
快速壓縮跟蹤(fast compressive tracking)(CT)演算法剖析
(快速壓縮跟蹤)
雖然目前有很多種的跟蹤演算法,但是由於姿態的變化、光照的變化、障礙物等原因的存在,導致很多演算法的魯棒性不好。
目前比較主流的跟蹤演算法有兩種,generative tracking algorithms(生成跟蹤演算法)和discriminative algorithms(判別跟蹤演算法)。
生成跟蹤演算法,顧名思義邊生成邊跟蹤。即對這一幀的樣本進行學習,將學習的結果作為下一幀的分類器,達到邊學習跟蹤,邊跟蹤邊學習的效果。這種跟蹤演算法的缺點是在視訊的前幾幀,樣本量較少,因此大部分的演算法要求視訊中目標在視訊的前面變化不大。如果目標變化較大,會產生漂移現象。
判別演算法認為跟蹤就是一個二分類器的問題,其目的是要找到一個將目標從背景中區分出的邊界。但是這種演算法只用了一個正樣本和少量的負樣本來跟新分類器。當特徵模板含有噪聲或者位置偏離時,便會出現漂移現象。
作者的演算法:
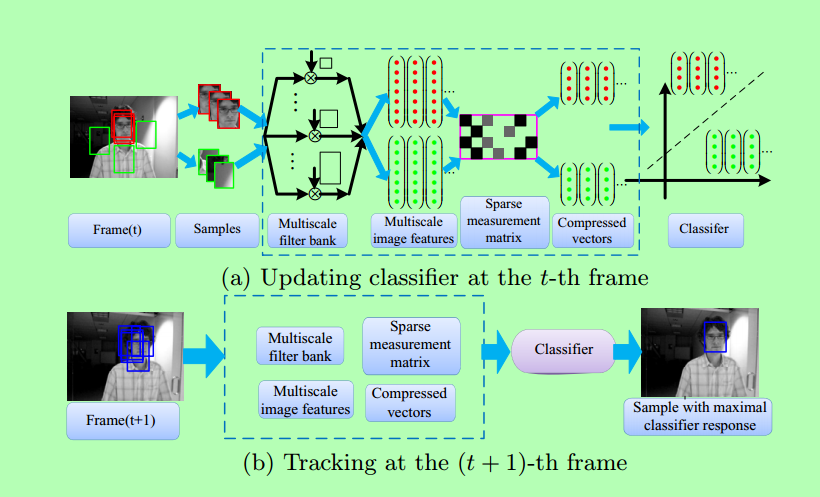

作者論文中主要步驟如下:
1、獲取目標區域特徵
為了獲取影象的多尺度特徵表達,常常將輸入圖片與不同空間的高斯濾波器進行卷積。而在實際的運用過程中,高斯濾波器的運算量較大,所以一般採用矩形框代替高斯濾波器。經證明,這種代替不會影響特徵檢測的效能,而且其還能夠極大的加快檢測的速度。
對於一個W*H的樣本,矩形框的選取方法如下:
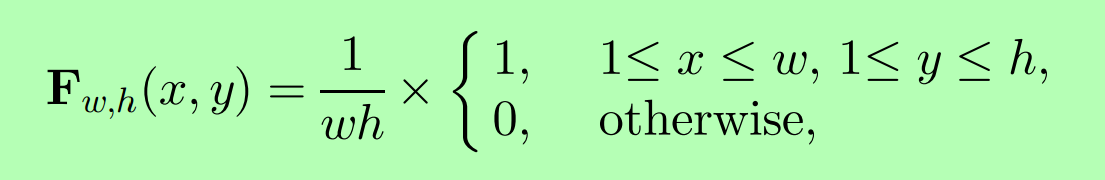
這裡的w和h分別代表矩形框的的width和height。
將這些矩形框分別和輸入影象進行卷積的效果如下:
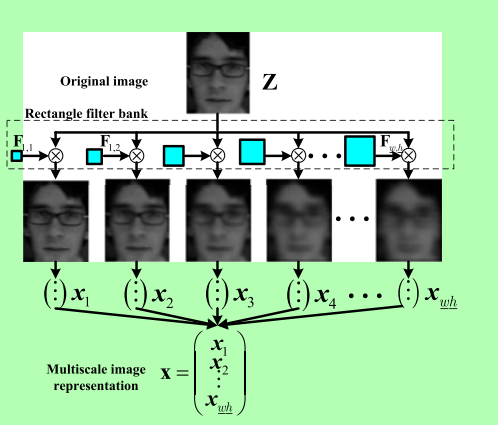
每一個輸入圖片(W*H)和不同大小的矩形框進行卷積的結果的到的仍舊是一個(W*H)的矩陣,但是為了方便將這些特徵進行融合整理,將這個(W*H)的矩陣轉換為一個含有(W*H)元素的列向量。而一個輸入的樣本圖片共有(w*h)個卷積結果,將這(w*h)個列向量連線,就變成了一個含有(w*h)2個元素的列向量。這個列向量的長度一般可以達到106~1010。對於如此高維的特徵,顯然會帶來相當大的計算量,故作者找到了一種很好的降維方法。
2、獲取稀疏測量矩陣
壓縮感知的理論指出,對於一個可壓縮的訊號,例如原始圖片或者視訊,一小部分隨機生成的線性資料可以最大程度的保留原訊號中的顯著資訊,並且能夠從這一小部分隨機訊號將原訊號很好的復現。壓縮感知理論中還有一個比較專業的名次來形容前面所說的“可壓縮訊號”——K-sparse 訊號。
有了這個理論作為依託,那麼我們就可以先獲取目標的複雜高維特徵,再用壓縮感知的理論將特徵進行降維。作者採用的方法就是用稀疏隨機測量矩陣(R)將原訊號進行降維。顯然,對於任意的K-sparse訊號,我們都希望這個稀疏矩陣R能夠將其中的顯著資訊提取出來,並且將這個K-sparse訊號從高維對映到低維空間。
那麼,如何尋找這個稀疏矩陣R,使其能夠滿足我們的要求。
實際上,要尋找這個稀疏矩陣,必須滿足一個性質,即“約束等距性”。
一個典型的滿足約束等距性的隨機稀疏矩陣就是高斯隨機矩陣。

經證明,當ρ=1、3時,這個矩陣是滿足約束等距性的。另外,注意到當ρ=3時,有三分之二的資料是0,因此不需要計算。
將這個m*n的稀疏矩陣與原高維向量(m維)相乘,可得到一個低維向量(n維)。這就是就行降維的結果。
3、用稀疏測量矩陣對特徵進行降維處理
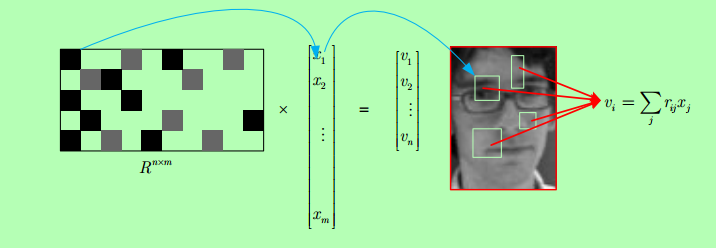
從圖中可以看出隨機稀疏矩陣對高維向量進行降維的過程。圖中稀疏矩陣中黑色的為正數,灰色為負數,白色為0。大致可以看出這個稀疏矩陣是非常稀疏的,非零項較少,明顯可以減少資料處理量。而降維後的向量v,其中的每個元素是向量x中對應R非零項的和,其包含的是多個區域性資訊的和。
4、用貝葉斯分類器進行分類
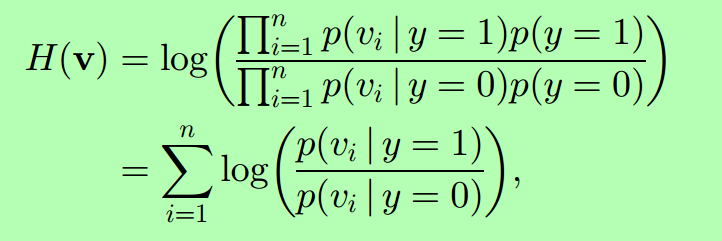
這裡的V就是特徵向量,p(y=1)和p(y=0)分別代表正負樣本的先驗概率。實際上p(y=1)=p(y=0)。經證明,高維隨機向量的隨機對映總是滿足負荷高斯分佈的。所以這裡的p(vi|y=1)和p(vi|y=0)是符合高斯分佈的,其引數為(λ>0,是學習引數):
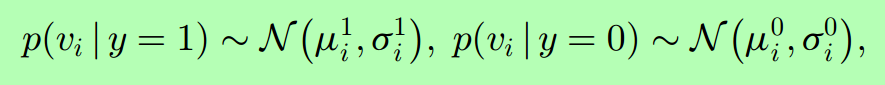
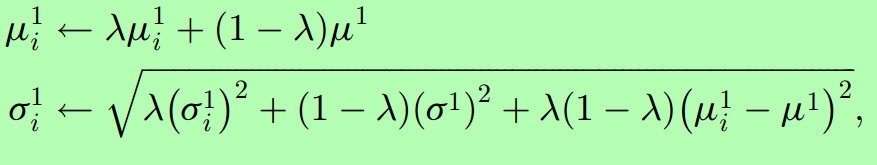
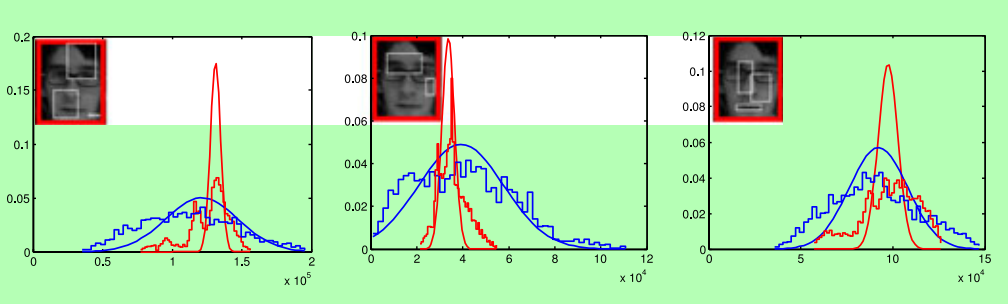
這是三個不同的低維空間特徵所獲得積分圖分佈。
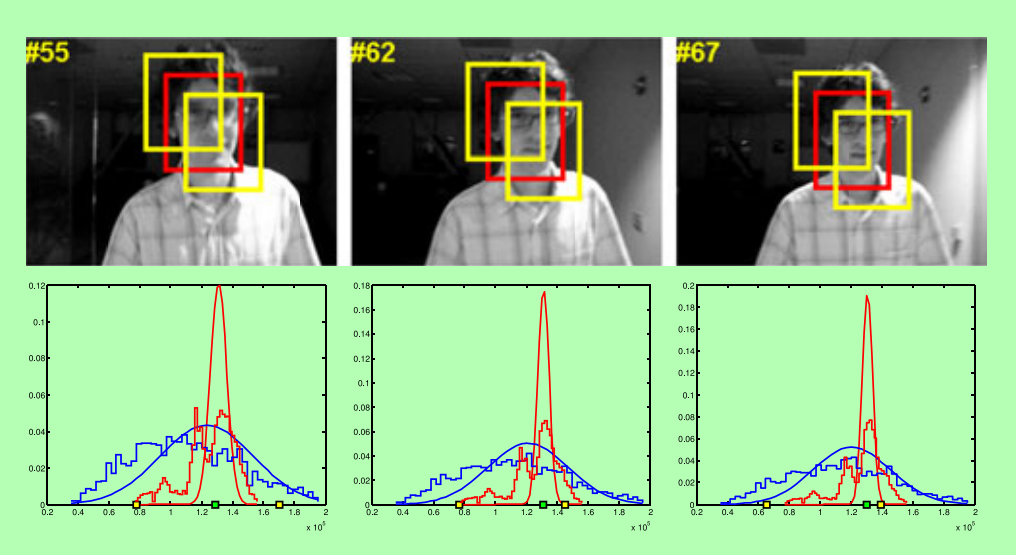
這是衡量正負樣本好壞的積分圖分佈圖。
程式中的步驟:
一、第一幀影象過來:
1、手工的標記需要跟蹤的區域,這個區域是一個矩形框。
2、根據標記區域的資訊,隨機產生矩形框,用來當做Haar特徵的提取模板
3、以當前幀目標區域為中心,以4個畫素點為半徑,取出共計45個正樣本,在以8為內半徑,30為外半徑的圓環中隨機選取50個負樣本。
4、計算原影象的積分圖。
5、根據積分圖和前面所得的Haar特徵提取模板,提取正負樣本的特徵。
6、更新貝葉斯分類器,獲取新的分類器。
二、非第一幀影象過來:
1、以前一幀目標區域為中心,以25個畫素點為半徑,逐個遍歷,可以獲得大約1100個待分類區域。
2、得到這些待分類區域的積分圖,用前面產生的Haar-like特徵模板提取這些待分割槽域的Haar特徵。得到特徵向量。
3、用貝葉斯分類器對這些待分類區域對進行分類,選出最有可能是目標的矩形框,作為當前跟蹤結果。
4、重複步驟一中的3、4、5、6