
hadoop之傳統的行儲存和(HBase)列儲存的區別
轉自:https://blog.csdn.net/youzhouliu/article/details/67632882
1 為什麼要按列儲存
列式儲存(Columnar or column-based)是相對於傳統關係型資料庫的行式儲存(Row-basedstorage)來說的。簡單來說兩者的區別就是如何組織表(翻譯不好,直接抄原文了):
Ø Row-based storage stores atable in a sequence of rows.
Ø Column-based storage storesa table in a sequence of columns.
下面來看一個例子:
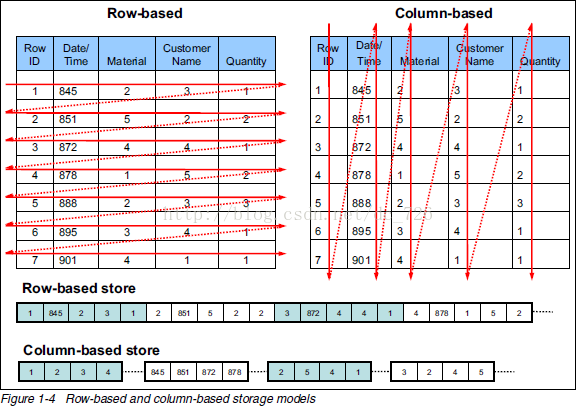
從上圖可以很清楚地看到,行式儲存下一張表的資料都是放在一起的,但列式儲存下都被分開儲存了。所以它們就有了如下這些優缺點:
行式儲存 | 列式儲存 | |
優點 | Ø 資料被儲存在一起 Ø INSERT/UPDATE容易 | Ø 查詢時只有涉及到的列會被讀取 Ø 投影(projection)很高效 Ø 任何列都能作為索引 |
缺點 | Ø 選擇(Selection)時即使只涉及某幾列,所有資料也都會被讀取 | Ø 選擇完成時,被選擇的列要重新組裝 Ø INSERT/UPDATE比較麻煩 |
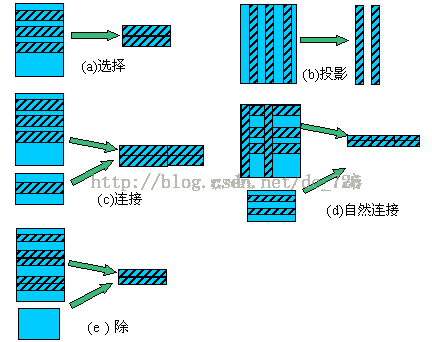
注:關係型資料庫理論回顧 - 選擇(Selection)和投影(Projection)
2補充:資料壓縮
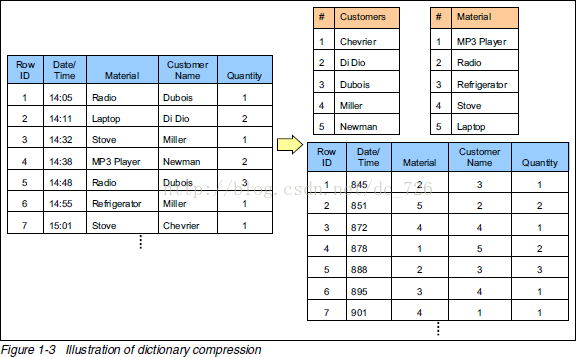
剛才其實跳過了資料裡提到的另一種技術:通過字典表壓縮資料。為了方便後面的講解,這部分也順帶提一下。
下面才是那張表本來的樣子。經過字典表進行資料壓縮後,表中的字串才都變成數字了。正因為每個字串在字典表裡只出現一次了,所以達到了壓縮的目的(有點像規範化和非規範化Normalize和Denomalize)
3查詢執行效能
下面就是最牛的圖了,通過一條查詢的執行過程說明列式儲存(以及資料壓縮)的優點:
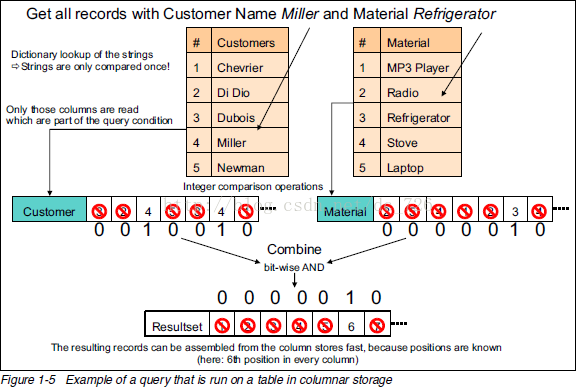
關鍵步驟如下:
1. 去字典表裡找到字串對應數字(只進行一次字串比較)。
2. 用數字去列表裡匹配,匹配上的位置設為1。
3. 把不同列的匹配結果進行位運算得到符合所有條件的記錄下標。
4. 使用這個下標組裝出最終的結果集。