
GAN在半監督學習上的應用
參考論文:https://arxiv.org/pdf/1606.01583.pdf
http://arxiv.org/abs/1606.03498
摘要
近幾年,深度學習聲名鵲起,一個又一個AI領域被深度學習攻破,然而現在大部分深度學習所採用的演算法都是有監督學習的方法,需要大量的標註資料,這也就需要耗費大量的人力物力。因此如何充分利用大量的無標籤資料資源,必將成為未來深度學習領域的研究焦點。
通過使用判別器網路輸出類別標籤將GAN擴充套件到半監督領域。在一個有N個類別的資料集上訓練生成模型G和判別模型D。訓練時,D預測輸入資料屬於N個類別中的哪一個,加入一個額外的類別對應G的輸出。我們證明,相對與普通GAN,此方法可以用來生成一個更有效的分類器並可以生成高質量的樣本。
1、介紹
利用GAN生成影象已經顯示出很有前景的結果。生成器網路G和判別器網路D作為對抗的物件同時訓練。G接收一個噪聲向量作為輸入,輸出影象(樣本);D 接收影象(樣本)並輸出該影象是否是來自G 的預測。訓練G 用以最大化D 犯錯的概率,訓練D 用來最小化自己犯錯的概率。基於這些想法,運用卷積神經網路的級聯,可以生成高質量的輸出樣本(DCGAN)。最近,一個single generator network產生了更好的樣本(Radford )。在這裡,我們考慮試圖解決一個半監督分類任務並同時學習一個生成模型。例如,我們可以在MNIST資料集上學習一個生成模型同時訓練一個影象分類器,我們把它叫做C 。在半監督學習任務上使用生成模型並不是一個新想法,Kingma等人擴充套件了變分生成技術就是未來做到這一點。這裡,我們想用GANs做些類似的事。我們不是第一個用GAN 做半監督學習的。CatGAN(Springenberg, J. T. Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Net-works. ArXiv e-prints, November 2015.)對目標函式建模時考慮到了觀察樣本和預測樣本類別分佈間的互資訊。在Radford等人的文章中,D學習到的特徵複用在了分類器裡。
後者證明了所學特徵表示式的實用性,但是仍有一些不好的特性。首先,D 學習到的表示式有助於C這一事實並不意外–看起來就很合理。然而,學習到一個好的C有助於D 的效能看起來也很合理。比如,分類器C的輸出值中熵比較高的那些影象更有可能來自G。如果我們在瞭解了此fact之後,只是簡單地運用D學到的隱層表示(或者提取到的影象特徵:也就是我們常說的隱編碼)來增強C,這樣沒什麼益處。第二,運用D學習到的隱層表示不能同時訓練C和G 。為了提高效率,我們希望能做到這一點,但有一個更重要的動機。如果改善D 能改善C,並且若改善C就 能改善D ,那麼我們可以利用一系列的反饋環路,3個分量(G,C,D)迭代地使彼此更好。
在本文,受上述推理的啟發,我們做出來以下貢獻:
1、我們對GANs做了一個新的擴充套件,允許它同時學習一個生成模型和一個分類器。我們把這個擴充套件叫做半監督GAN 或SGAN
2、我們表明SGAN在有限資料集上比沒有生成部分的基準分類器 提升了分類效能。
3、我們證明,SGAN可以顯著地提升生成樣本的質量並降低生成器的訓練時間。
2、SGAN模型
標準GAN中的判別器網路D輸出一個關於輸入影象來自資料生成分佈中的概率。傳統方法中,這由一個以單個sigmoid單元結束的前饋網路實現,但是,也可以由一個softmax輸出層實現,每個類一個單元[real, fake]。 一旦進行這樣的修改後,很容易看出D 有N+1個輸出單元,對應[類1,類2,…,類N ,fake]。這種情況下,D也可以作為一個C。我們將此網路叫做 D/C。
訓練SGAN 與訓練GAN 類似,我們只是對從資料生成分佈中提取的一半小批量使用更高粒度的標籤(higher granularity labels )。訓練D/C以最小化給定標籤的負對數似然性(negative log likehood),訓練G以最大化它。見演算法1。我們沒有用Goodfellow等人文中第三節提到的相關改進技巧。(Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B.,Warde-Farley, D., Ozair, S., Courville, A., and Bengio,Y. Generative Adversarial Networks. ArXiv e-prints,June 2014.)
標準的分類網路將資料輸出為可能的
個classes,然後對K維的向量使用softmax:
標準的分類是有監督的學習,模型通過最小化交叉熵損失,獲得最優的網路引數。 對於GAN網路,可以把生成網路的輸出作為第K+1類,相應的判別網路變為K+1類的分類問題。用表示生成網路的圖片為假,用來代替標準GAN的
。對分類網路,只需要知道某一張圖片屬於哪一類,不用明確知道這個類是什麼,通過
就可以訓練。 所以損失函式就變為了:
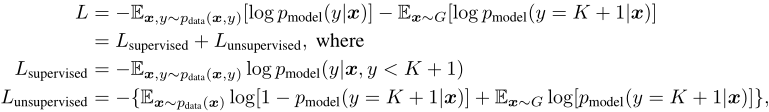
如果令,上述無監督的表示式就是GAN的形式:
![]()
注意:在並行工作中,(Salimans等,2016)提出了相同的方法來增強鑑別器並對該技術進行更徹底的實驗評估。

3、結果
3.1、生成結果
在MNIST資料集上實驗來看SGAN 是否可以比一般GAN得到更好的生成樣本。用一個與DCGAN類似的結構訓練SGAN ,訓練時用了真實的MNIST標籤和只有real和fake的兩種標籤。注意,第二種配置與通常的GAN 語義上完全相同。圖1包含了GAN和SGAN 兩者生成的樣本。SGAN 的輸出明顯比GAN 的輸出更清晰。這看起來對於不同的初始化和網路架構中都是正確的,但是很難對不同的超引數進行樣本質量的系統評估。

3.2 分類結果
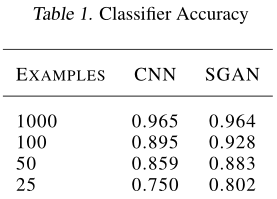
在MNIST 上進行實驗,看SGAN 的分類器部分在有限的訓練集上是否可以比一個獨立的分類器表現得更好。為了訓練baseline(基線),我們在訓練SGAN時沒有更新G 。SGAN 勝過baseline,我們越縮減訓練集,優勢越明顯。這表明強制D和C共享權重提高了資料效率。表1展示了詳細的效能資料。為了計算正確率,we took the maximum of the outputs not corresponding to the FAKE label.對於每個模型,我們對學習率進行了隨機搜尋,並呈現出最佳結果。
4、結論和展望
①、共享D 和C 之間的部分權重(而不是全部),像dual autoencoder中一樣(Sutskever, I., Jozefowicz, R., Gregor, K., Rezende, D., Lillicrap, T., and Vinyals, O. Towards Principled Unsupervised Learning. ArXiv e-prints, November 2015.)。這樣可以讓一些權重專屬於判別,一些權重專屬於分類。
②、讓GAN 生成帶類別標籤的樣本(Mirza)。然後要求D/C指派出是2N 個標籤中的哪個[real-0,fake-0,real-1,fake-1,…,real-9,fake-9]。
③、引入一個ladder network(階梯網路)L 代替D/C,然後用來自G的樣本作為未標記的資料來訓練L。