
JAVA高併發之鎖的優化及原始碼解讀
在現代系統多核的時代,使用多執行緒明顯了地提高了系統的效能,但是在高併發的環境中,激烈的鎖競爭對系統的效能帶來的嚴重的影響,因為對於多執行緒來說,它不僅要維持每一個執行緒本身的元資料,還要負責執行緒之間的切換,不斷的掛起,喚醒,浪費了大量的時間,因此,有必要探討一下如何將多執行緒中鎖的優化做到極致,給系統帶來更大的好處。
對於“鎖”效能的優化
本文將圍繞“鎖”優化來講解,其中會涉及到部分JDK的原始碼解讀,希望通過一些JDK內部的例子來說明鎖的優化帶來的好處。
在應用層面鎖的優化主要有以下幾種:
- 減小鎖的持有時間
- 減小鎖的顆粒度
- 讀寫鎖分離來替換獨佔鎖
- 鎖分離
- 鎖的粗化
(也許在網上讀者可能會看到不同的說法,但其原理上是差不多的,本文是基於JDK1.8的)。
一、減小鎖的持有時間
對於使用鎖的應用程式而言,在多執行緒中,只要有一個執行緒佔用了該鎖,其他的鎖就會等待當前執行緒釋放鎖,如果每一個執行緒持有鎖的時間非常長,那麼整個系統的效能會大大的降低。以下面一段程式碼為例:
private synchronized void sync() {
method1();
mutexMethod();
method2();
}明明在併發環境下只需要mutexMethod()方法實現同步,而你對整個方法加鎖,而這個方法要呼叫三個方法,如果method1方法和method2方法是重量級方法,那麼不是會浪費大量的時間嗎?因此,我們有必要將上面的程式碼改為下面的程式碼,減小鎖的持有時間來優化系統:
private void sync() {
method1();
synchronized (mutex) {
mutextMethod();
}
method2();
}實際上,在JDK內部也大量的使用該方法來優化鎖,比如處理正則表示式的Pattern類的內部的matcher方法只有在表示式沒有編譯的時候才會區域性加鎖,這樣大大提高了matcher方法的執行效率。
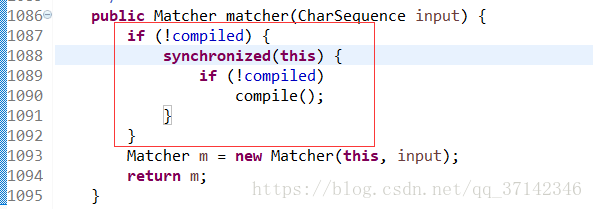
二、減小鎖的顆粒度
減小鎖的顆粒度也是一種優化鎖的方案,最典型的就是JDK內部ConcurrentHashMap的實現原理,我們都知道它與HashMap的不同之處在與它是執行緒安全的,那麼有沒有想過是怎麼實現執行緒安全的呢?在HashMap的內部,有兩個重要的方法put和get方法,可能大多數人會想到在這兩個方法上加鎖,但是這兩個方法內部實現很複雜,如果在這兩個方法上加上方法鎖就會導致鎖的顆粒度太大,所以,這個方法肯定不行。不妨,來看看ConcurrentHashMap是怎樣實現執行緒安全的,我想,它肯定不會想上面一樣加上又重又笨的鎖吧。


下面來簡單看看ConcurrentHashMap的原始碼,在JDK1.7和JDK1.8之間,ConcurrentHashMap做了很大的改變,在JDK1.7中有一個段(Segment)的概念,也就是說在ConcurrentHashMap內部將HashMap細分為若干個HashMap,稱之為段(Segment),預設情況下,ConcurrentHashMap分為16個段。當需要Put一個表項的時候,ConcurrentHashMap並不會對整個HashMap加鎖,它首先會通過hashcode得到該表項放到哪個段,然後對該段加鎖,因此,如果有多個執行緒同時進行put操作,它們也不一定會放入到一個段中,這樣給不同的段加鎖就可能做到真正的並行。先來看看JDK1.7下區域性變數和put方法原始碼:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 將整個hashmap分成幾個小的map,每個segment都是一個鎖;與hashtable相比,這麼設計的目的是對於put, remove等操作,可以減少併發衝突,對
// 不屬於同一個片段的節點可以併發操作,大大提高了效能
final Segment<K,V>[] segments;
// 本質上Segment類就是一個小的hashmap,裡面table陣列儲存了各個節點的資料,繼承了ReentrantLock, 可以作為互拆鎖使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本節點,儲存Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
public V put(K key,V value){
Segment<K,V> s;
if(value==null){
throw new NullPointException();
int hash=hash(key);
int j=(hash>>>segmentShift)&segmentMask;
if((s=(Segment<K,V>)UNSAFE.getObject
(segments,(j<<SSHIFT)+SBASE))==NULL)
s=ensureSegment(j);
return s.put(key,hash,value,false);
)可以看出,它會先根據key找到hash值,然後定位到該段進行操作。這裡順便提一下,在JDK1.7中該類的size()方法中,如果要獲取其size大小,先會嘗試以無鎖的方式來求和,如果失敗,就會在每一段中先加鎖,然後再每一段求和,然後彙總,最後釋放鎖,這樣可以看出使用size方法效能不是很高,但是大多數情況下,我們使用ConcurrentHashMap很少使用size方法,因此是值得的。
而在JDK1.8中,取消了段的概念,採用table儲存資料,對每一行資料進行加鎖,減小了鎖的顆粒度。下面是JDK1.8中put方法的部分原始碼:
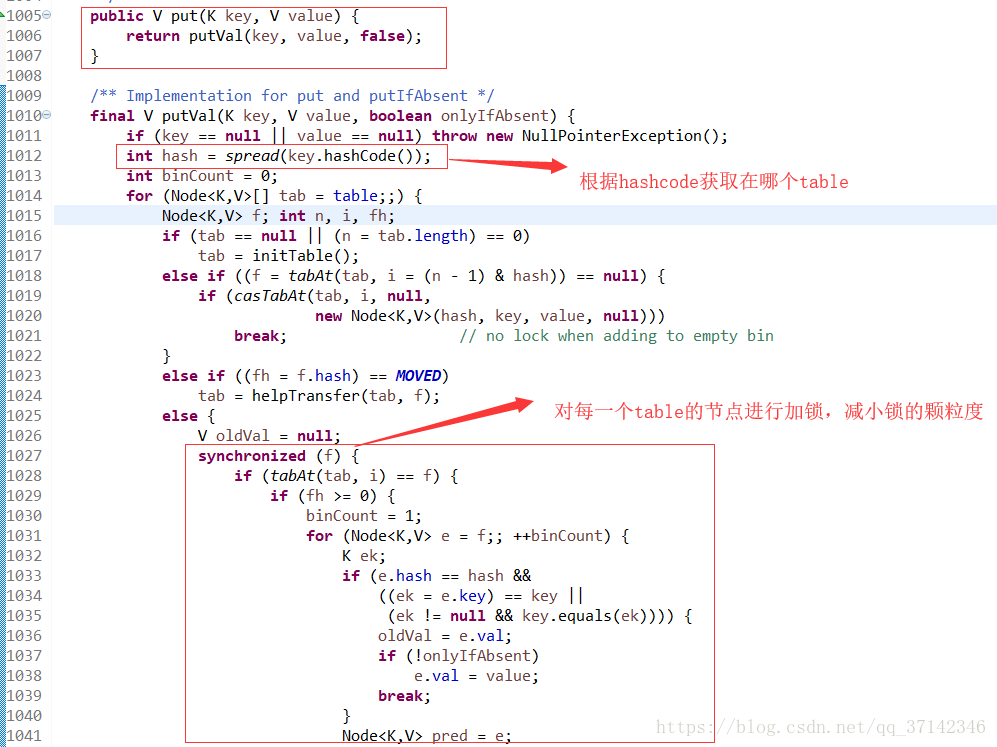
這裡由於本文探討的主題不是ConcurrentHashMap,因此對於它的原始碼以及不同JDK版本的區別進行探討,讀者如果想深究可以參考這篇部落格(https://blog.csdn.net/mawming/article/details/52302448)
三、讀寫分離鎖來替換獨佔鎖
在讀多寫少的場合,我們可以使用讀寫鎖ReadWriteLock,它是一個藉口,對於讀寫操作分別用了不同的鎖。

因此,對資料的讀操作並不需要相互等待,你先讀和它先讀都是一樣的,不想寫操作一樣產生髒資料,因此,我們可以總結出,對於讀寫鎖的訪問約束表如下:
| 讀 | 寫 | |
|---|---|---|
| 讀 | 非阻塞 | 阻塞 |
| 寫 | 阻塞 | 阻塞 |
可以看一個簡單的例子來看看讀寫鎖的效能。
package cn.just.thread.concurrent;
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* 測試讀寫鎖
* 使用讀寫鎖時:讀讀操作是並行的,所以耗費時間短
* 使用普通鎖時:讀讀操作是序列的,所以要耗費很多時間
* @author Shinelon
*
*/
public class ReaddWriteLockDemo {
private static Lock lock=new ReentrantLock();
private static ReentrantReadWriteLock readWriteLock=new ReentrantReadWriteLock(); //讀寫鎖
private static Lock readLock=readWriteLock.readLock(); //讀鎖
private static Lock writeLock=readWriteLock.writeLock(); //寫鎖
private int value;
/**
* 讀操作
* @param lock
* @return
* @throws InterruptedException
*/
public Object handRead(Lock lock) throws InterruptedException{
try{
lock.lock();
Thread.sleep(1000);
return value;
}finally{
lock.unlock();
}
}
/**
* 寫操作
* @param lock
* @param index
* @throws InterruptedException
*/
public void handWrite(Lock lock,int index) throws InterruptedException{
try{
lock.lock();
Thread.sleep(1000);
value=index;
System.out.println(value);
}finally{
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
final ReaddWriteLockDemo demo=new ReaddWriteLockDemo();
Runnable readRunnable=new Runnable() {
@Override
public void run() {
try{
// demo.handRead(readLock); //使用讀鎖
demo.handRead(lock); //使用普通重入鎖
}catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Runnable writeRunnable=new Runnable() {
@Override
public void run() {
try{
// demo.handWrite(writeLock, new Random().nextInt());
demo.handWrite(lock, new Random().nextInt());
}catch (InterruptedException e) {
e.printStackTrace();
}
}
};
/**
* 啟動20個讀執行緒
*/
for(int i=0;i<20;i++){
new Thread(readRunnable).start();
}
/**
* 啟動2個寫執行緒
*/
for(int i=18;i<20;i++){
new Thread(writeRunnable).start();
}
}
}
上面的程式碼分別使用了普通重入鎖和讀寫鎖來開啟18個讀執行緒和2個寫的執行緒來測試,當使用普通重入鎖,讀操作之間也需要相互等待,因此整個程式執行完畢需要20秒左右,很長的一段時間,而使用了讀寫鎖,讀操作之間不需要進行等待,因此讀與讀之間真正的並行,只有兩個寫的執行緒之間需要等待,因此,需要很少的時間就可以完成,大概2秒左右。因此,在讀多寫少的情況採用讀寫鎖對於系統的效能有更大的提升。
四、鎖分離
有的人可能認為鎖分離和讀寫鎖差不多,其實讀寫鎖是根據操作的不同分為不同的種類,而鎖分離是讀寫鎖的擴充套件,它根據應用功能的特點,採用分離的思想,這樣講可能有點搞不清,我們可以看看BlockingQueue介面的兩個實現類的原始碼就可以更好地理解獨佔鎖了。(之前的文章簡單探究過BlockingQueue的原始碼 生產者-消費者模式案例以及資料共享佇列【BlockingQueue】原始碼分析)
在LinkedBlockingQueue(BlockingQueue的一個實現類,連結串列的資料結構)的原始碼中對它的take()和put()方法進行加鎖處理,因為這兩個操作分別是從連結串列的頭部和尾部開始操作,因此相互並不影響,因此完全可以使用兩把不同的鎖來提高併發性。
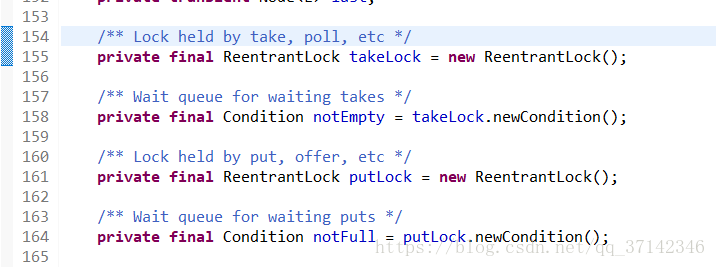
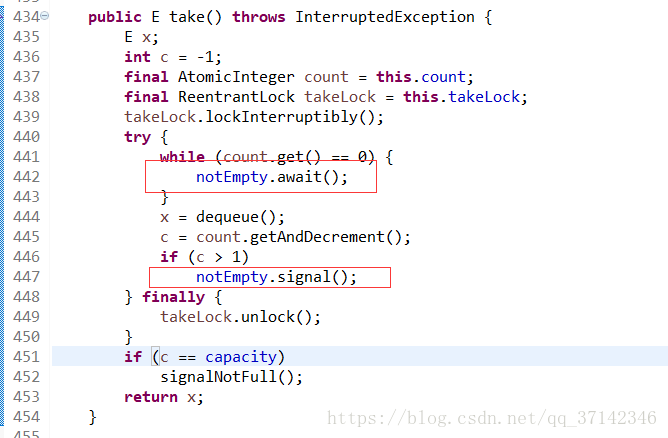
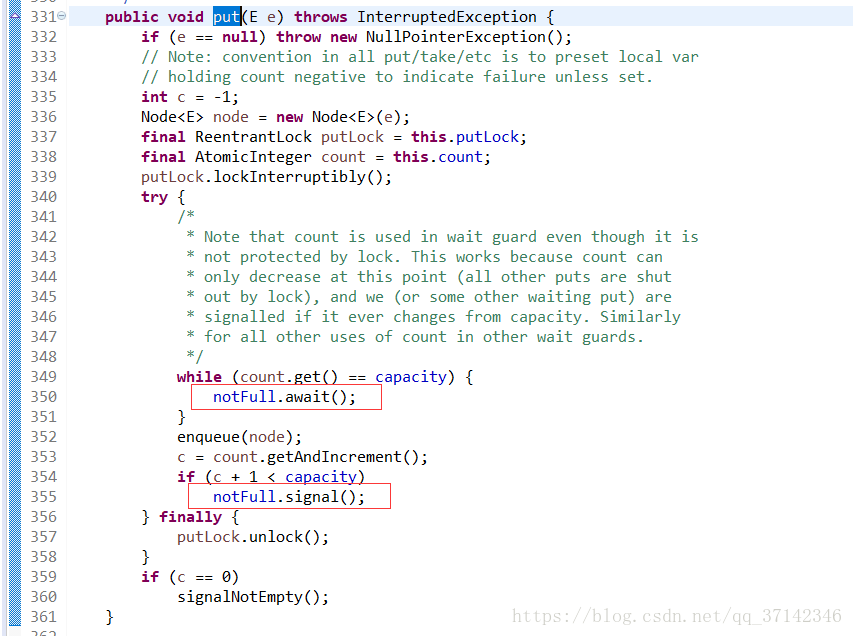
五、鎖的粗化
可能有的讀者感到奇怪,上面不是說到減小鎖的顆粒度嗎?這裡為什麼又要粗化鎖,確實,在有的情況下需要粗化鎖的大小來避免不必要的損耗來提高效能。如果在一系列的操作中,都需要加鎖進行同步處理,但是你對每一個操作都加鎖,這樣,頻繁的加鎖釋放鎖嚴重的耗損了系統的效能,還不如加上一把大的鎖,避免鎖的不斷請求。以下面程式碼為例可以看看如何粗化鎖:
public void test1(){
synchronized(lock){
//do something
}
//中間是耗時很小的操作
synchronized(lock){
//do something
}對於上面的情況我們可以使用下面的方式來優化鎖:
public void test1(){
synchronized(lock){
//do something
}還有一種就是for迴圈加鎖:
for(int i=0;i<size;i++){
synchronized(lock){
//.....
}應優化為下面的程式碼:
synchronized(lock){
for(int i=0;i<size;i++){
//.....
}
}以上就是對鎖的優化方案的幾種不同方式,對於不同的場合,我們可以採用不同的優化的方案,當然,你也可以有自己獨特的優化方式,總之,我們在實際開發中一定要考慮系統的效能。