
有容雲:容器網路那些事兒
編者注:
本文根據7月31日有容雲《Docker Live時代線下沙龍-北京站》嘉賓分享內容整理而成,分享嘉賓杜東明,有容雲高階技術顧問,十年IT經驗,IT行業的全棧工程師。涉足領域包括儲存、網路、備份/容災、伺服器/終端虛擬化、Docker等。擁有豐富的一線客戶經驗,曾幫助工行、建行、光大、國壽、泰康等諸多金融客戶設計其虛擬化基礎架。
我相信,真正拿容器工作或者是去運維一個容器環境,真正在容器上面做生產的時候大家都會遇到的一個話題就是容器網路,所以我今天給大家分享下這個話題,有不同意見的地方歡迎大家共同交流。
為什麼關注容器網路

從容器誕生開始,儲存和網路這兩個話題就一直為大家津津樂道。我們今天這個環境下講網路這個問題,其實是因為容器對網路的需求,和傳統物理、虛擬環境對網路環境需求非常不一樣。虛擬做了很多工作,比如說虛擬路由器虛擬交換機,現在發現容器環境不是那麼好就能夠適配。很重要原因: 虛擬時代幾百個虛擬機器可能就不少了,大不了就幾千個;但容器時代談微服務,一個應用一個龐大的生態系統,那麼多服務,每個服務都有那麼多容器實力,他們在一起構成這麼多生態系統之後,他們的力度要比傳統虛擬機器小得多,他們的離散度也比傳統的虛擬機器要明顯高很多,所以會對網路有著更高的要求。
容器技術發展到今天,容器網路一直髮展比較滯後,不知道大家有沒有這樣的感覺?以前很早的時候就對儲存Docker就釋出了Volume Plugin這樣一個介面。但是網路層面一直沒有一個標準,直到近期才出現了一個叫CNM的規範。所以說它的網路一直髮展比較滯後。這種情況給大量創業公司或者開源組織提供了一個空間,他們開發了各種各樣的網路實現,並且沒有出現一家獨大的狀態,而是有了很多複雜的解決方案,讓客戶無從挑選。
有些客戶感覺SDN很好,把SDN概念引進到容器領域,結果把個問題變得更復雜,所以我們看到大量客戶對容器網路選型非常撓頭。不僅是客戶,方案解決提供商每天也在思考能提供什麼樣的容器網路方案滿足客戶的需求。所以,我們今天把網路重點和大家梳理一下。
容器網路發展簡史

容器網路發展經歷了三個階段。第一個階段是“石器時代”,最早的容器網路模型,就是主機內部的網路,想要把服務暴露出去需要做埠對映,非常原始古老。例如一個主機內有很多Apache容器,每一個Apache要往外拋80的埠,那我怎麼辦?我需要針對第一個容器和主機80埠做對映,第二個和主機81埠做對映,依此類推,到最後發現非常混亂,沒辦法管理。這個東西石器時代的網路模型,基本上沒辦法被企業採用。
後來進化到下一個階段,我們稱之為豪傑輩出的解決方案,非常優秀的比如Rancher基於IPSec的網路實現,比如Flannel基於三層路由的網路實現,包括我們國內也有一些開源專案都在做,後續展開詳談。
時至今日,容器網路出現了雙雄會的格局。一個以Docker領導的和開發的CNM架構,另一個以Google、Kubernetes、CoreOS主導開發的CNI架構。兩家各立山頭,剩下群雄們自己選擇,後面我會具體來談一下這兩個方案。
技術術語
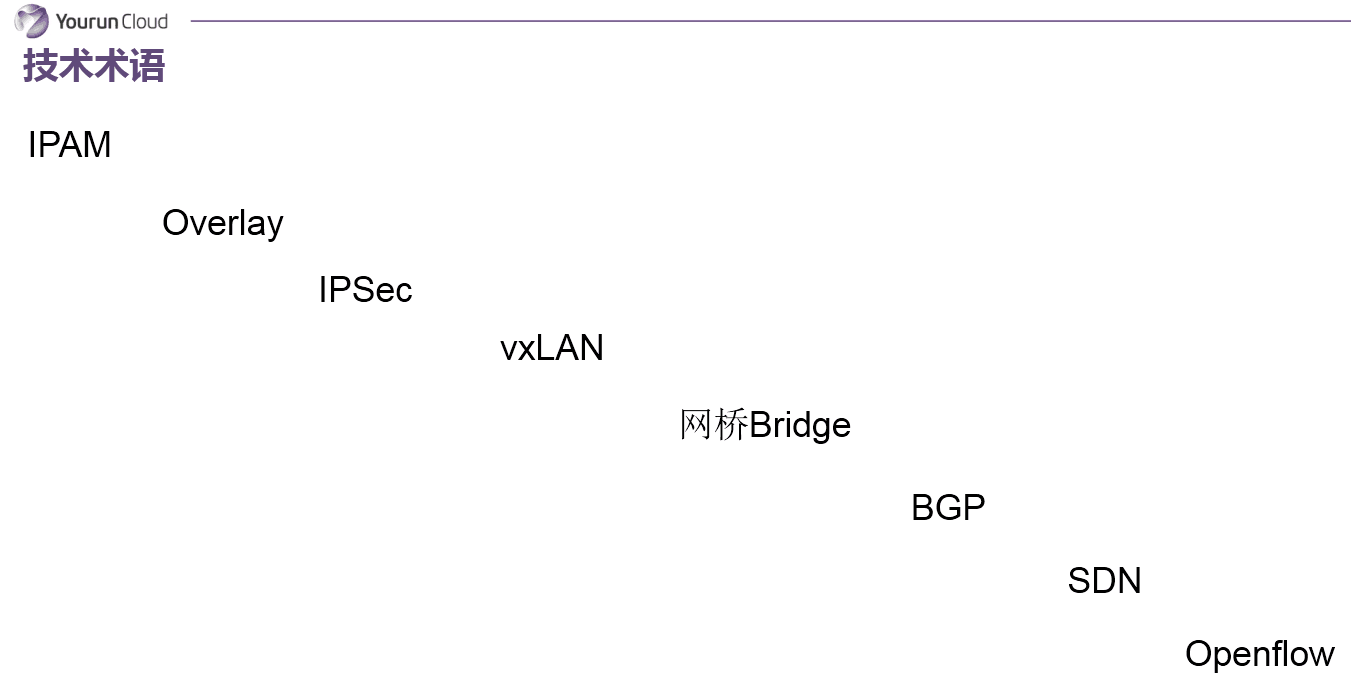
在開始下面話題之前我先做幾個技術術語解釋:
IPAM:IP地址管理;這個IP地址管理並不是容器所特有的,傳統的網路比如說DHCP其實也是一種IPAM,到了容器時代我們談IPAM,主流的兩種方法: 基於CIDR的IP地址段分配地或者精確為每一個容器分配IP。但總之一旦形成一個容器主機叢集之後,上面的容器都要給它分配一個全域性唯一的IP地址,這就涉及到IPAM的話題。
Overlay:在現有二層或三層網路之上再構建起來一個獨立的網路,這個網路通常會有自己獨立的IP地址空間、交換或者路由的實現。
IPSesc:一個點對點的一個加密通訊協議,一般會用到Ovrelay網路的資料通道里。
vxLAN:由VMware、Cisco、RedHat等聯合提出的這麼一個解決方案,這個解決方案最主要是解決VLAN支援虛擬網路數量(4096)過少的問題。因為在公有云上每一個租戶都有不同的VPC,4096明顯不夠用。就有了vxLAN,它可以支援1600萬個虛擬網路,基本上公有云是夠用的。
網橋Bridge: 連線兩個對等網路之間的網路裝置,但在今天的語境裡指的是Linux Bridge,就是大名鼎鼎的Docker0這個網橋。
BGP: 主幹網自治網路的路由協議,今天有了網際網路,網際網路由很多小的自治網路構成的,自治網路之間的三層路由是由BGP實現的。
SDN、Openflow: 軟體定義網路裡面的一個術語,比如說我們經常聽到的流表、控制平面,或者轉發平面都是Openflow裡的術語。
石器時代下容器網路模
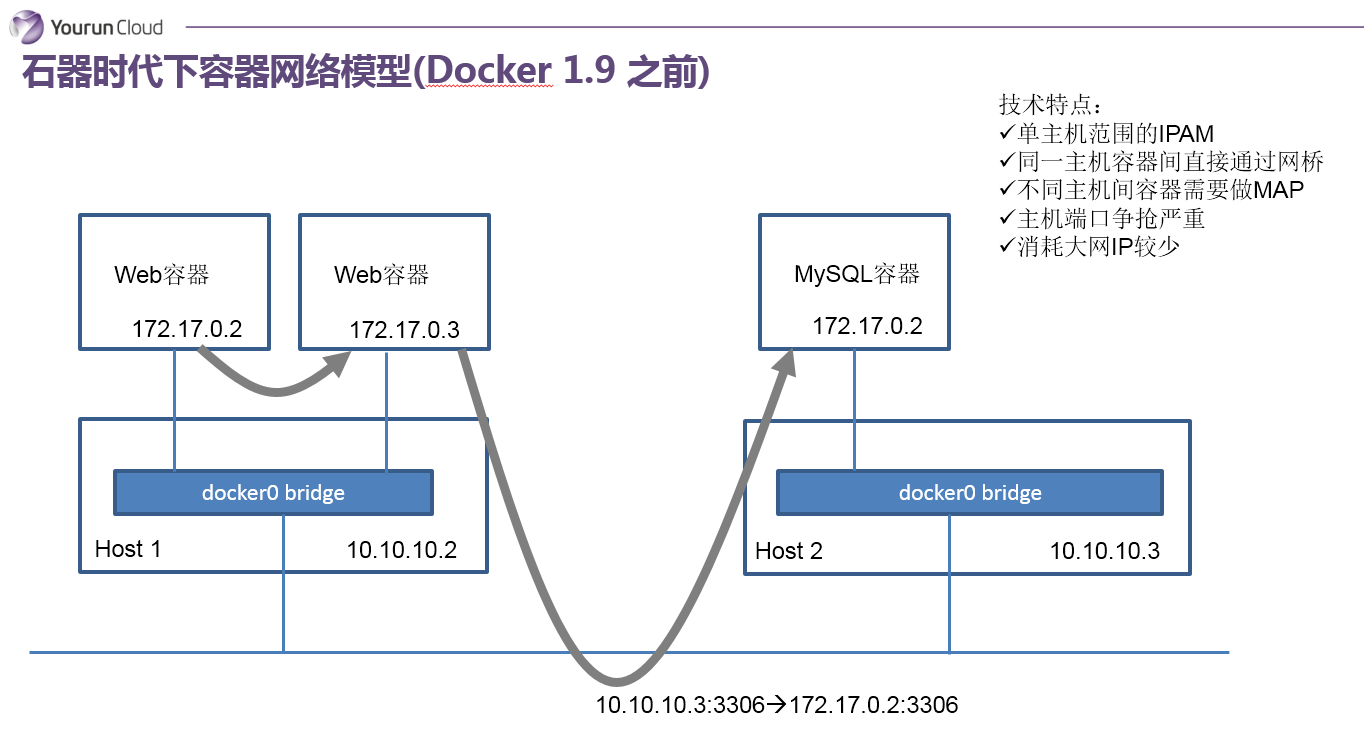
這是石器時代網路模型,我簡單說一下。它是Docker1.9之前的容器網路,實現方式是隻針對單臺主機進行IPAM管理,所有主機上的容器都會連線到主機內部的一個Linux Bridge,叫Docker0,主機的IP它預設會分配172.17網段中的一個IP,因為有Docker0,所以在一個主機上的容器可以實現互聯互通。但是因為IP分配的範圍是基於單主機的,所以你會發現在其他主機上,也會出現完全相同的IP地址。很明顯,這兩個地址肯定沒辦法直接通訊。為了解決這個問題,在石器時代我們會用埠對映,實際上就是NAT的方法。比如說我有一個應用,它有Web和Mysql,分別在不同的主機上,Web需要去訪問Mysql,我們會把這個Mysql的3306埠對映到主機上的3306這個埠,然後這個服務實際上是去訪問主機IP 10.10.10.3 的3306埠,這是過去的石器時代的一個做法。
總結一下它的典型技術特徵:基於單主機的IPAM;主機之內容器通訊實際上通過一個docker0的Linux Bridge;如果服務想要暴露到外部的話需要做NAT,會導致埠爭搶非常嚴重;當然它有一個好處,對大網IP消耗比較少。這是石器時代。
豪傑輩出
Rancher網路
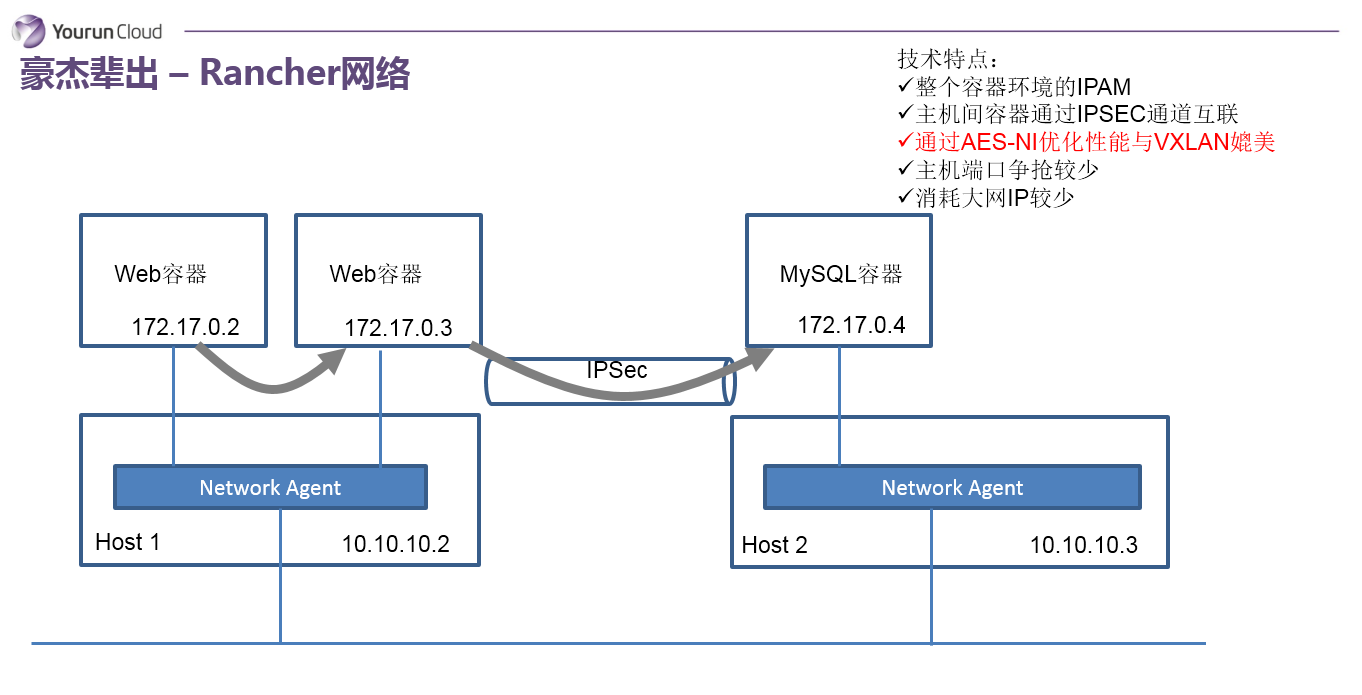
下面進入到豪傑輩出的年代,第一個想講的是Rancher。在石器蠻荒那個年代,Rancher網路解決方案非常讓人眼前一亮。它需要解決兩個大的問題:第一分配一個全域性唯一的IP地址,第二要實現容器跨主機的通訊。首先從第一點它有一個集中資料庫,通過資料庫協調,為資源池中的每一個容器分配一個獨立的IP地址。第二如何實現容器跨主機的通訊,是在每一個主機內部會放一個Agent容器,所有容器都會連線到本機的Agent容器上,這個Agent其實就是一個轉發器,由它負責將資料包封裝並路由到指定的其他主機。比如說172.17.0.3訪問到這個172.17.0.4的時候,首先172.17.0.3容器會把資料包丟到本機的Agent,Agent根據內部的元資料,得知172.17.0.4在其他主機上,那麼Agent會把資料包封裝為IPSec包,通過IPSec傳送到對端主機。當對端主機收到IPSec包後,執行解包操作,再發給本機上對應的容器。這個方法實現的很乾淨很簡單,但它有一個大的問題,就是IPSec的通訊問題,它很重,效率比較低。依據Rancher的說法,這個問題貌似也沒有想象中那麼誇張,在Intel的CPU裡有一種協處理器,能夠處理AES-NI指令,Linux Kernel的IPSec實現能夠使用AES-NI指令來加速IPSec效率,基於此據說IPSec協議可以和VXLAN相媲美。
Rancher網路的特點: 它是全域性的IPAM,保證容器IP地址全域性唯一;主機通訊使用IPSEC;主機埠爭搶不會太嚴重,應用通訊不會佔用主機埠,但是如果你的服務想要最終暴露出來,你還是要對映到主機上;這就是Rancher,它非常簡單非常乾淨,就像Rancher自身一樣開箱即用。
Flannel
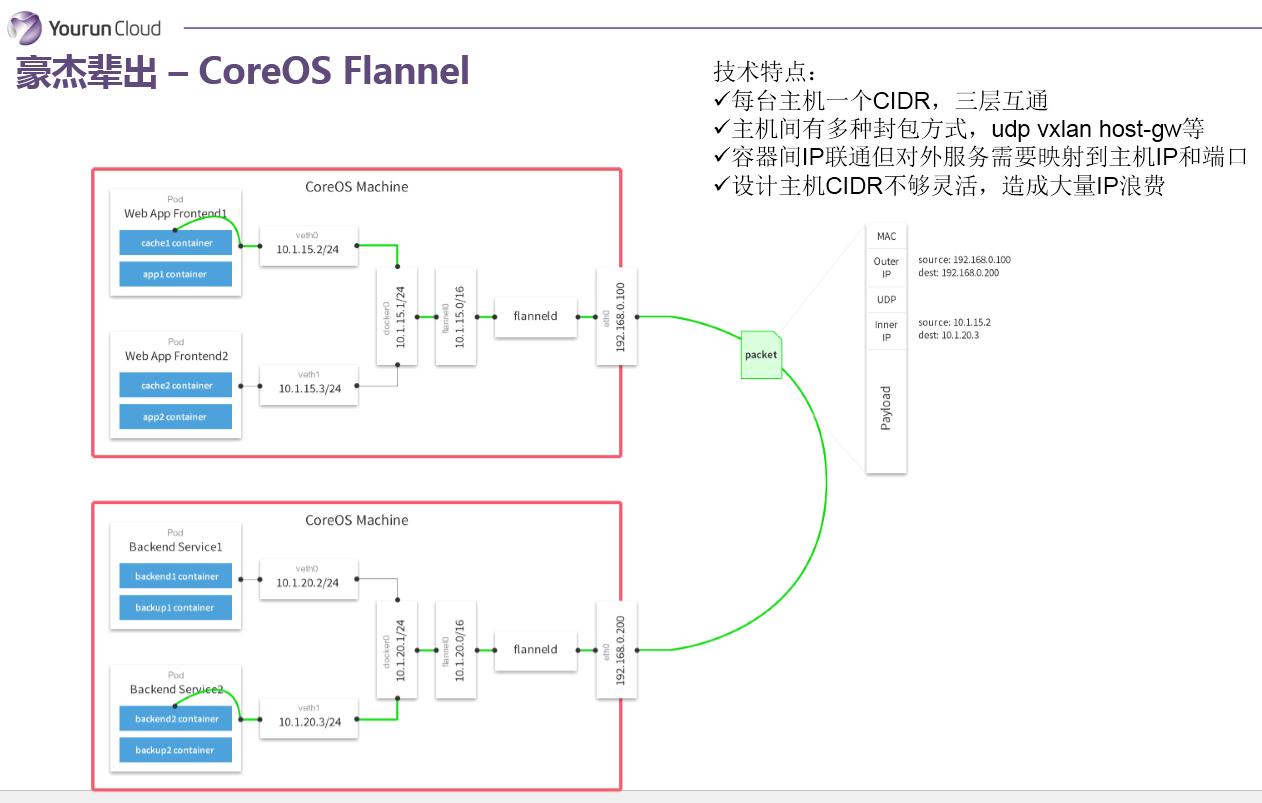
再來看一個網路實現叫Flannel,Flannel是由CoreOS主導並被使用到Kuberenates裡。Flannel同樣需要解決IP地址分配和跨主機通訊兩個問題。地址分配的問題,它使用的是CIDR的方式——個人認為並非很聰明的方法——就是為每個主機分配一個地址段,比如24位掩碼的一個地址段,那就說明這個主機上可以支援254個容器,每一個主機都會分一個子網IP地址段,這是它解決IP地址分配的問題,這個地址段一旦分配給Docker Deamon之後,Docker Demon可以從中分配IP給容器。第二個問題如何實現跨主機的包交換,它採用的做法是通過三層路由:和傳統的做法一樣,所有的容器會被連線到Docker0,在Docker0和主機網絡卡之間被插入一個Flannel0的虛擬裝置,這個虛擬裝置為Flannel帶來很大的靈活性——可以實現不同的封包、隧道協議,比如VXLAN,通過Flannel0裝置將資料包封裝為VxLan的UDP包。也就是說Flannel0是可以做協議適配的,這是Flonnel的特點,它的一個優勢所在。
我再總結一下,Flannel它的每一個主機分配一個地址段,就是分配一個CIDR,然後主機之間可能會有多種封包方式,可以支援udp、vxlan、host-gw等,容器之間IP是可以互相連通的。但是如果一個容器要暴露服務,還是需要對映IP到主機側的。另外,Flannel基於CIDR的設計比較愚蠢,會造成大量的IP地址浪費。
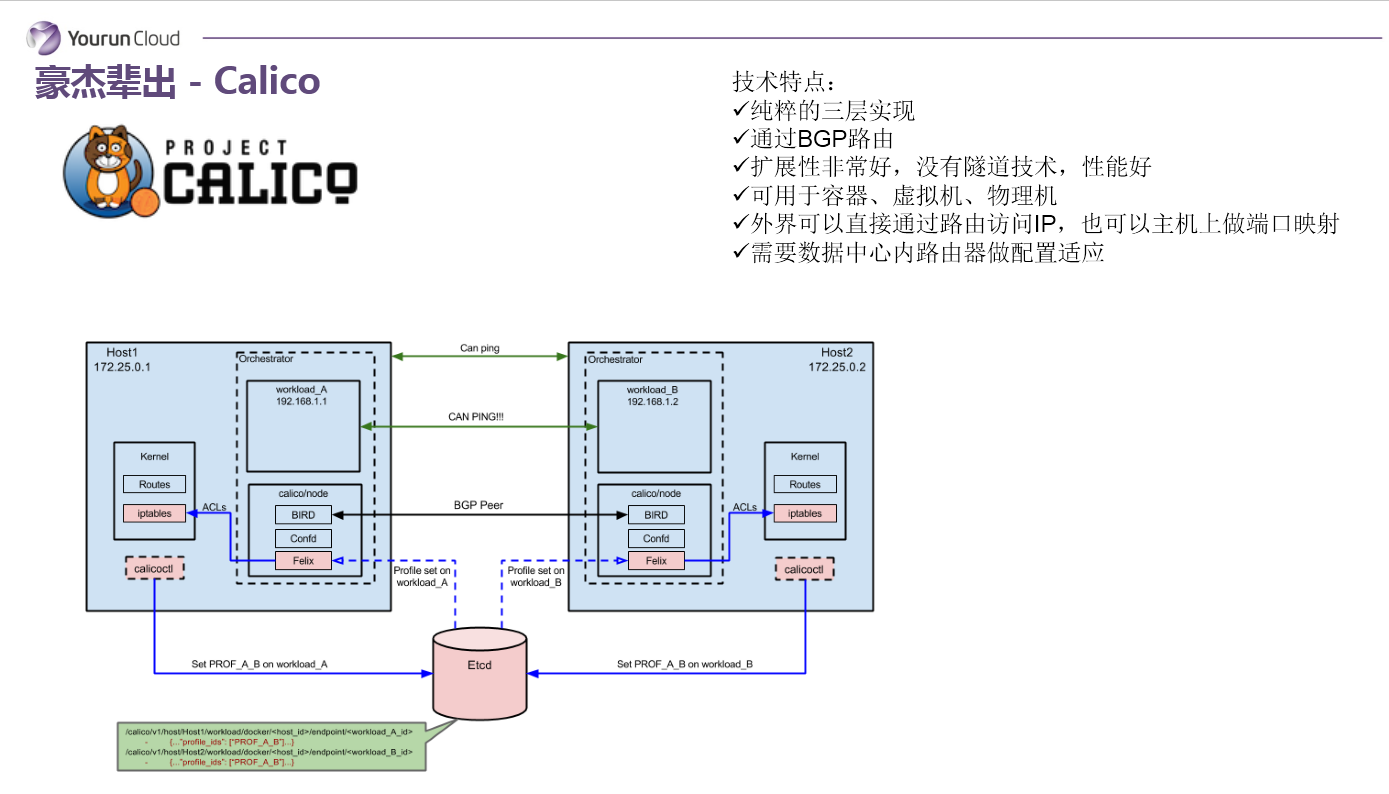
Calico
下一個看Calico,它是比較年輕的專案,但是野心很大,可以用到虛擬機器、物理機和容器環境中。Calico使用的協議是可能一般人都沒有聽說過的BGP協議,而且它是完全基於三層路由的,它沒有二層的概念。所以你在Calico內部能看到大量的由Linux路由構造的路由表,路由表的變更是通過Calico自有的元件管理的。這種做法的好處在於,容器的IP可以直接對外部訪問,可以直接分配到業務IP,而且如果網路裝置支援BGP的話,可以用它實現大規模的容器網路。同時這種實現並沒有使用隧道,沒有NAT,導致沒有效能的損耗,效能很好。所以我認為這個Calico從技術角度來講是非常卓越的。但BGP帶給它的好處的同時也帶給他的劣勢,就是BGP協議在企業內部很少被接受,企業網管不太願意在跨網路的路由器上開啟BGP協議——它的規模優勢發揮不出來。這是Calico專案。
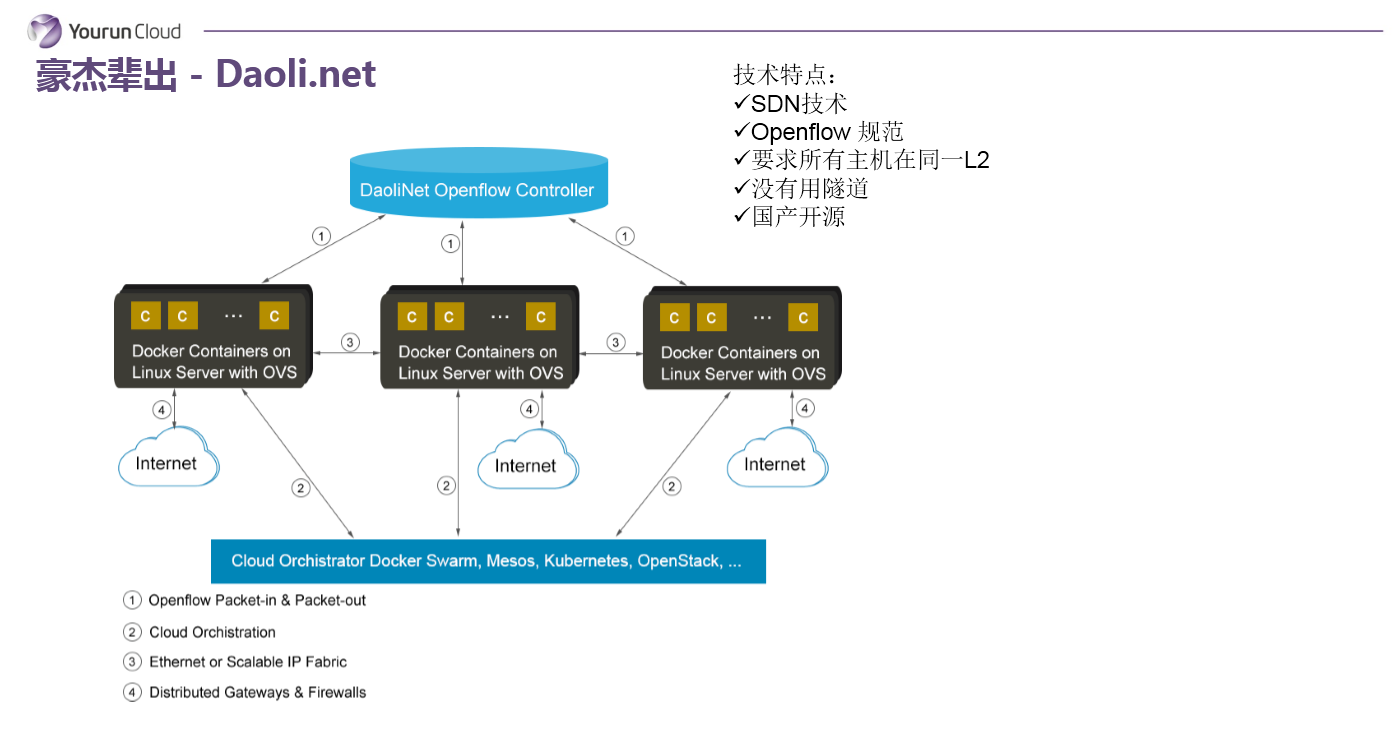
Daoli.net
第四個叫道理雲,創始人毛文波博士,毛博士原來跟我是EMC的同事,他主要是專注於虛擬化的安全領域。道理雲的容器網路,可以說從技術領域來說是非常非常先進的。他認為既然現在要設計一個新的網路為什麼不把SDN跟docker網路結合在一起?所以你可以看它的上面的架構,最上層就是SDN的控制平面,下面是一堆的OpenFlow交換機。道理雲SDN的理念的確比較先進,核心問題是企業接受的難度比較高。試想,SDN尚未被普及到企業裡,SDN容器網路的推廣要更加困難一些,就是在落地層面有侷限性。我們認為這個網路更多的代表未來,也許有一天容器網路發展到比較成熟的時候可能就是這樣子,但是目前階段還是有點陽春白雪。
小結

總結一下,我們會發現容器網路技術不外乎出自兩個技術流派,第一個隧道技術,比如說Rancher的容器網路、Flannel的VXLAN模式。這個技術的特點是對底層的網路沒有過高的要求,通常來說唯一的要求就是就是三層可達——你的主機只要是在一個三層可達網路裡,就能給你構建出一個基於隧道的容器網路,對網路要求比較低。但問題在於什麼呢?一旦構建了Overlay的網路,目前企業已經構建的網路監控的價值,以及企業網路部門的管理職能就會降低很多,因為傳統的網路裝置根本看不到你在隧道里面跑了什麼樣的資料,也就無從監控和管理。同時我們知道所有的Oevrlay網路基本核心的實現點都在主機內部,而網路管的又不是主機,他們管的是下層網路,結果現在必須管一部分主機裡的虛擬裝置,而傳統主機的管理應該是系統部,那麼就會出現交叉管理,網路部和系統部出現權責不分的情況,導致很多客戶不願意使用隧道技術。
第二種技術是路由技術,路由技術好處在於很乾淨,沒有NAT,效率比較高,和目前的網路能夠融合在一起,每一個容器都可以像虛擬機器一樣分配一個業務的IP。大家可以用最自然最容易接受的方式使用容器,好像你就分配了一個新的虛擬機器一樣。但路由網路也有兩個問題,一旦使用了路由網路對現有網路裝置衝擊非常大,現在做網路同志應該知道,路由器的路由表應該有空間限制——兩三萬條。如果一下子幾萬新的容器IP衝擊到路由表裡,導致下層的物理裝置沒辦法承受;同時每一個容器都分配一個業務IP,你的業務IP很快消耗光了。一般大型的企業裡IP分配是很有原則的,可能分配給容器平臺專案的IP也就是幾千個,或者一個段,沒有辦法讓你在每一個容器裡都分配一個IP。這就是路由和隧道技術,我們沒有看到一個完美的技術,每一個都有優勢也都有劣勢。
客戶聲音

下面我們看客戶怎麼說,我們在華南區的一個網際網路銀行,他就非常抵觸Overlay網路,說現在網路技術部門能力不足以維護一個Overlay網路,傳統網路出問題知道怎麼修,但Overlay網路出問題不知道怎麼修,會出現失控的狀態。我們在北區一個全國性股份制銀行,對隧道技術比較反感。他們目前已經部署了SDN,不希望在SDN裡再打洞,因為一旦構建隧道運維部門就變成了瞎子,以前能管的事現在就管不了了。而華東一個金融機構不願意接受基於IPSec的隧道技術。他們的說法是說IPCEC這種效能會比較弱一些,所以我們可以看到目前的大部分的客戶它還是傾向於使用這種傳統的路由技術的網路。
雙雄會格局

容器網路發展的第三階段——雙雄會的格局。雙雄會其實指的就是Docker的CNM和Google、CoreOS、Kuberenates主導的CNI。首先明確一點,CNM和CNI並不是網路實現,他們是網路規範和網路體系,從研發的角度他們就是一堆介面,你底層是用Flannel也好、用Calico也好,他們並不關心,CNM和CNI關心的是網路管理的問題。
CNM是Docker自帶的,可以通過Docker命令直接管理的網路模型。而CNI並不是Docker原生的,它是為容器技術設計的通用型網路介面。CNI介面從上往下呼叫是沒有問題的,但從下往上支援不太可能,或者實現會非常Tricky,所以這個CNI很難沒有辦法在docker層面主動去啟用。這兩個模型全都是外掛化的,你都可以去以外掛的形式去插入具體的網路實現。這兩個外掛,CNM要更加家長式一些,靈活度沒有那麼高。而CNI由於要通用,靈活性相對就比較高了。這是這兩個規範的基礎特徵。
他們搞了這兩個標準之後,所有都要面臨一個問題:我到底要支援哪個標準?現在各家支援的情況是這樣的:Docker Swarm首先是站到了CNM這邊,都是Docker公司的。有容雲目前支援的是CNM,這樣的選擇並非技術上的原因,而是因為我們現在的平臺也只支援Docker,我們尚沒有支援Rocket,如果有一天支援除了Docker之外的容器技術,那麼我們可能也會同時支援CNI。 Kubernetes當然支援CNI了。其他的如Calico、Weave、Mesos等屬於兩邊都支援的情況。
有容雲對於網路的支援
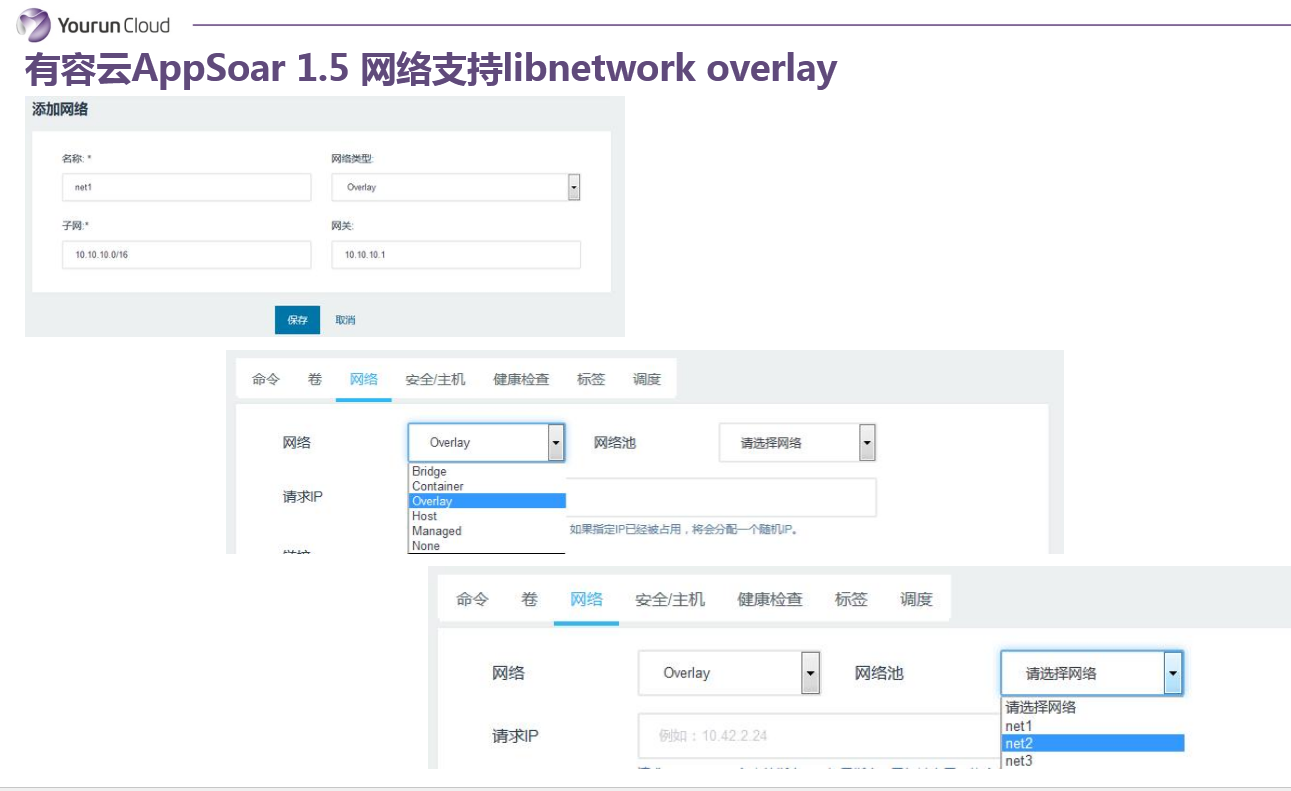
前面講了具體的技術,佔用大家幾分鐘時間講一講有容雲對於網路的支援。因為有容雲是脫胎於Rancher,所以我們繼承了了Rancher所有的優點,Rancher基於IPSec的網路我們也有。但是從我們的角度,我們支援的網路是需要最大程度的適配我們客戶的需求的。如果客戶說就用簡單的IPSec Overlay網路,我們有部分客戶想用的VXLan網路,也支援了Libnetwork Overlay,其實本質就是VXLAN。同時,如果客戶想像虛擬機器一樣去分配業務IP給容器,我們也有基於MAC VLAN的網路實現。
MACVLAN
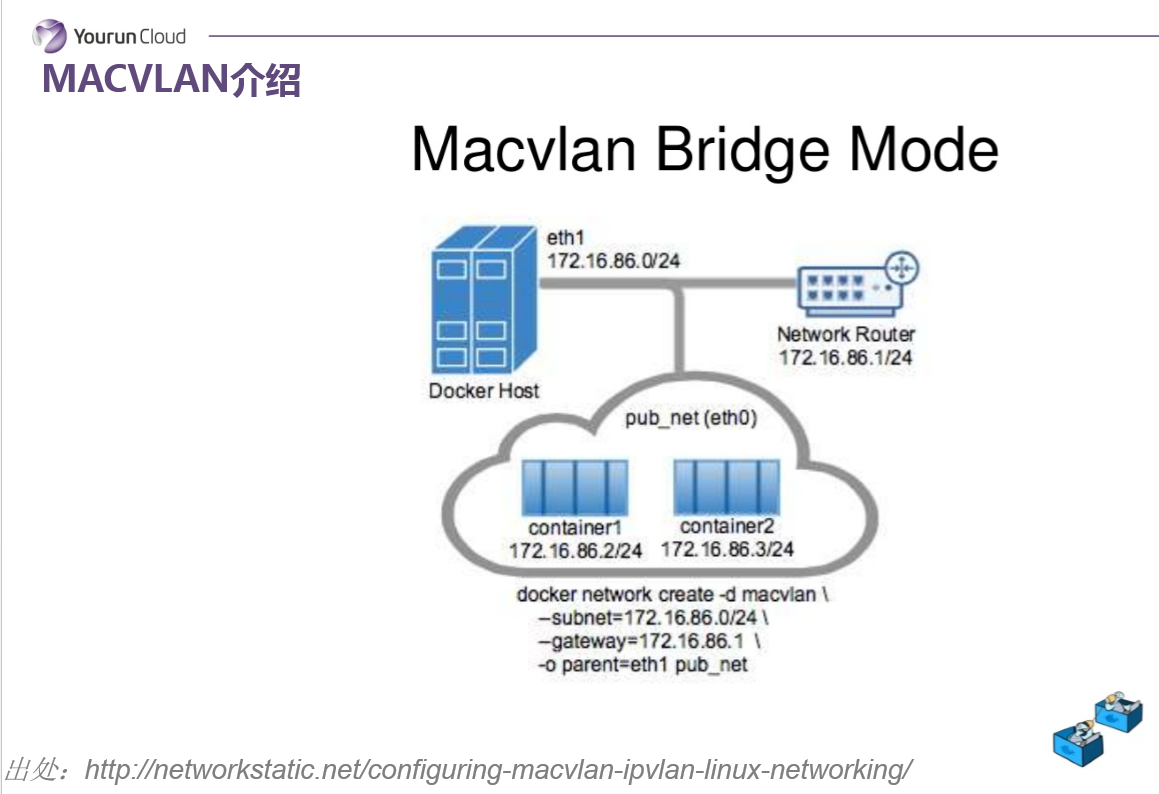
簡單介紹一下MACVLAN,MAC VLAN的核心技術是可以把物理網絡卡虛擬出來多塊虛擬網絡卡,每個虛擬網絡卡都有獨立的Mac地址,從外界看來,就像是把網線分成兩股,分別接到了不同的主機上一樣。基於MAC VLAN的這樣的話我就可以把這個Mac地址分配給每一個容器使用,也就是說未來每一個容器都會有一個獨立的Mac地址和業務網IP,可以像一臺獨立的虛擬機器來工作。
IPvLan L2
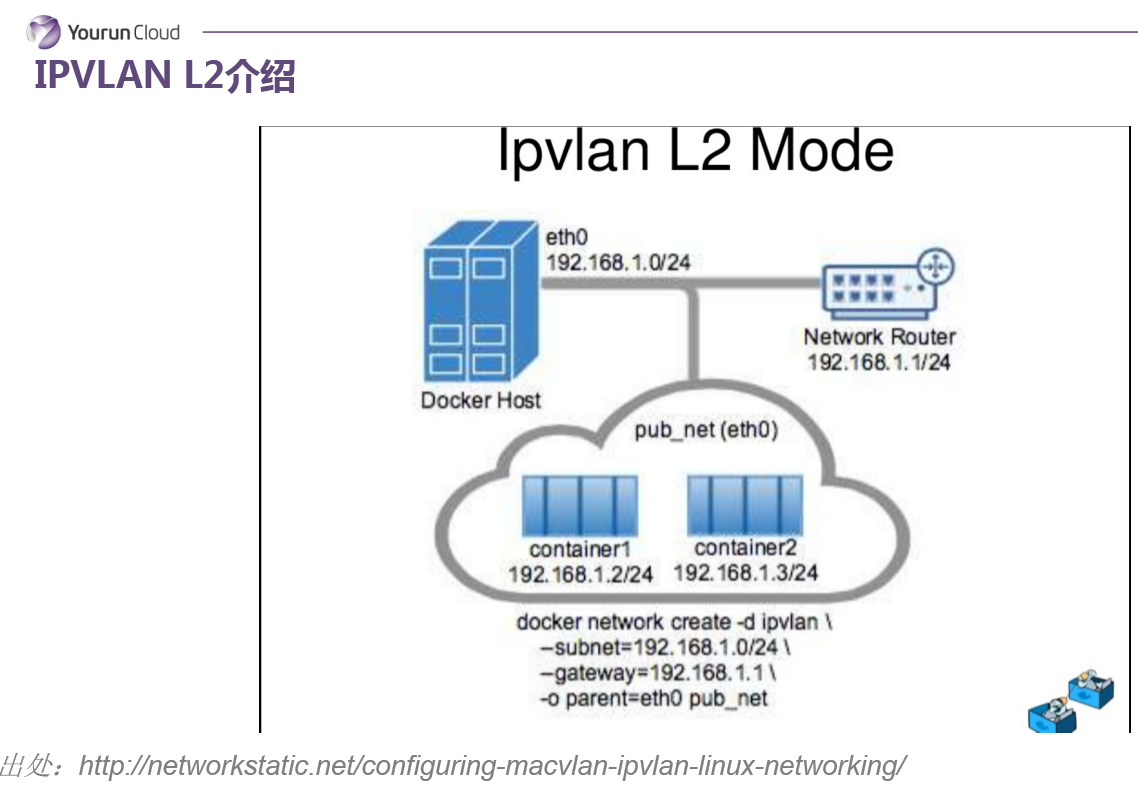
另一個值得給大家介紹就是IPvLan L2 Mode,從現象上看基本上和macvlan的行為是一致的,除了每個容器沒有獨立的mac地址。在單獨主機上所有的容器mac地址是相同的,這是和macvlan唯一的區別,我們認為這個方式也很有前途。這兩種的方式最後都能達到一個效果,就是容器像虛擬機器一樣可以被分配一個業務網IP,並且能夠從外部直接訪問到這個業務網的IP,直接訪問到這個容器。
好,我今天關於網路介紹就到此,謝謝。