
ElasticSearch學習總結(二):ES介紹與架構說明
本文主要從概念以及架構層面對Elasticsearch做一個簡單的介紹,在介紹ES之前,會先對ES的“發動機”Lucene做一個簡單的介紹
1. Lucene介紹
為了更深入地理解ElasticSearch的工作原理,特別是索引和查詢這兩個過程,理解Lucene的工作原理至關重要。本質上,ElasticSearch是用Lucene來實現索引的查詢功能的。
1.1 定義
Lucene是一個成熟的、高效能的、可擴充套件的、輕量級的,而且功能強大的搜尋引擎包。Lucene的核心jar包只有一個檔案,而且不依賴任何第三方jar包。更重要的是,它提供的索引資料和檢索資料的功能開箱即用。當然,Lucene也提供了多語言支援,具有拼寫檢查、高亮等功能。
1.2 架構
1.2.1 術語
Lucene中的術語和 <
1.2.2 儲存
Apache Lucene把所有的資訊都寫入到一個稱為倒排索引的資料結構中,倒排索引的介紹可以參考 <
1.3 資料分析
學習ES初期,我經常考慮的問題是,傳入到Document中的資料是如何轉變成倒排索引的?查詢語句是如何轉換成一個個Term使高效率文字搜尋變得可行?這種轉換資料的過程就稱為文字分析(analysis)
文字分析工作由analyzer元件負責。analyzer由一個分詞器(tokenizer)和0個或者多個過濾器(filter)組成,也可能會有0個或者多個字元對映器(character mappers)組成。
Lucene中的tokenizer用來把文字拆分成一個個的Token。Token包含了比較多的資訊,比如Term在文字的中的位置及Term原始文字,以及Term的長度。文字經過tokenizer處理後的結果稱為token stream。token stream其實就是一個個Token的順序排列。token stream將等待著filter來處理。
除了tokenizer外,Lucene的另一個重要組成部分就是filter鏈,filter鏈將用來處理Token Stream中的每一個token。這些處理方式包括刪除Token,改變Token,甚至新增新的Token。Lucene中內建了許多filter,讀者也可以輕鬆地自己實現一個filter。有如下內建的filter:
- Lowercase filter:把所有token中的字元都變成小寫
- ASCII folding filter:去除tonken中非ASCII碼的部分
- Synonyms filter:根據同義詞替換規則替換相應的token
- Multiple language-stemming
- filters:把Token(實際上是Token的文字內容)轉化成詞根或者詞幹的形式。
所以通過Filter可以讓analyzer有幾乎無限的處理能力:因為新的需求新增新的Filter就可以了。
1.4 索引和查詢
索引過程:Lucene用使用者指定好的analyzer解析使用者新增的Document。當然Document中不同的Field可以指定不同的analyzer。如果使用者的Document中有title和description兩個Field,那麼這兩個Field可以指定不同的analyzer。
搜尋過程:使用者的輸入查詢語句將被選定的查詢解析器(query parser)所解析,生成多個Query物件。當然使用者也可以選擇不解析查詢語句,使查詢語句保留原始的狀態。在ElasticSearch中,有的Query物件會被解析(analyzed),有的不會,比如:字首查詢(prefix query)就不會被解析,精確匹配查詢(match query)就會被解析。對使用者來說,理解這一點至關重要。
對於索引過程和搜尋過程的資料解析這一環節,我們需要把握的重點在於:倒排索引中詞應該和查詢語句中的詞正確匹配。如果無法匹配,那麼Lucene也不會返回我們喜聞樂見的結果。舉個例子:如果在索引階段對文字進行了轉小寫(lowercasing)和轉變成詞根形式(stemming)處理,那麼查詢語句也必須進行相同的處理。或是查詢使用的analyzer必須和索引時使用的analyzer相同。
1.4 查詢語言
使用者使用Lucene進行查詢操作時,輸入的查詢語句會被分解成一個或者多個Term以及邏輯運算子號。一個Term,在Lucene中可以是一個詞,也可以是一個短語(用雙引號括引來的多個詞)。如果事先設定規則:解析查詢語句,那麼指定的analyzer就會用來處理查詢語句的每個term形成Query物件。
具體的語法細節部分,想要描述起來是個龐大的工程,具體可參考對應文件。
在ES中也可以使用Lucene的語法進行查詢,使用方法可參考:https://www.elastic.co/guide/en/elasticsearch/reference/5.2/modules-scripting-expression.html
2. ES 介紹
2.1 介紹
引用我認為最簡潔的一句話來概括ES
**Elasticsearch 是一個基於Lucene的分散式搜尋和分析引擎.**2.2 基本概念
索引(Index):ElasticSearch把資料存放到一個或者多個索引(indices)中。ElasticSearch內部用Apache Lucene實現索引中資料的讀寫。但是在ElasticSearch中被視為單獨的一個索引(index),在Lucene中可能不止一個。這是因為在分散式體系中,ElasticSearch會用到分片(shards)和備份(replicas)機制將一個索引(index)儲存多份。
文件(Document):文件(Document)由一個或者多個欄位(Field)組成。ES中的文件(Document)是沒有固定的模式和統一的結構。
- 文件型別(Type):每個文件在ElasticSearch中都必須設定它的型別。文件型別使得同一個索引中在儲存結構不同文件時,只需要依據文件型別就可以找到對應的引數對映(Mapping)資訊,方便文件的存取。
節點(Node):單獨一個ElasticSearch伺服器例項稱為一個節點。對於許多應用場景來說,部署一個單節點的ElasticSearch伺服器就足夠了。但是考慮到容錯性和資料過載,配置多節點的ElasticSearch叢集是明智的選擇。
叢集(Cluster):叢集是多個ElasticSearch節點的集合。是提供高可用與高效能的重要手段
分片索引(Shard):叢集能夠儲存超出單機容量的資訊。為了實現這種需求,ElasticSearch把資料分發到多個儲存Lucene索引的物理機上。這些Lucene索引稱為分片索引,這個分發的過程稱為索引分片(Sharding)。
需要注意的是:叢集中分片的數量需要在索引建立前配置好,而且伺服器啟動後是無法修改的,至少目前無法修改。
索引副本(Replica):當叢集負載增長,使用者搜尋請求可能會阻塞在單個節點上時,通過索引副本(Replica)機制就可以解決這個問題。在提供基礎查詢效能的同時,也保證了資料的安全性。即如果主分片資料丟失,ElasticSearch通過索引副本使得資料不丟失。索引副本可以隨時新增或者刪除,所以使用者可以在需要的時候動態調整其數量。
網管(Gateway):ES執行過程中需要的所有資料(文件,狀態、索引引數等)都被儲存在Gateway中。
2.3 工作原理
本部分從啟動,故障檢測,資料索引,查詢 四個部分進行總結
2.3.1 啟動
當Elasticsearch節點啟動時,會使用發現(discovery)模組來通過傳送廣播請求的方式發現同一個叢集中的其他節點。
在叢集中有一個節點被選為主(master)節點。該節點負責叢集的狀態管理以及在叢集拓撲變化時做出反應,分發索引分片至叢集的相應節點上去。
在使用者看來叢集中節點的角色是透明的。使用的過程中不需要知道哪個節點是管理節點,請求可以傳送給任意節點,如果有需要,任意節點可以並行傳送子查詢給其他節點,併合並搜尋結果,然後返回給使用者。所有這些操作並不需要經過管理節點處理(請記住,Elasticsearch是基於對等架構的)。
在啟動階段,管理節點會讀取叢集的狀態資訊並檢查有哪些索引分片,並決定哪些分片將用作主分片。此後,整個叢集進入黃色狀態。
這意味著叢集可以執行查詢,但是系統的吞吐量以及各種可能的狀況是未知的(這種狀況可以簡單理解為所有的主分片已經被分配了,但是副本沒有被分配)。下面的事情就是尋找到冗餘的分片用作副本。如果某個主分片的副本數過少,管理節點將決定基於某個主分片建立分片和副本。如果一切順利,叢集將進入綠色狀態(這意味著所有主分片以及副本均已分配好)。
2.3.2 故障檢測
叢集正常工作時,管理節點會監控所有可用節點,通過PING的方式檢查它們是否正在工作。如果任何節點在預定義的超時時間內不響應,則認為該節點已經斷開,然後錯誤處理過程開始啟動。這意味著可能要在叢集–分片之間重新做平衡,選擇新的主節點等。對每個丟失的主分片,一個新的主分片將會從原來的主分片的副本中選出來。
2.3.3 與ElasticSearch通訊
Elasticsearch對外公開了一個設計精巧的API,通過這些API可以進行索引以及查詢的操作,傳參的方式主要包括URL攜帶或是JSON文件的形式。
2.3.4 資料索引
資料索引的方式可以通過簡單的API一條一條的索引,也可以通過Bulk API(包括HTTP,UDP兩種)進行批量的建立索引。
有一件事情需要記住,建索引操作只會發生在主分片上,而不是副本上。當一個索引請求被髮送至一個節點上時,如果該節點沒有對應的主分片或者只有副本,那麼這個請求會被轉發到擁有正確的主分片的節點。然後,該節點將會把索引請求群發給所有副本,等待它們的響應(這一點可以由使用者控制),最後,當特定條件具備時(比如說達到規定數目的副本都完成了更新時)結束索引過程。
流程如下
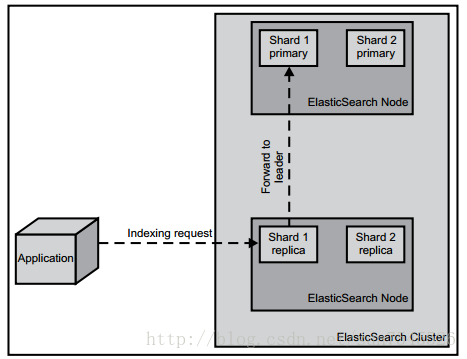
2.3.5 查詢
Elasticsearch提供了豐富的查詢功能,後續章節會對查詢功能進行簡單的總結,本節主要討論查詢的機制。
關於查詢操作需要注意的是:查詢並不是一個簡單的、單步驟的操作。一般來說,查詢分為兩個階段:分散階段(scatter phase)和合並階段(gather phase)。在分散階段將查詢分發到包含相關文件的多個分片中去執行查詢,而在合併階段則從眾多分片中收集返回結果,然後對它們進行合併、排序,進行後續處理,然後返回給客戶端。該機制可以由下圖描述。
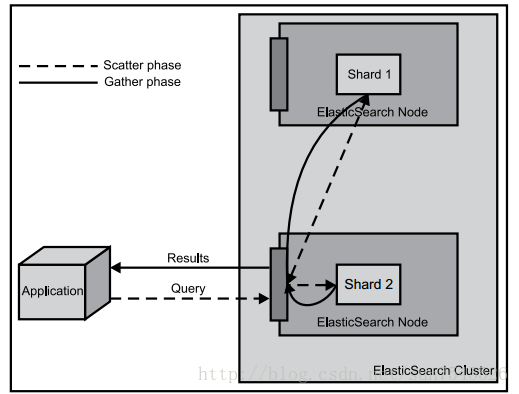
參考
- 《深入理解Elasticsearch》
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html