
網絡卡效能調優
多佇列網絡卡是一種技術,最初是用來解決網路IO QoS (quality of service)問題的,後來隨著網路IO的頻寬的不斷提升,單核CPU不能完全處滿足網絡卡的需求,通過多佇列網絡卡驅動的支援,將各個佇列通過中斷繫結到不同的核上,以滿足網絡卡的需求。
常見的有Intel的82575、82576,Boardcom的57711等,下面以公司的伺服器使用較多的Intel 82575網絡卡為例,分析一下多佇列網絡卡的硬體的實現以及linux核心軟體的支援。
1.多佇列網絡卡硬體實現
圖1.1是Intel 82575硬體邏輯圖,有四個硬體佇列。當收到報文時,通過hash包頭的SIP、Sport、DIP、Dport四元組,將一條流總是收到相同的佇列。同時觸發與該佇列繫結的中斷。

圖1.1 82575硬體邏輯圖
2. 2.6.21以前網絡卡驅動實現
kernel從2.6.21之前不支援多佇列特性,一個網絡卡只能申請一箇中斷號,因此同一個時刻只有一個核在處理網絡卡收到的包。如圖2.1,協議棧通過NAPI輪詢收取各個硬體queue中的報文到圖2.2的net_device資料結構中,通過QDisc佇列將報文傳送到網絡卡。

圖2.1 2.6.21之前核心協議棧

圖2.2 2.6.21之前net_device
3. 2.6.21後網絡卡驅動實現
2.6.21開始支援多佇列特性,當網絡卡驅動載入時,通過獲取的網絡卡型號,得到網絡卡的硬體queue的數量,並結合CPU核的數量,最終通過Sum=Min(網絡卡queue,CPU core)得出所要啟用的網絡卡queue數量(Sum),並申請Sum箇中斷號,分配給啟用的各個queue。
如圖3.1,當某個queue收到報文時,觸發相應的中斷,收到中斷的核,將該任務加入到協議棧負責收包的該核的NET_RX_SOFTIRQ佇列中(NET_RX_SOFTIRQ在每個核上都有一個例項),在NET_RX_SOFTIRQ中,呼叫NAPI的收包介面,將報文收到CPU中如圖3.2的有多個netdev_queue的net_device資料結構中。
這樣,CPU的各個核可以併發的收包,就不會應為一個核不能滿足需求,導致網路IO效能下降。
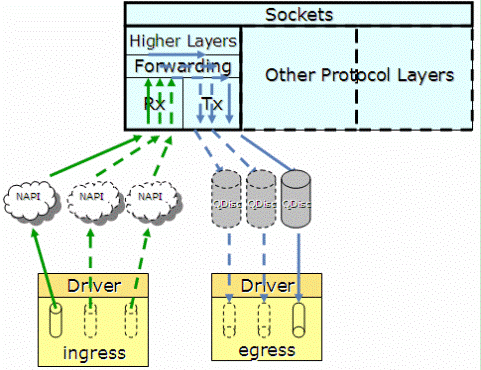
圖3.1 2.6.21之後核心協議棧

圖3.2 2.6.21之後net_device
4.中斷繫結
當CPU可以平行收包時,就會出現不同的核收取了同一個queue的報文,這就會產生報文亂序的問題,解決方法是將一個queue的中斷繫結到唯一的一個核上去,從而避免了亂序問題。同時如果網路流量大的時候,可以將軟中斷均勻的分散到各個核上,避免CPU成為瓶頸。

圖4.1 /proc/interrupts
5.中斷親合糾正
一些多佇列網絡卡驅動實現的不是太好,在初始化後會出現圖4.1中同一個佇列的tx、rx中斷繫結到不同核上的問題,這樣資料在core0與core1之間流動,導致核間資料互動加大,cache命中率降低,降低了效率。

圖5.1 不合理中斷繫結
linux network子系統的負責人David Miller提供了一個指令碼,首先檢索/proc/interrupts檔案中的資訊,按照圖4.1中eth0-rx-0($VEC)中的VEC得出中斷MASK,並將MASK
寫入中斷號53對應的smp_affinity中。由於eth-rx-0與eth-tx-0的VEC相同,實現同一個queue的tx與rx中斷繫結到一個核上,如圖4.3所示。

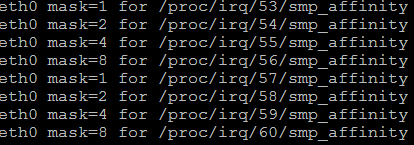
圖4.2 set_irq_affinity
圖4.3 合理的中斷繫結
set_irq_affinity指令碼位於http://mirror.oa.com/tlinux/tools/set_irq_affinity.sh。
6.多佇列網絡卡識別
#lspci -vvv
Ethernet controller的條目內容,如果有MSI-X && Enable+ && TabSize > 1,則該網絡卡是多佇列網絡卡,如圖4.4所示。
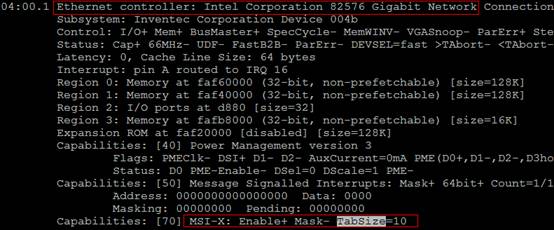
圖4.4 lspci內容
Message Signaled Interrupts(MSI)是PCI規範的一個實現,可以突破CPU 256條interrupt的限制,使每個裝置具有多箇中斷線變成可能,多佇列網絡卡驅動給每個queue申請了MSI。MSI-X是MSI陣列,Enable+指使能,TabSize是陣列大小。