
JVM記憶體堆佈局圖解分析
JAVA能夠實現跨平臺的一個根本原因,是定義了class檔案的格式標準,凡是實現該標準的JVM都能夠載入並解釋該class檔案,據此也可以知道,為啥Java語言的執行速度比C/C++語言執行的速度要慢了,當然原因肯定不止這一個,如在JVM中沒有資料暫存器,指令集使用的是棧來儲存中間資料…等,儘管Java的貢獻者們為執行速度的提高想了各種辦法,如JIT、動態編譯器等,以下是Leetcode中一道題目用不同的語言實現時的執行效能對比圖…

以下是JVM的一個基本架構圖,在這個基本架構圖中,棧有兩部份,Java執行緒棧以及本地方法棧,棧的概念與C/C++程式基本上都是一個概念,裡面存放的都是棧幀,一個棧幀代表的就是一個函式的呼叫,在棧幀裡面存放了函式的形參,函式的區域性變數, 返回地址等,但是與C/C++的一個重要區別是,C/C++裡面有傳值以及傳址的區別,當傳的是一個物件時( 結構體也可以當成物件,其實就是物件~,只不過裡面的方法預設都是public的,不信你可以試試,在結構體中加一個函式,編譯器也不會報錯,程式依舊執行~~~),會將物件復到到棧中,而Java中只有基本型別才是傳值的,其他型別傳的都是引用,什麼是引用,學過C/C++的就把引用當作指標理解吧~~~,在這個基本架構圖中,可以看出JVM還定義了一個本地方法棧,本地方法棧是為Java呼叫本地方法【這些本地方法是由其他語言編寫的】服務的

上面的圖中看到的是JVM中棧有兩個,但是堆只有一個,每一個執行緒都有自已的執行緒棧【執行緒棧的大小可以通過設定JVM的-xss引數進行配置,32位系統下,JDK5.0以後每個執行緒堆疊大小為1M,以前每個執行緒堆疊大小為256K】,執行緒棧裡面的資料屬於該執行緒私有,但是所有的執行緒都共享一個堆空間,堆中存放的是物件資料,什麼是物件資料,排除法,排除基本型別以及引用型別以外的資料都將放在堆空間中。其中方法區和堆是所有執行緒共享的資料區。
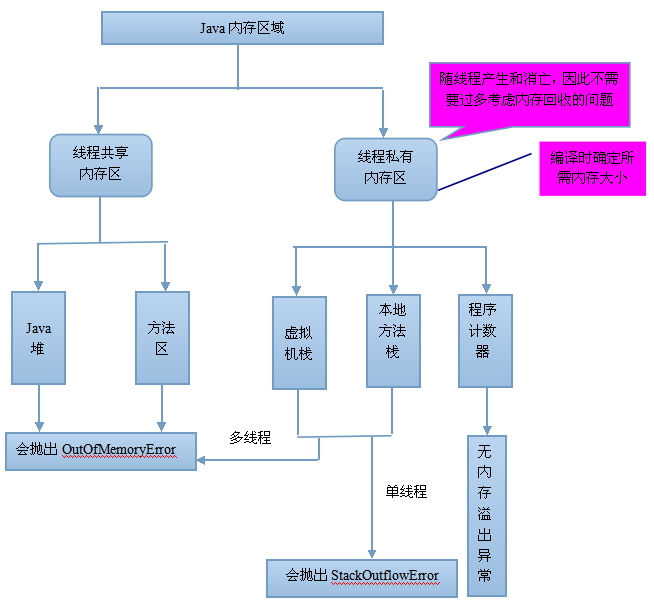
1.程式計數器
在CPU的暫存器中有一個PC暫存器,存放下一條指令地址,這裡,虛擬機器不使用CPU的程式計數器,自己在記憶體中設立一片區域來模擬CPU的程式計數器。只有一個程式計數器是不夠的,當多個執行緒切換執行時,那就單個程式計數器就沒辦法了,虛擬機器規範中指出,每一條執行緒都有一個獨立的程式計數器
2. Java虛擬機器棧
Java虛擬機器棧也是執行緒私有的,虛擬機器棧描述的是Java方法執行的記憶體模型:每個方法執行的時候都會建立一個棧幀,用於存放區域性變量表,運算元棧,動態連結,方法出口等資訊。每一個方法從呼叫直到執行完成的過程都對應著一個棧幀在虛擬機器中的入棧到出棧的過程。我們平時把記憶體分為堆記憶體和棧記憶體,其中的棧記憶體就指的是虛擬機器棧的區域性變量表部分。區域性變量表存放了編譯期可以知道的基本資料型別(boolean、byte、char、short、int、float、long、double),物件引用(可能是一個指向物件起始地址的引用指標,也可能指向一個代表物件的控制代碼或者其他與此物件相關的位置),和返回後所指向的位元組碼的地址。其中64 位長度的long 和double 型別的資料會佔用2個區域性變數空間(Slot),其餘的資料型別只佔用1個
3. 本地方法棧
在HotSpot虛擬機器將本地方法棧和虛擬機器棧合二為一,它們的區別在於,虛擬機器棧為執行Java方法服務,而本地方法棧則為虛擬機器使用到的Native方法服務。
4. Java堆
Java 堆是被所有執行緒共享的一塊記憶體區域,在虛擬機器啟動時建立。這個區域是用來存放物件例項的,幾乎所有物件例項都會在這裡分配記憶體。堆是Java垃圾收集器管理的主要區域(GC堆),垃圾收集器實現了物件的自動銷燬。Java堆可以細分為:新生代和老年代;再細緻一點的有Eden空間,From Survivor空間,To Survivor空間等。Java堆可以處於物理上不連續的記憶體空間中,只要邏輯上是連續的即可,就像我們的磁碟空間一樣。可以通過-Xmx和-Xms控制
5. 方法區
方法區也叫永久代。在過去(自定義類載入器還不是很常見的時候),類大多是”static”的,很少被解除安裝或收集,因此被稱為“永久的(Permanent)”。雖然Java 虛擬機器規範把方法區描述為堆的一個邏輯部分,但是它卻有一個別名叫做Non-Heap(非堆),目的應該是與Java 堆區分開來。同時,由於類class是JVM實現的一部分,並不是由應用建立的,所以又被認為是“非堆(non-heap)”記憶體。HotSpot 虛擬機器的設計團隊選擇把GC 分代收集擴充套件至方法區,或者說使用永久代來實現方法區而已。對於其他虛擬機器(如BEA JRockit、IBM J9 等)來說是不存在永久代的概念的。
永久代也是各個執行緒共享的區域,它用於儲存已經被虛擬機器載入過的類資訊,常量,靜態變數(JDK7中被移到Java堆),即時編譯期編譯後的程式碼(類方法)等資料。這裡要講一下執行時常量池,它是方法區的一部分,用於存放編譯期生成的各種字面量和符號引用(其實就是八大基本型別的包裝型別和String型別資料(JDK7中被移到Java堆))(官方文件說明: In JDK 7, interned strings are no longer allocated in the permanent generation of the Java heap, but are instead allocated in the main part of the Java heap (known as the young and old generations), along with the other objects created by the application)。
在JDK1.7中的HotASpot中,已經把原本放在方法區的字串常量池移出。
- 將interned String移到Java堆中
- 將符號Symbols移到native memory(不受GC管理的記憶體)
從JDK7開始永久代的移除工作,貯存在永久代的一部分資料已經轉移到了Java Heap或者是Native Heap。但永久代仍然存在於JDK7,並沒有完全的移除:符號引用(Symbols)轉移到了native heap;字面量(interned strings)轉移到了java heap;類的靜態變數(class statics)轉移到了java heap。隨著JDK8的到來,JVM不再有PermGen。但類的元資料資訊(metadata)還在,只不過不再是儲存在連續的堆空間上,而是移動到叫做“Metaspace”的本地記憶體(Native memory)中。
在JVM中共享資料空間劃分如下圖所示

上圖中,刻畫了Java程式執行時的堆空間,可以簡述成如下2條
1.JVM中共享資料空間可以分成三個大區,新生代(Young Generation)、老年代(Old Generation)、永久代(Permanent Generation),其中JVM堆分為新生代和老年代
2.新生代可以劃分為三個區,Eden區(存放新生物件),兩個倖存區(From Survivor和To Survivor)(存放每次垃圾回收後存活的物件)
3.永久代管理class檔案、靜態物件、屬性等(JVM uses a separate region of memory, called the Permanent Generation (orPermGen for short), to hold internal representations of java classes. PermGen is also used to store more information )
4.JVM垃圾回收機制採用“分代收集”:新生代採用複製演算法,老年代採用標記清理演算法。
作為作業系統程序,Java 執行時面臨著與其他程序完全相同的記憶體限制:作業系統架構提供的可定址地址空間和使用者空間。
操 作系統架構提供的可定址地址空間,由處理器的位數決定,32 位提供了 2^32 的可定址範圍,也就是 4,294,967,296 位,或者說 4GB。而 64 位處理器的可定址範圍明顯增大:2^64,也就是 18,446,744,073,709,551,616,或者說 16 exabyte(百億億位元組)。
地址空間被劃分為使用者空間和核心空間。核心是主要的作業系統程式和C執行時,包含用於連線計算機硬體、排程程式以及提供聯網和虛擬記憶體等服務的邏輯和基於C的程序(JVM)。除去核心空間就是使用者空間,使用者空間才是 Java 程序實際執行時使用的記憶體。
預設情況下,32 位 Windows 擁有 2GB 使用者空間和 2GB 核心空間。在一些 Windows 版本上,通過向啟動配置新增 /3GB 開關並使用 /LARGEADDRESSAWARE 開關重新連結應用程式,可以將這種平衡調整為 3GB 使用者空間和 1GB 核心空間。在 32 位 Linux 上,預設設定為 3GB 使用者空間和 1GB 核心空間。一些 Linux 分發版提供了一個hugemem核心,支援 4GB 使用者空間。為了實現這種配置,將進行系統呼叫時使用的地址空間分配給核心。通過這種方式增加使用者空間會減慢系統呼叫,因為每次進行系統呼叫時,作業系統必須在地址空間之間複製資料並重置程序地址-空間對映。
下圖為一個32 位 Java 程序的記憶體佈局:

可定址的地址空間總共有 4GB,OS 和 C 執行時大約佔用了其中的 1GB,Java 堆佔用了將近 2GB,本機堆佔用了其他部分。請注意,JVM 本身也要佔用記憶體,就像 OS 核心和 C 執行時一樣。
注意:
1. 上文提到的可定址空間即指最大地址空間。
2. 對於2GB的使用者空間,理論上Java堆記憶體最大為1.75G,但一旦Java執行緒的堆達到1.75G,那麼就會出現本地堆的Out-Of-Memory錯誤,所以實際上Java堆的最大可使用記憶體為1.5G。
在JVM執行時,可以通過配置以下引數改變整個JVM堆的配置比例
1.Java heap的大小(新生代+老年代)
-Xms堆的最小值
-Xmx堆空間的最大值
2.新生代堆空間大小調整
-XX:NewSize新生代的最小值
-XX:MaxNewSize新生代的最大值
-XX:NewRatio設定新生代與老年代在堆空間的大小
-XX:SurvivorRatio新生代中Eden所佔區域的大小
3.永久代大小調整
-XX:MaxPermSize
4.其他
-XX:MaxTenuringThreshold,設定將新生代物件轉到老年代時需要經過多少次垃圾回收,但是仍然沒有被回收
在上面的配置中,老年代所佔空間的大小是由-XX:SurvivorRatio這個引數進行配置的,看完了上面的JVM堆空間分配圖,可能會奇怪,為啥新生代空間要劃分為三個區Eden及兩個Survivor區?有何用意?為什麼要這麼分?要理解這個問題,就得理解一下JVM的垃圾收集機制(複製演算法也叫copy演算法),步驟如下:
複製(Copying)演算法
將記憶體平均分成A、B兩塊,演算法過程:
1. 新生物件被分配到A塊中未使用的記憶體當中。當A塊的記憶體用完了, 把A塊的存活物件物件複製到B塊。
2. 清理A塊所有物件。
3. 新生物件被分配的B塊中未使用的記憶體當中。當B塊的記憶體用完了, 把B塊的存活物件物件複製到A塊。
4. 清理B塊所有物件。
5. goto 1。
優點:簡單高效。缺點:記憶體代價高,有效記憶體為佔用記憶體的一半。
圖解說明如下所示:(圖中後觀是一個迴圈過程)

對複製演算法進一步優化:使用Eden/S0/S1三個分割槽
平均分成A/B塊太浪費記憶體,採用Eden/S0/S1三個區更合理,空間比例為Eden:S0:S1==8:1:1,有效記憶體(即可分配新生物件的記憶體)是總記憶體的9/10。
演算法過程:
1. Eden+S0可分配新生物件;
2. 對Eden+S0進行垃圾收集,存活物件複製到S1。清理Eden+S0。一次新生代GC結束。
3. Eden+S1可分配新生物件;
4. 對Eden+S1進行垃圾收集,存活物件複製到S0。清理Eden+S1。二次新生代GC結束。
5. goto 1。
預設Eden:S0:S1=8:1:1,因此,新生代中可以使用的記憶體空間大小佔用新生代的9/10,那麼有人就會問,為什麼不直接分成兩個區,一個區佔9/10,另一個區佔1/10,這樣做的原因大概有以下幾種
1.S0與S1的區間明顯較小,有效新生代空間為Eden+S0/S1,因此有效空間就大,增加了記憶體使用率
2.有利於物件代的計算,當一個物件在S0/S1中達到設定的XX:MaxTenuringThreshold值後,會將其分到老年代中,設想一下,如果沒有S0/S1,直接分成兩個區,該如何計算物件經過了多少次GC還沒被釋放,你可能會說,在物件里加一個計數器記錄經過的GC次數,或者存在一張對映表記錄物件和GC次數的關係,是的,可以,但是這樣的話,會掃描整個新生代中的物件, 有了S0/S1我們就可以只掃描S0/S1區了~~~