碟 IO 能力、記憶體、CPU,此時除了針對瓶頸做一些優化以外,選擇遷移是不錯的方案;
4.專案改造。某些專案的資料庫存在跨機房的情況,可能會在不同機房中增加節點,或者把機器從一個機房遷移到另一個機房。再比如,不同業務共用同一臺伺服器,為了緩解伺服器壓力以及方便維護,也會做遷移。
一句話,遷移工作是不得已而為之。實施遷移工作,目的是讓業務平穩持續地執行。
二 MySQL 遷移方案概覽
MySQL 遷移無非是圍繞著資料做工作,再繼續延伸,無非就是在保證業務平穩持續地執行的前提下做備份恢復。那問題就在怎麼快速安全地進行備份恢復。
一方面,備份。針對每個主節點的從節點或者備節點,都有備份。這個備份可能是全備,可能是增量備份。線上備份的方法,可能是使用 mysqldump,可能是 xtrabackup,還可能是 mydumper。針對小容量(10GB 以下)資料庫的備份,我們可以使用 mysqldump。但針對大容量資料庫(數百GB 或者 TB 級別),我們不能使用 mysqldump 備份,一方面,會產生鎖;另一方面,耗時太長。這種情況,可以選擇 xtrabackup 或者直接拷貝資料目錄。直接拷貝資料目錄方法,不同機器傳輸可以使用 rsync,耗時跟網路相關。使用
xtrabackup,耗時主要在備份和網路傳輸。如果有全備或者指定庫的備份檔案,這是獲取備份的最好方法。如果備庫可以容許停止服務,直接拷貝資料目錄是最快的方法。如果備庫不允許停止服務,我們可以使用 xtrabackup(不會鎖定 InnoDB 表),這是完成備份的最佳折中辦法。
另一方面,恢復。針對小容量(10GB 以下)資料庫的備份檔案,我們可以直接匯入。針對大容量資料庫(數百GB 或者 TB 級別)的恢復,拿到備份檔案到本機以後,恢復不算困難。具體的恢復方法可以參考第三節。
三 MySQL 遷移實戰
我們搞明白為什麼要做遷移,以及遷移怎麼做以後,接下來看看生產環境是怎樣操作的。不同的應用場景,有不同的解決方案。
閱讀具體的實戰之前,假設和讀者有如下約定:
1.為了保護隱私,本文中的伺服器 IP 等資訊經過處理;
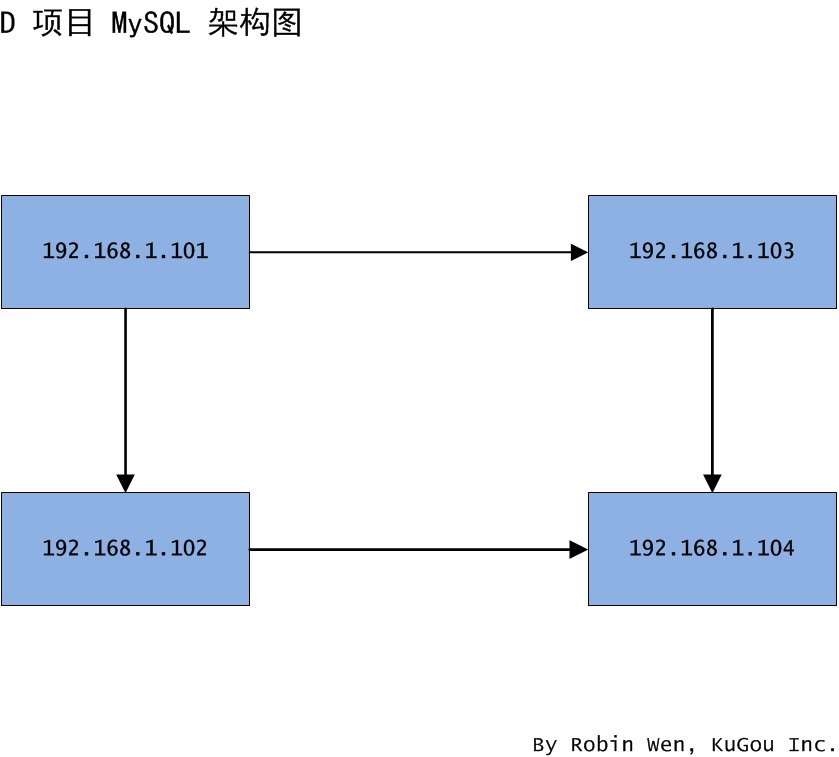
2.如果伺服器在同一機房,用伺服器 IP 的 D 段代替伺服器,具體的 IP 請參考架構圖;
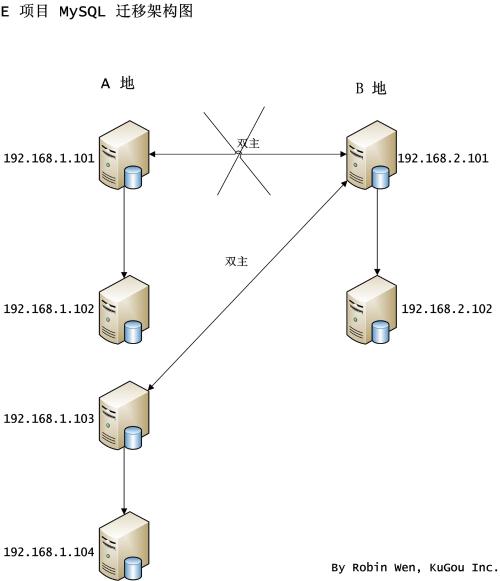
3.如果伺服器在不同機房,用伺服器 IP 的 C 段 和 D 段代替伺服器,具體的 IP 請參考架構圖;
4.每個場景給出方法,但不會詳細地給出每一步執行什麼命令,因為一方面,這會導致文章過長;另一方面,我認為只要知道方法,具體的做法就會迎面撲來的,只取決於掌握知識的程度和獲取資訊的能力;
5.實戰過程中的注意事項請參考第四節。
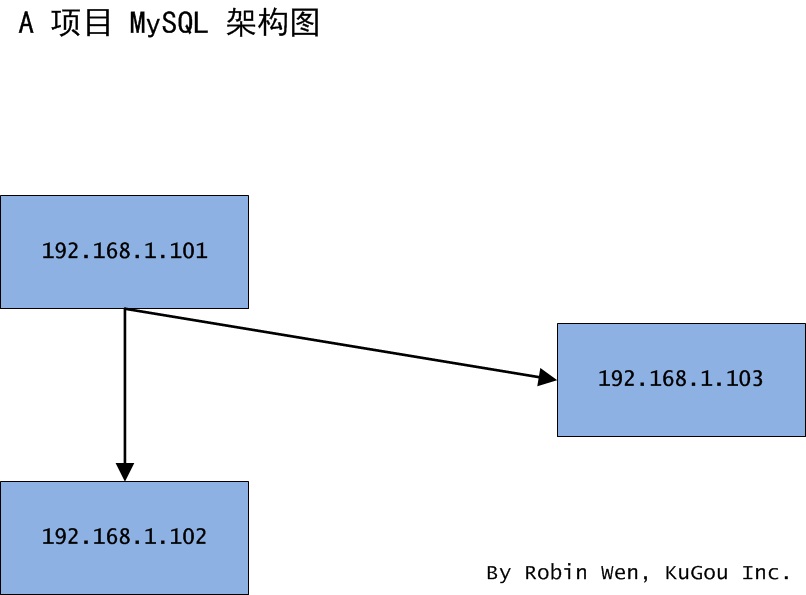
3.1 場景一 一主一從結構遷移從庫
遵循從易到難的思路,我們從簡單的結構入手。A 專案,原本是一主一從結構。101 是主節點,102 是從節點。因業務需要,把 102 從節點遷移至 103,架構圖如圖一。102 從節點的資料容量過大,不能使用 mysqldump 的形式備份。和研發溝通後,形成一致的方案。