
使用scrapy-deltafetch實現爬蟲增量去重
阿新 • • 發佈:2018-12-30
scrapy-deltafetch簡介
scrapy-deltafetch通過Berkeley DB來記錄爬蟲每次爬取收集的request和item,當重複執行爬蟲時只爬取新的item,實現增量去重,提高爬蟲爬取效能。
Berkeley DB簡介
Berkeley DB是一個嵌入式資料庫,為應用程式提供可伸縮的、高效能的、有事務保護功能的資料管理服務。
主要特點:
- 嵌入式:直接連結到應用程式中,與應用程式運行於同樣的地址空間中,因此,無論是在網路上不同計算機之間還是在同一臺計算機的不同程序之間,資料庫操作並不要求程序間通訊。 Berkeley DB為多種程式語言提供了API介面,其中包括C、C++、Java、Perl、Tcl、Python和PHP,所有的資料庫操作都在程式庫內部發生。多個程序,或者同一程序的多個執行緒可同時使用資料庫,有如各自單獨使用,底層的服務如加鎖、事務日誌、共享緩衝區管理、記憶體管理等等都由程式庫透明地執行。
- 輕便靈活:可以運行於幾乎所有的UNIX和Linux系統及其變種系統、Windows作業系統以及多種嵌入式實時作業系統之下,已經被好多高階的因特網伺服器、桌上型電腦、掌上電腦、機頂盒、網路交換機以及其他一些應用領域所採用。一旦Berkeley DB被連結到應用程式中,終端使用者一般根本感覺不到有一個數據庫系統存在。
- 可伸縮:Database library本身是很精簡的(少於300KB的文字空間),但它能夠管理規模高達256TB的資料庫。它支援高併發度,成千上萬個使用者可同時操縱同一個資料庫
安裝Berkeley DB
# cd /usr/local/src
# wget http://download.oracle.com/berkeley-db/db-4.7.25.NC.tar.gz 安裝bsddb3
(python2.7-env01)# pip install bsddb3安裝scrapy-deltafetch
(python2.7-env01)# pip install scrapy-deltafetch安裝scrapy-magicfields
(python2.7-env01)# pip install scrapy-magicfields配置
在配置檔案setting.py增加如下程式碼:
SPIDER_MIDDLEWARES = {
'scrapy_deltafetch.DeltaFetch': 50,
'scrapy_magicfields.MagicFieldsMiddleware': 51,
}
DELTAFETCH_ENABLED = True
MAGICFIELDS_ENABLED = True
MAGIC_FIELDS = {
"timestamp": "$time",
"spider": "$spider:name",
"url": "scraped from $response:url",
"domain": "$response:url,r'https?://([\w\.]+)/']",
}效果展示
首先設定資料表crawedArticle欄位title_id為主鍵,用來驗證多次爬取某個頁面是否抓取了重複資料。
以專案中東方財富網的爬蟲為例:
不使用去重外掛scrapy-deltafetch測試
第一次執行爬蟲:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl --pdb east此時資料庫成功寫入了爬取到的資料。
第二次執行爬蟲:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl --pdb eastmysql將會出現重複寫入錯誤:

說明爬蟲重複抓取了資料!
使用去重外掛scrapy-deltafetch測試
首先,清空資料表crawedArticle,第一次執行爬蟲:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl east爬蟲執行結束後資料庫寫入15條資料,觀察爬蟲爬取完成後的資訊採集結果如下:
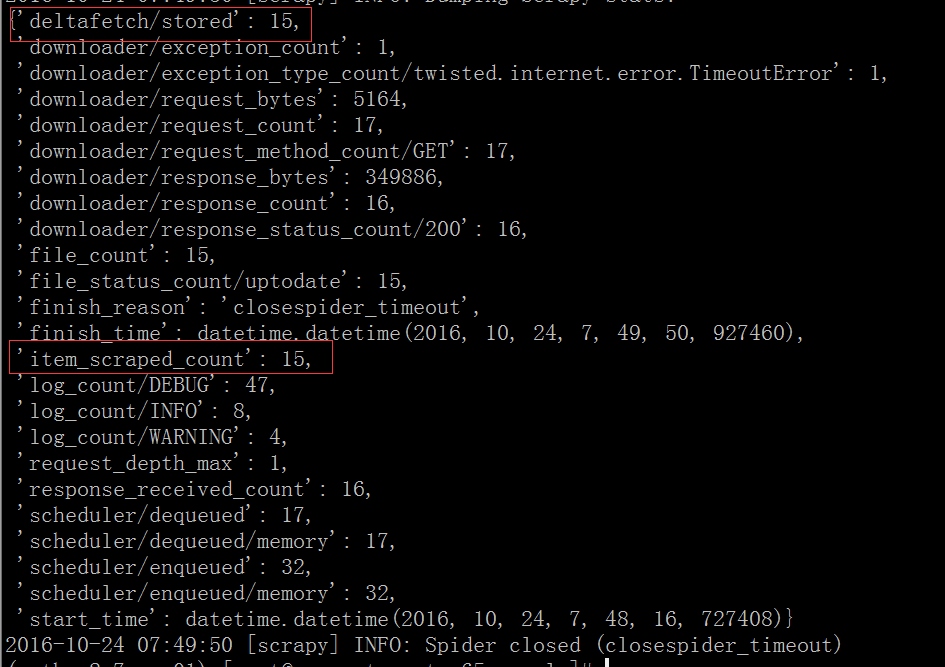
scrapy-deltafetch記錄了爬取的15個item
同時在專案所在跟目錄會生成快取檔案:

第二次執行爬蟲:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl eastmysql並未出現重複寫入錯誤且資訊採集結果如下:
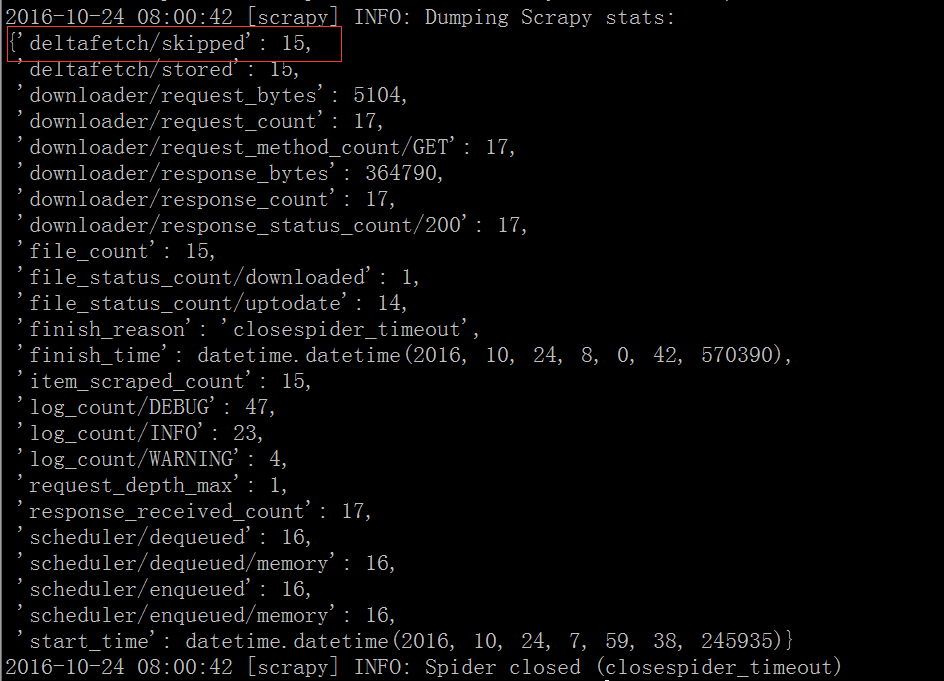
scrapy-deltafetch忽略了之前已經爬取的15個item。
說明使用scrapy-deltafetch並未抓取重複的資料!
重置DeltaFetch
如果想重置某個頁面的爬取資料快取,執行命令:
scrapy crawl spider_name -a deltafetch_reset=1