
資料探勘實踐與我的想法之特徵工程
從一個最近的天池資料探勘比賽,記錄部分特徵工程實踐內容。
比賽連結 商鋪定位
本人渣渣,排名TOP21。
本部落格採用二分類XGBOOST模型,同時涉及部分的多分類模型。重點介紹業務特徵,對於一些科技特徵,就私藏了。
簡單分析
比賽資料給了三部分:使用者歷史紀錄集、商場商鋪資料集、測試集。
這裡已經將前兩個資料集合並,檢視資料:
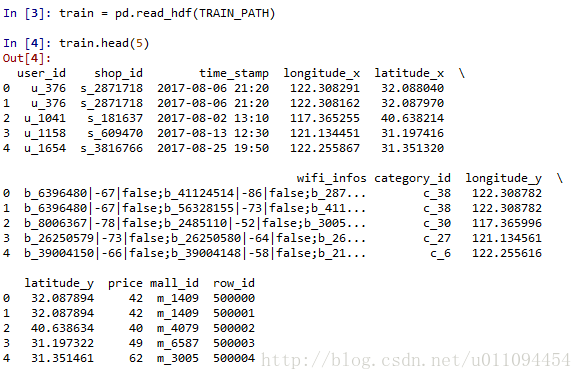
資料看上去只有100w,但後面特徵提取一定會增加大量資料。抽取某個商場mall,做簡單分析。
經緯度分析
對於定位,我們肯定先想到使用經緯度。由於商場可能樓層很高,於是我們先看下有多少店鋪的經緯度是不重複的,

再檢視部分商店每位顧客的分佈,圖來自比賽群共享,
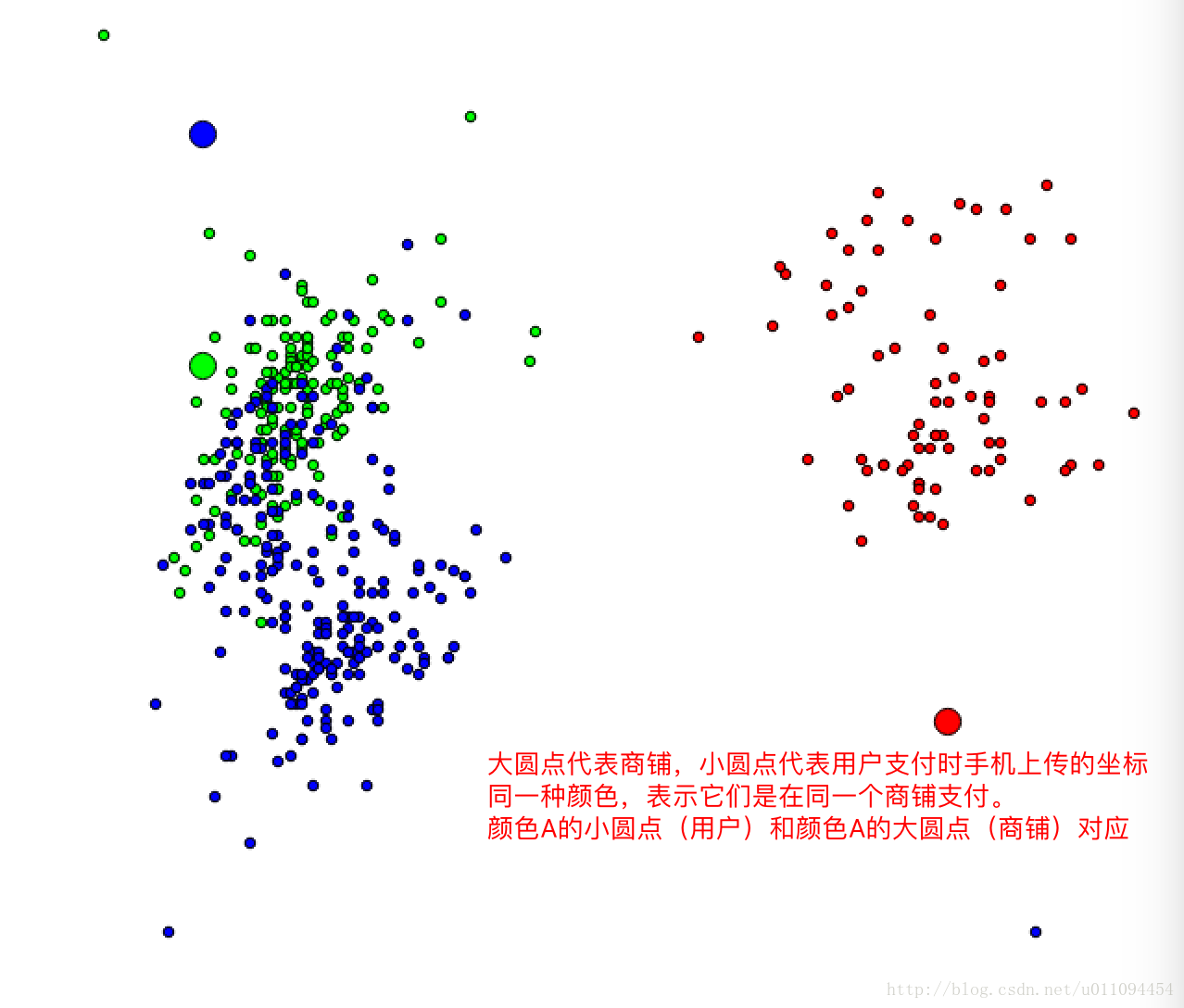
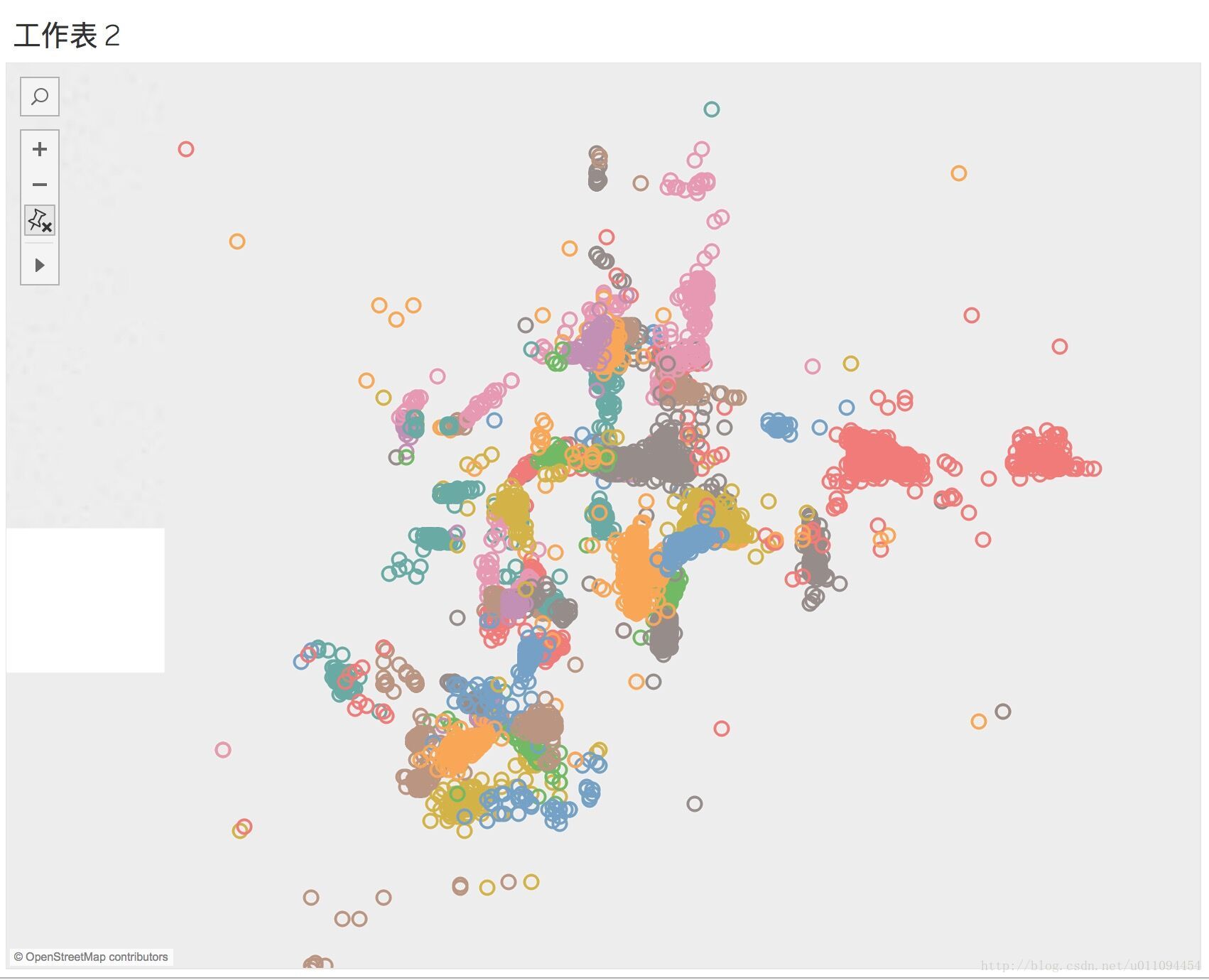
這兩張圖展示的使用者位置和店鋪位置相當清晰,似乎使用經緯度就可以做出基本的區分。
寫一個利用弧度計算兩個經緯度距離的函式,
#獲得經緯度歐式距離#預設地球半徑
R = 6378137
#使用者行為發生位置與店鋪位置的距離
def tcd_produceDistance(latitude1, longitude1,latitude2, longitude2):
radLat1 = np.radians(latitude1)
radLat2 = np.radians(latitude2)
a = radLat1-radLat2
b = np.radians(longitude1)-np.radians(longitude2)
return 統計使用者與店鋪的距離,這裡拿一個商場來統計,
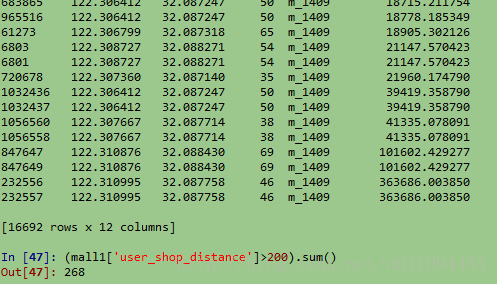
可以看到,有超過200條記錄他距店鋪的距離超過了200米,將這些距離全部轉為200m,輸出可以看到:
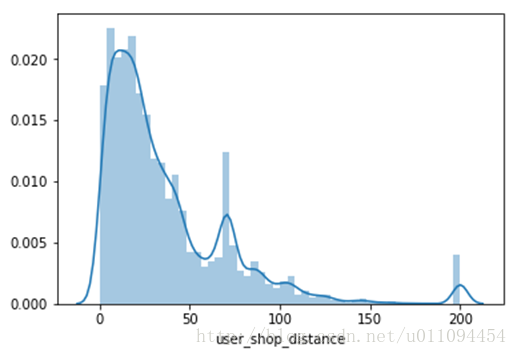
距離集中在0~50,實際超過100m的就在少數,統計也只有900個。不符合實際情況,是否需要刪除呢?不,後面會將每個店鋪的交易距離做聚類,並提取相關特徵。
WiFi資訊分析
從全部資料中可以看到,WiFi資訊的格式為:
b_6396480|-67|false;b_41124514|-86|false;b_28723327|-90|false;
解釋:以分號隔開的WIFI列表。對每個WIFI資料包含三項:b_6396480是脫敏後的bssid,-67是signal強重點內容度,數值越大表示訊號越強,false表示當前使用者沒有連線此WIFI(true表示連線)。
以此寫一個WiFi資訊提取的方法,
def get_shop_wifi_bssid(mall):
#WiFi切片
result = []
for i in mall.index:
slist = mall.loc[i,'wifi_infos'].split(';')
for f in slist:
j = f.split('|')
j.append(mall.loc[i,'shop_id'])
j.append(mall.loc[i,'row_id'])
result.append(j)
result = pd.DataFrame(result,columns=['bssid','power','isconnect','shop_id','row_id'])WiFi資訊的使用對每一位剛開始做比賽的同學都很迷茫,查詢很多關於室內WiFi定位的資料,都是利用KNN、SVM、決策樹等方法做的,論文提到其中KNN的做法效果最好,但對於這個比賽是否是這樣呢?
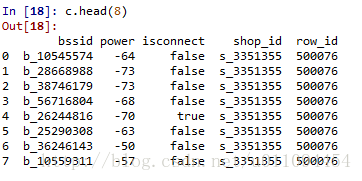
這是提取出來的WiFi,這只是一條記錄裡一個商店擁有的WiFi資訊,用groupby方法可以提取關於這個商店的所有WiFi資訊,並“加工”成特徵。看到上面的WiFi資訊,很自然的一個思路是,是否有些WiFi是大型WiFi或是隻出現一次的等的噪聲WiFi呢?直接groupby檢視下,

不僅可以知道這個商場WiFi連線最多店鋪的只有20個,還可以看到有部分WiFi的路由器bssid是連續的,查閱資料可以知道商場的路由器並不是只有一個,是由多個路由器分佈成的,於是商場在採購這些路由器時就可能是同意批次連續的號了。當然同一個店鋪也可能有連續bssid的路由器。上面的資訊就可以提取相當好的特徵,而WiFi的特徵提取遠不止如此,這個比賽的分數就靠WiFi特徵了。
選擇模型
模型的選擇決定了需要提取什麼樣的特徵,這道題可以選擇多分類,也可以選擇二分類,還有比賽群裡強大的三分類。
對於多分類來說,全部店鋪有8700多個,WiFi數量更是爆炸,只能分mall進行。具體的多分類模型可以採用KNN、XGBOOST等,提取的特徵當然是WiFi資訊和經緯度資訊了。比賽群裡分享的XGBOOST多分類僅60行程式碼,過濾了出現20次以下的WiFi,剩下的WiFi與經緯度一起進行訓練,得到了0.9072的高分。本人自己寫的KNN遠沒有這麼高。
本部落格重點介紹二分類思想,因為二分類思想可以提取的特徵實在是太多了。可以將多分類比作從出發地猜目的地在哪,而二分類是已經給出有可能的目的地,猜這個目的地是不是真實的,選擇概率最大的。顯而易見,多分類提取的特徵只是出發地的,而二分類提取的特徵是出發地和目的地都可以有,且還有更多兩者相關聯的特徵。
多分類比較好理解,而二分類在這裡是怎麼實現的呢?

首先,真正的訓練集是將訓練集分為兩部分的如圖的下一部分,上一部分為下面真正的訓練集提供樣本和特徵。這裡的樣本sample是指正負樣本,負樣本為真正的訓練集裡每條記錄可能的目標(可以有很多個),正樣本是指這條記錄真正的目標;特徵feature指該條記錄裡的“屬性”:使用者、經緯度、WiFi資訊等經過加工聯絡得到的“新的屬性”。這裡真正的訓練集是有0-1標籤label的,代表是否是真的記錄。
再用同樣的方法在整個訓練集裡提取特徵給測試集,這裡的測試集代表了上面所說的“真正的訓練集”,提取的樣本和特徵是在整個訓練集裡找。
於是可以得到如下的真正的訓練集和測試集:
當然特徵不可能這麼點。這樣就是我們所熟悉的二分類了,直接扔進模型裡試試。
業務特徵提取
這裡說的業務特徵也就是邏輯特徵,個人解釋為可以講出道理的特徵,如此條記錄裡WiFi的最大訊號強度等,是不需要進過統計學方法如Log、Log1p等處理的,而對一般分類決策樹的模型這樣的處理方式也沒有用處,但在多分類如KNN裡還是需要對資料做一個標準化、歸一化等。
特徵提取部分是在樣本選擇之後進行的,樣本選擇可以是該條記錄裡的WiFi曾經連線過的所有商店、使用者曾去過的所有商店等,這裡不多贅述。
提取完負樣本後得到訓練集如下:

在複雜事物自身包含的多種矛盾中,每種矛盾所處的地位、對事物發展所起的作用是不同的,總有主次、重要非重要之分,其中必有一種矛盾與其它諸種矛盾相比較而言,處於支配地位,對事物發展起決定作用,這種矛盾就叫做主要矛盾。這就是唯物辯證法。
在這些未加工的特徵屬性中,按照重要性排序可以得到:
WiFi:是本次大賽的主題,當然是最重要的特徵。研究統計WiFi特徵,聯絡交叉進行提取,並從各個方面進行建模。(只用WiFi便可以得到高分)
商店:單單是商店,沒什麼特徵可以提取,但是當商店與WiFi等的使用者資訊相結合,提取的特徵是非常多的,在WiFi的基礎上對其進行建模。
經緯度:是與WiFi資訊差不多的性質,但是卻並不比WiFi資料有效。可以從從微觀角度建模。
時間:各種比賽中,時間都不會單獨提取的,是與其他特徵交叉組合的重要特徵。
使用者:在這裡的使用者資訊是比較少的,但還是可以根據使用者的不同行為,從微觀、個性化角度進行建模。
一階特徵
一階特徵是指只從一個屬性裡找的特徵,並沒有與其他特徵有交叉。宣告:這些提取的特徵不是全部都是“有效的”,但是卻“應該”試一試。
該條記錄特徵
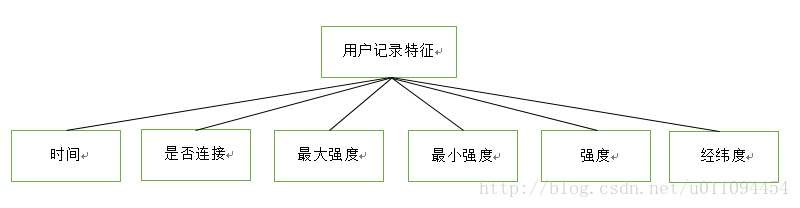
店鋪特徵
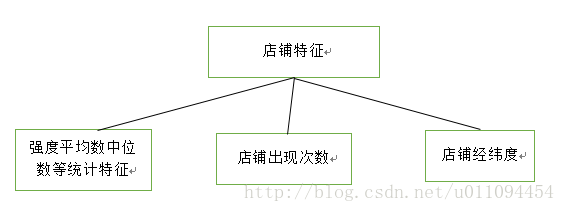
二階交叉組合特徵
在二階特徵以及以上的特徵提取中,需要注意目標物件。在本題中,目標物件是shop_id,還有category_id與price也屬於目標物件。源物件也可以是user_id、row_id、bssid等,從源物件出發來預測目標物件為“正”的概率時,需要提取的比例等的統計類特徵應該是在”目標物件“在”源物件“中的所佔的比例。一般很容易想到的都是”源物件“在”目標物件“中所佔的比例,其實這樣提取也是可以的,但在邏輯上變成了”目標物件“在預測”源物件“了,各中的邏輯需要慢慢體會,至於那個比較好還是要結合問題情況。如這樣兩個特徵:
1.使用者在這個商店歷史記錄中出現過的比例;
2.這個商店在使用者所有去過的商店中所佔的比例。
這兩個物件就是相反的,前者以商店為中心,後者以使用者為中心。
使用者WiFi與店鋪歷史WiFi
使用者WiFi與店鋪歷史WiFi這兩者的交叉特徵是非常重要的特徵,這兩者的聯絡也可以提取到很多特徵,如圖為提取的部分“有道理”的特徵,圖上是本人提取的特徵,當然實際提取了很多,這裡委實放不下。
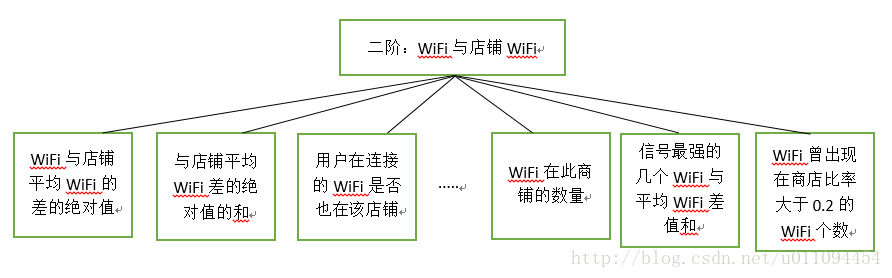
在思考WiFi與店鋪的關係時,一定會想到WiFi的強度與這個WiFi在這個店鋪的歷史強度的關係,這個歷史強度在多分類中可以直接使用所有的此WiFi歷史強度,這麼大數量的特徵顯然是不可取的,但不使用所有歷史資料損失的資訊相當大,也因此沒有足夠好的特徵,在本道賽題是弱勢的。
於是找到所有店鋪歷史WiFi的規律是找到主要矛盾的關鍵點。
基本店鋪歷史WiFi首先可以想到
1.平均WiFi、中位數WiFi、眾數WiFi
2.WiFi在這個店鋪出現過的次數與比率
3.每條歷史紀錄中WiFi的強度的排名
4.哪些WiFi曾經在這個店鋪connect過由當前記錄的WiFi資訊與這些店鋪歷史WiFi的資訊做“對比”。最自然的想到的特徵肯定有
1.當前WiFi強度與對應店鋪歷史強度的差--記為wifi_nn
2.wifi_nn的和
3.當前所有WiFi中曾出現在這個店鋪的個數
4.當前WiFi比率大於某個值的WiFi個數
5.當前WiFi是否連線過此店鋪
6.當前連線的WiFi是否在此店鋪也被連線過
等等這樣子的特徵貌似並沒有把每個WiFi的等級劃分出來,於是很久WiFi強度、歷史強度、WiFi出現的次數或比率來給WiFi進行“等級劃分”。在上面已經得到的基礎特徵上在進行特徵提取:
1.根據當前WiFi強度排序的wifi_nn特徵展開
2.根據當前WiFi強度排序的前幾位WiFi_nn的和
3.根據店鋪平均WiFi強度排序的wifi_nn特徵展開
4.根據店鋪平均WiFi強度排序的前幾位WiFi_nn的和
5.當前WiFi強度排序位置(1-10)與歷史WiFi強度排序的位置的平均值差的展開
6.每個WiFi的歷史WiFi強度排序的位置展開下面是複賽第一名的部分使用者WiFi與店鋪歷史WiFi特徵:
1. wifi歷史上出現過的總次數、候選shop在其中的佔比
2. 在當前排序位置(如最強、第二強、第三強...)上wifi歷史上出現過的總次數、候選shop在其中的佔比
3. 連線的wifi出現的總次數、候選shop在其中的佔比
(特徵1、2,每條記錄中的10個wifi由強到弱排列,可生成10個特徵。)
4. wifi強度 - 候選shop的歷史記錄中該wifi的平均強度
5. wifi強度 - 候選shop的歷史記錄中該wifi的最小強度
6. wifi強度 - 候選shop的歷史記錄中該wifi的最大強度
(三個wifi強度差值特徵,按照訊號強度由強到弱排列,可生成10個特徵)。最小最大值一直都是特徵提取的重點,當前值與最大最小值之間的差更是值得嘗試的特徵。
下面是複賽第四名的部分使用者WiFi與店鋪歷史WiFi特徵:
1. 當前wifi序列的能量與歷史商店平均能量的方差
2. 當前wifi序列的能量與歷史商店平均能量的差值的標準差
3. 當前wifi序列的能量與歷史商店平均能量的差值的均值
4. 當前wifi序列的能量與歷史商店平均能量序列的cos相似度
5. 當前wifi序列中大於歷史商店平均能量的數量
6. 當前wifi序列中大於歷史商店平均能量的數量佔當前wifi序列與歷史商店wifi序列相同wifi個數的比例
7. 當前序列wifi存在在商店歷史中的最小能量
8. 當前wifi序列中小於歷史商店平均能量的數量
9. 當前wifi序列的能量與歷史商店平均能量的帶有權重的差值
10. 當前序列wifi的能量與歷史商店出現頻率大於0.5的wifi的平均能量的方差
11. 在result中每個row_id出現次數最多的10個wifi的歷史在商店中的平均能量與當前序列的能量差
12. 在result中每個row_id出現次數最多的10個wifi的歷史在商店中
13. wifi出現在當前序列且出現在商店歷史中的個數
14. 當前wifi序列中小於歷史商店最小能量的數量
15. 當前wifi序列的能量與商店歷史wifi序列的最小能量的方差
16. 當前wifi序列中大於歷史商店最小能量的數量
17. 當前wifi序列中大於歷史商店最小能量的數量佔相同數量的比例
18. 當前wifi序列與歷史商店最大能量的方差
19. 當前wifi序列的能量與歷史商店最大能量序列的cos相似度
20. 當前wifi序列的能量與歷史商店最大能量的帶有權重的差值
21. 當前wifi序列中大於歷史商店最大能量的數量
22. 當前序列wifi的能量與歷史商店出現頻率大於0.5的wifi的最大能量的方差
23. result中每個row_id出現次數最多的10個wifi的歷史在商店中的最大能量與當前序列的能量差
24. 當前序列中wifi能量大於歷史上這個商店出現過的所有商店的能量的次數
25. 當前序列中wifi能量大於歷史上這個商店出現過的所有商店的能量的次數除以當前序列wifi在歷史上出現的次數
26. 當前序列中的wifi能量與歷史上這個wifi出現過的最大能量的距離
27. 當前序列中的wifi能量與歷史上這個wifi出現過的最大能量的平均距離
28. 當前序列中的wifi能量與歷史上這個wifi出現過的最小能量的平均距離經緯度特徵
解決使用者WiFi與商店WiFi這個主要矛盾後,再來看看次要矛盾——經緯度。使用者所在位置與商店位置也可以組成相當多的特徵。
首先很自然就可以想到
1.使用者和商店的歐式距離。同時統計所有使用者在這個商店的距離,還可以得到
2.最大最小的距離、平均距離、中位數距離等。接著順著這個思路又可以想到
3.使用者的位置與這個歷史平均距離的差距使用者的位置與這個歷史平均距離的差距,這個平均距離與店鋪的經緯度兩者在圖形上是個弧,除去距離還應該想到店鋪歷史記錄的平均經緯度或中位數經緯度是這個店鋪的歷史交易中心點,那麼使用者的位置與這個交易中心的距離也是可取的
4.使用者與店鋪交易中心的距離使用者記錄特徵
在資料量比較少的情況下,這段特徵表現可能不會太好,可能非常稀疏。但是本賽題複賽這段特徵提高了幾個百分點。
使用者記錄特徵肯定是使用者與店鋪、店鋪的某些屬性之間的關係,很自然便可以找到這方面的特徵:
1.使用者去過此店鋪的次數與佔該使用者總次數的比率
2.使用者去過此型別店鋪的次數與佔該使用者總次數的比率
3.使用者去過此價格店鋪的次數與佔該使用者總次數的比率三階交叉特徵
這裡的物件其實只有使用者與店鋪兩個,第三個物件是什麼呢?不能忘記的重要組合特徵就是“時間”!時間不僅可以用來聚類資料,最重要的還可以提取到重要的時間滑窗特徵。舉幾個例子就可以明白什麼叫做時間滑窗:
1.距離當前時間1、7、14、30天的商店熱度
2.在每天不同時間段的商店熱度
3.週末非週末的商店熱度當然還有一些重要的三階時間特徵如:
1.使用者上次在此商店購買過東西距現在的時間