
Elasticsearch聚合 之 Histogram 直方圖聚合
Elasticsearch支援最直方圖聚合,它在數字欄位自動建立桶,並會掃描全部文件,把文件放入相應的桶中。這個數字欄位既可以是文件中的某個欄位,也可以通過指令碼建立得出的。
桶的篩選規則
舉個例子,有一個price欄位,這個欄位描述了商品的價格,現在想每隔5就建立一個桶,統計每隔區間都有多少個文件(商品)。
如果有一個商品的價格為32,那麼它會被放入30的桶中,計算的公式如下:
rem = value % interval
if (rem < 0) {
rem += interval
}
bucket_key = value - rem通過上面的方法,就可以確定文件屬於哪一個桶。
不過也有一些問題存在,由於上面的方法是針對於整型資料的,因此如果欄位是浮點數,那麼需要先轉換成整型,再呼叫上面的方法計算。問題來了,正數還好,如果該值是負數,就會出現計算出錯。比如,一個欄位的值為-4.5,在進行轉換整型時,轉換成了-4。那麼按照上面的計算,它就會放入-4的桶中,但是其實-4.5應該放入-6的桶中。
min_doc_count過濾
聚合的dsl如下:
{ "aggs" : { "prices" : { "histogram" : { "field" : "price", "interval" : 50 } } } }
得到的資料為:
{ "aggregations": { "prices" : { "buckets": [ { "key": 0, "doc_count": 2 }, { "key": 50, "doc_count": 4 }, { "key": 100, "doc_count": 0 }, { "key": 150, "doc_count": 3 } ] } } }
上面的資料中,100-150是沒有文件的,但是卻顯示為0.如果不想要顯示count為0的桶,可以通過min_doc_count來設定。
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"min_doc_count" : 1
}
}
}
}這樣返回的資料,就不會出現為0的了。
{
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 50,
"doc_count": 4
},
{
"key": 150,
"doc_count": 3
}
]
}
}
}extend_bounds,指定最小值和最大值邊界
預設情況下,ES中的histogram聚合起始都是自動的,比如price欄位,如果沒有商品的價錢在0-5之間,0這個桶就不會顯示。如果最便宜的商品是11,那麼第一個桶就是10.
可以通過設定extend_bounds強制規定最小值和最大值,但是要求必須min_doc_count不能大於0,不然即便是規定了邊界,也不會返回。

另外需要注意的是,如果規定的extend_bounds.min要大於文件中的最小值,那麼就會按照文件中的最小值來(extend_bounds.max也是如此)。
比如下面的這個例子,規定的extend_bounds.min和max分別是40和50,但是文件中含有比40還要小的資料,因此桶的定義仍然是按照文件中的資料來。
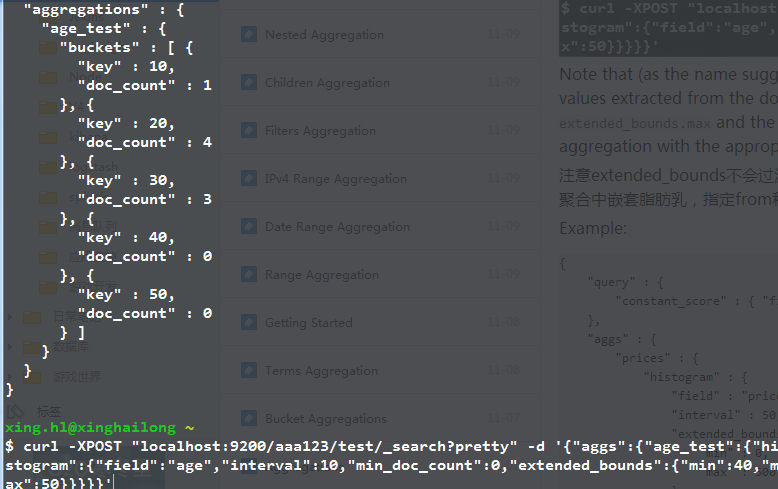
order排序
排序大同小異,可以按照_key的名字排序:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_key" : "desc" }
}
}
}
}也可以按照文件的數目:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_count" : "asc" }
}
}
}
}或者指定排序的聚合:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "price_stats.min" : "asc" }
},
"aggs" : {
"price_stats" : { "stats" : {} }
}
}
}
}keyed設定返回的方式
正常返回的資料如上面所示,是按照陣列的方式返回。如果要按照名字返回,可以設定keyed為true
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"keyed" : true
}
}
}
}那麼返回的資料就為:
{
"aggregations": {
"prices": {
"buckets": {
"0": {
"key": 0,
"doc_count": 2
},
"50": {
"key": 50,
"doc_count": 4
},
"150": {
"key": 150,
"doc_count": 3
}
}
}
}
}預設的值
預設值通過MissingValue設定:
{
"aggs" : {
"quantity" : {
"histogram" : {
"field" : "quantity",
"interval": 10,
"missing": 0
}
}
}
}