
深度學習編譯中介軟體之NNVM(五)TVM論文閱讀
參考文件
摘要:現今,像Tensorflow,MXNet,Caffe和Pytorch這樣的可擴充套件框架共同驅動了深度學習的流行度和實用性。但是,這些框架只為一些伺服器端GPU提供優化,並將工作負載部署到其他平臺,如移動手機,嵌入式裝置和其他特定的加速器(e.g., PFGAs, ASICs),對於這些平臺的優化適配是一個巨大工作量的任務。所以我們提出了TVM,一個端到端的優化堆疊,具備圖形級和運算元級的優化,以為多種硬體後端提供深度學習工作負載的效能可移植性。我們討論了 TVM 所解決的深度學習優化挑戰:高階運算元融合(operator fusion)、多執行緒低階記憶體重用、任意硬體基元的對映,以及記憶體延遲隱藏。實驗結果證明 TVM 在多個硬體後端中的效能可與適應低功耗 CPU 和伺服器級 GPU 的當前最優庫相比。我們還通過針對基於 FPGA 的通用深度學習加速器的實驗,展示了 TVM 對新型硬體加速器的適應能力。該編譯器基礎架構已開源。
1 介紹
深度學習模型可以識別影象、處理自然語言,以及在部分具有挑戰性的策略遊戲中擊敗人類。在其技術發展的過程中,現代硬體穩步推進的計算能力扮演了不可或缺的作用。很多目前最為流行的深度學習框架,如 TensorFlow、MXNet、Caffe 和 PyTorch,支援在有限型別的伺服器級 GPU 裝置上獲得加速,這種支援依賴於高度特化、供應商特定的 GPU 庫。然而,專用深度學習加速器的種類越來越多,這意味著現代編譯器與框架越來越難以覆蓋所有的硬體。
顯而易見,以現有的點到點方式實現不同深度學習框架對所有種類的硬體進行後端支援是不現實的。我們的最終目標是讓深度學習負載可以輕鬆部署到所有硬體種類中,其中不僅包括 GPU、FPGA 和 ASIC(如谷歌 TPU),也包括嵌入式裝置,這些硬體的記憶體組織與計算能力存在著顯著的差異,如下圖所示:

考慮到這種需求的複雜性,開發一種能夠將深度學習高階程式降低為適應任何硬體後端的低階優化程式碼的優化框架是最好的方法。
目前的深度學習框架依賴於計算圖的中間表示來實現優化,如自動微分和動態記憶體管理。然而,圖級別的優化通常過於高階,無法有效處理硬體後端運算元級別的轉換。另一方面,目前深度學習框架的運算元級別庫通常過於僵化,難以輕鬆移植到不同硬體裝置上。為了解決這些問題,我們需要一個可實現從計算圖到運算元級別的優化,為各種硬體後端帶來強大效能的編譯器框架。
1.1 優化的基本挑戰
深度學習的優化編譯器需要同時展示高級別與低級別的優化,在論文中,研究人員總結了在計算圖級別與張量運算元級別上的四大基本挑戰:
高層次資料流複寫:不同的硬體裝置可能具有截然不同的記憶體層次結構,因此,融合運算元與優化資料佈局的策略對於優化記憶體訪問至關重要。
跨執行緒記憶體複用:現代 GPU 與專用加速器的記憶體可被多個計算核心共享,傳統的無共享巢狀並行模式已不再是最優方法。為優化核心,在共享記憶體負載上的執行緒合作很有必要。
張量計算行內函數:最新的硬體帶來了超越向量運算的新指令集,如 TPU 中的 GEMM 運算元和英偉達 Volta 架構中的 Tensor Core。因此在排程過程中,我們必須將計算分解為張量算術行內函數,而非標量或向量程式碼。
延遲隱藏(Latency Hiding):儘管在現代 CPU 與 GPU 上,同時擁有多執行緒和自動快取管理的傳統架構隱藏了延遲問題,但專用的加速器設計通常是採用精簡控制流和將複雜性分配到編譯器堆疊上面的方案。所以設計涉及到隱藏記憶體訪問延遲的排程器時必須要非常仔細。
1.2 TVM:一個端到端優化堆疊
下圖展示了TVM的基本構成:
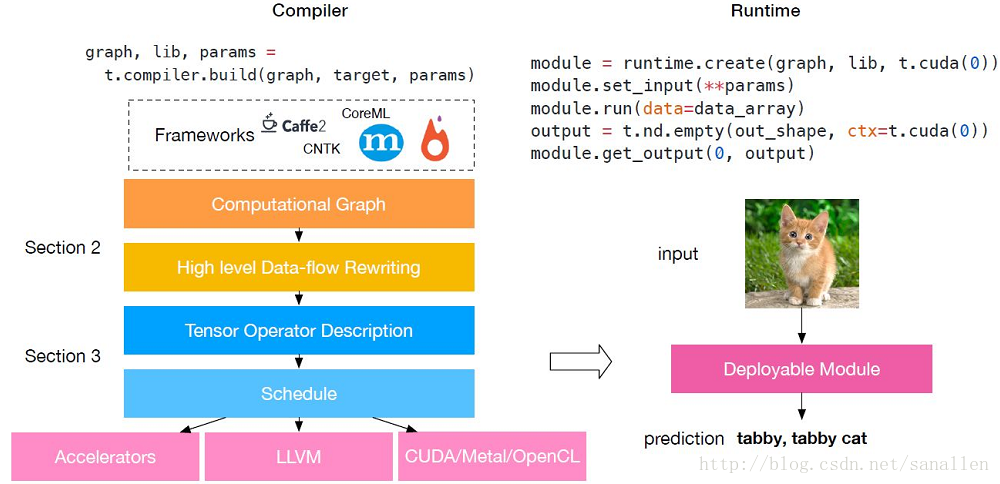
TVM是一個端到端優化堆疊,該端到端優化編譯器堆疊可降低和調整深度學習工作負載,以適應多種硬體後端。TVM 的設計目的是分離演算法描述、排程和硬體介面。該原則受到 Halide [22] 的計算/排程分離思想的啟發,而且通過將排程與目標硬體內部函式分開而進行了擴充套件。這一額外分離使支援新型專用加速器及其對應新型內部函式成為可能。TVM 具備兩個優化層:計算圖優化層,用於解決第一個排程挑戰;具備新型排程基元的張量優化層,以解決剩餘的三個挑戰。通過結合這兩種優化層,TVM 從大部分深度學習框架中獲取模型描述,執行高階和低階優化,生成特定硬體的後端優化程式碼,如樹莓派、GPU 和基於 FPGA 的專用加速器。該論文做出了以下貢獻:
我們構建了一個端到端的編譯優化堆疊,允許將高階框架(如 Caffe、MXNet、PyTorch、Caffe2、CNTK)專用的深度學習工作負載部署到多種硬體後端上(包括 CPU、GPU 和基於 FPGA 的加速器)。
我們發現了提供深度學習工作負載在不同硬體後端中的效能可移植性的主要優化挑戰,並引入新型排程基元(schedule primitive)以利用跨執行緒記憶體重用、新型硬體行內函數和延遲隱藏。
我們在基於 FPGA 的通用加速器上對 TVM 進行評估,以提供關於如何最優適應專用加速器的具體案例。
我們的編譯器可生成可部署程式碼,其效能可與當前最優的特定供應商庫相比,且可適應新型專用加速器後端。
2 優化計算圖
2.1 計算圖
在深度學習框架中計算圖是一個表示程式的常用方式。下圖展示了一個使用計算圖表示一個2層的卷積神經網路:
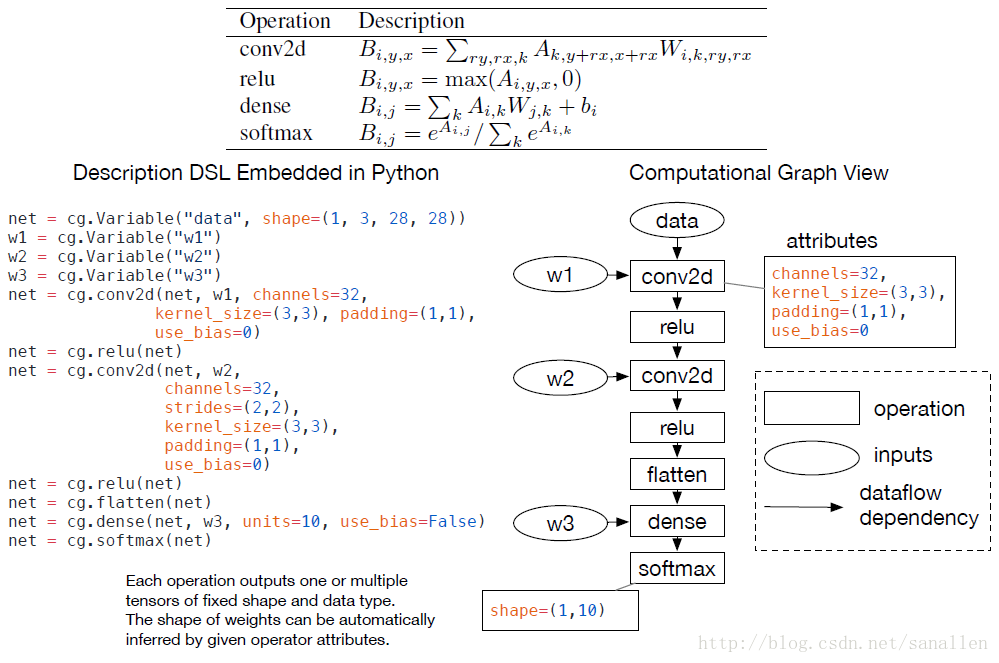
高層次表示和底層的編譯器中間表示(IR,像LLVM)的主要不同在於中間資料是大資料量的多維Tensor。TVM採用了在一個計算圖表示上使用高層次優化的方案:node代表tensor操作,edges代表tensor之間的資料流向和資料依賴關係。
計算圖為計算任務提供了一個全域性檢視,同時也避免了描述每個計算任務具體是如何實現的。在一個圖中,靜態記憶體計劃Pass能夠通過預分配所有中間結果Tensor來處理。這個分配階段和傳統編譯器中的暫存器分配Pass類似。和LLVM IR類似,一個計算圖應該能夠被轉換成函式公式圖。例如,一個常數摺疊Pass能夠在計算圖預計算階段被靜態地執行,以節省執行時代價。下圖展示了在一些TVM中實現的新穎的圖層次優化:操作符融合和資料佈局轉換。
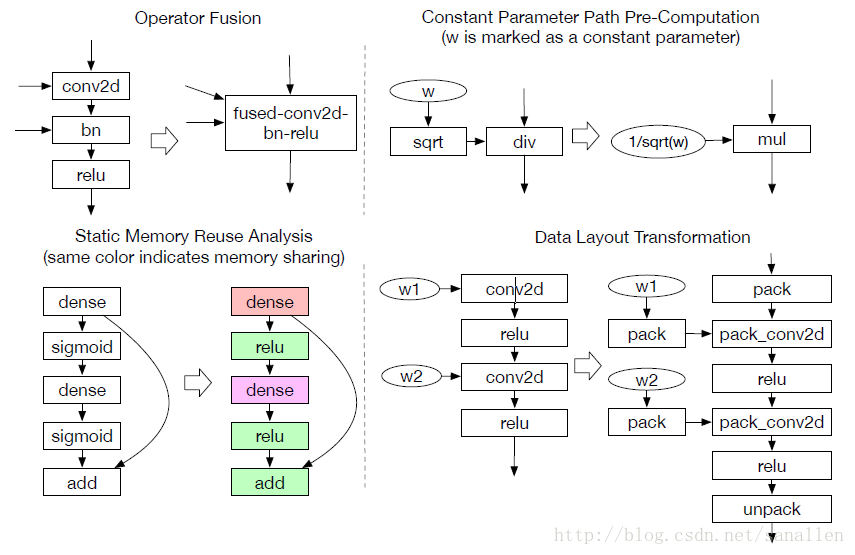
2.2 操作符融合
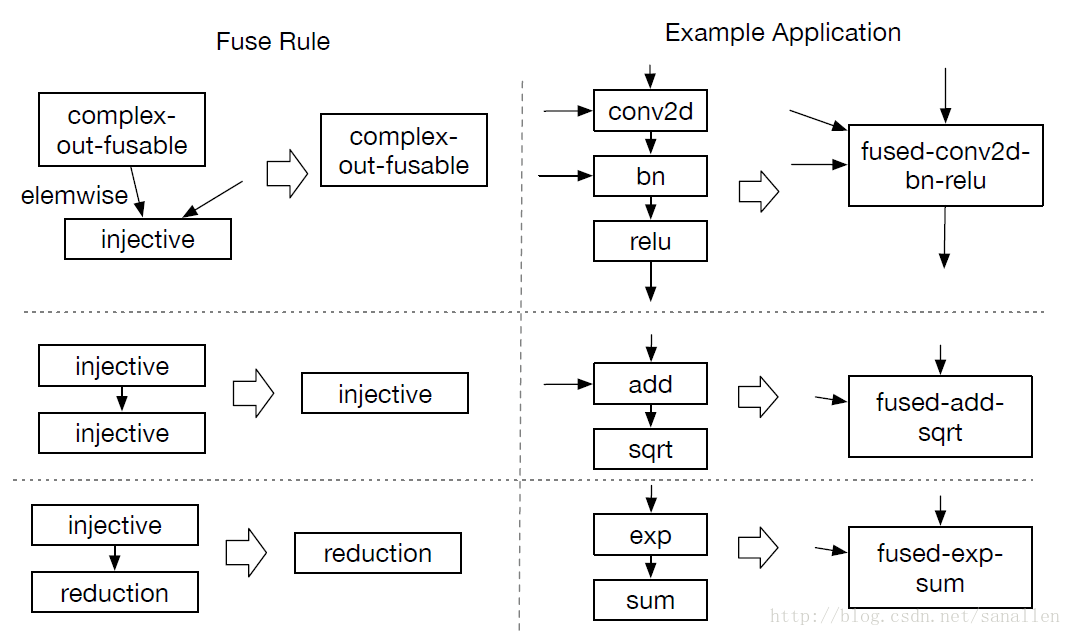
對於GPU和特定加速器而言,將多次操作融合在一起的優化方法能較為明顯地降低執行時間。操作符融合的想法是來源於單個Kernel函式會節省將中間結果寫回全域性記憶體的時間消耗。從具體分析來看,我們總結了四種類別的圖操作符:
- injective(one-to-one map):單射,如add/sqrt/sub
- reduction:約簡,如sum/max/min
- complex-out-fusable(can fuse element-wise map to output),如conv2d
- opaque(cannot be fused)
下圖展示一個使用操作符融合進行圖優化的示例:
下圖展示了3種工作負載經過操作符融合之後的效能對比:
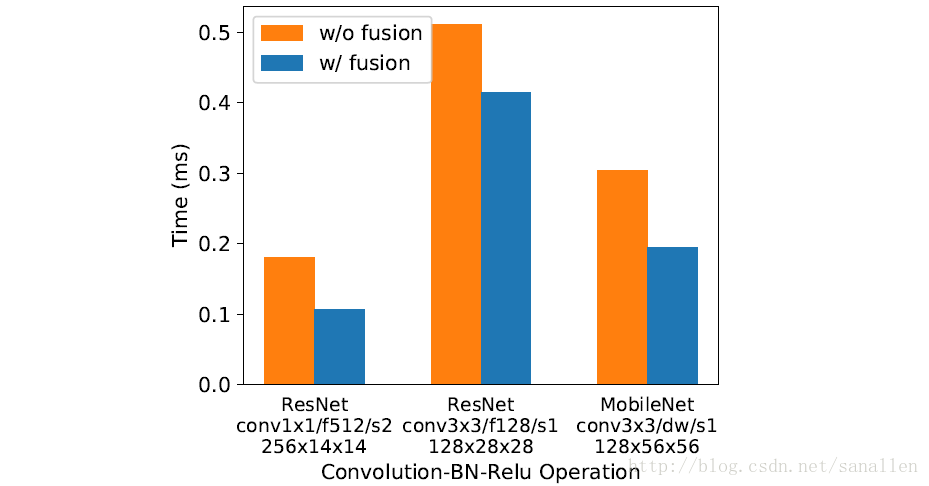
2.3 資料佈局轉換
Tensor操作是計算圖的基本操作符,Tensor中涉及到的運算會根據不同的操作符擁有不同的資料佈局需求。例如,一個深度學習加速器可能會使用4x4張量操作,所以需要資料切割成4x4的塊來儲存以優化區域性訪存效率。下圖展示了一個矩陣如何佈局,這種佈局能夠適應計算2x2張量操作:
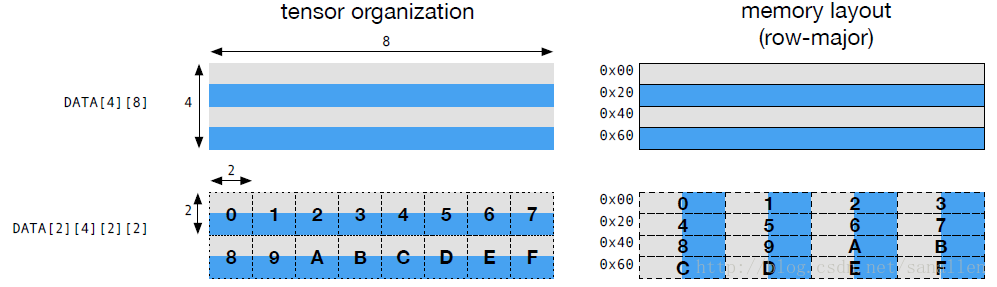
對於優化資料佈局而言,需要為每個操作符提供定製的資料佈局。如果在producer(生產者)和consumer(消費者)之間出現了資料佈局不匹配的情況時,此時需要我們進行資料佈局轉換。
2.4 計算圖級別優化的限制
雖然高層次的資料流圖優化能夠大大提升深度學習的計算效率,但是它們和現有的Operator庫相關。當前,只有少量的深度學習框架支援操作符融合。隨著越來越多支援正交基的操作符被引進,能夠被融合的Kernel數量正在急劇增大。但是當出現越來越多的硬體後端時,為不同的資料佈局方式、資料型別和硬體行內函數手動適配的方案已經變得不可行的。為此,我們提出了一種程式碼生成的方案,將在下一章介紹這種方案。
3 優化張量操作
此章描述瞭如何為廣泛的硬體後端生成優良的操作符版本程式碼
3.1 Tensor表示式語言
這裡我們介紹一種能夠進行自動程式碼生成的資料流Tensor表示式語言。和高層次計算圖語言不同,Tensor操作的實現是不透明的(這裡可以理解為Tensor描述和實現是分離的)。每個操作被描述為一個數學表示式,例如:

註解:
- Recurrence:迴圈
- cumsum:矩陣元素累計和
我們的Tensor表示式語言借鑑了一些已有的程式語言,像Halide,Darkroom和TACO。我們的Tensor表示式語言支援一般的算術和數學操作符。我們也引進了滿足交換律的Reduction操作符,這個操作符能夠輕鬆地進行跨執行緒排程。之後我們還會引進一個高層次的掃描操作符,這個操作符能夠把基礎計算操作符聯合成窗體迴圈計算。TVM計算操作符也支援Tensor元組(可以理解多個Tensor輸入或者輸出),這樣有利於支援像argmax這種函式。總結陳述一下,所有Tensor操作被表示為高層次資料流圖並且覆蓋深度學習常用的計算模式。
3.2 排程空間
上一節已經陳述瞭如何描述Tensor表示式,但是如何為硬體後端建立高效能的實現依然是具有挑戰性的。這裡展示一個為CPU/GPU/深度學習加速器進行典型優化的示例:

上面的示例為矩陣乘法的CPU/GPU/深度學習加速器的實現
每個經過底層優化的程式針對不同硬體後端採用不同的排程策略的聯合,這也為Kernel設計者帶來了很大的負擔。所以通過借鑑Halide,我們採用瞭解耦計算描述和排程器優化兩個過程。排程器會根據硬體後端採用特定的規則將計算描述向下轉換成已優化的硬體實現。TVM的排程空間可以展示在下圖中:
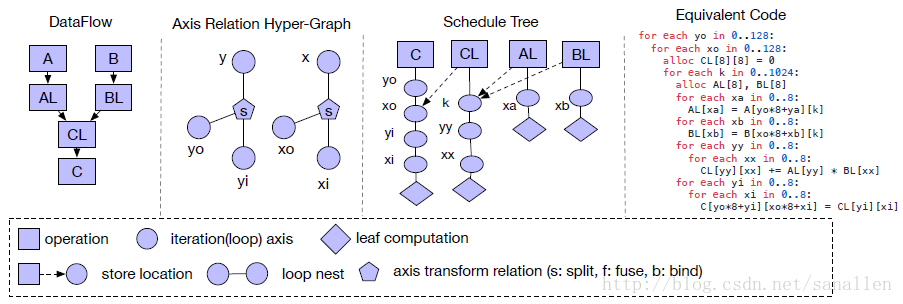
這個示例展示了一個Tiled(使用分塊)的矩陣乘法
為了更好地快速展示排程空間,我們需要提供有效的排程器基元。下圖將展示一系列TVM常用的排程器基元,這些基元經過實踐調整之後具有很高的計算效能:
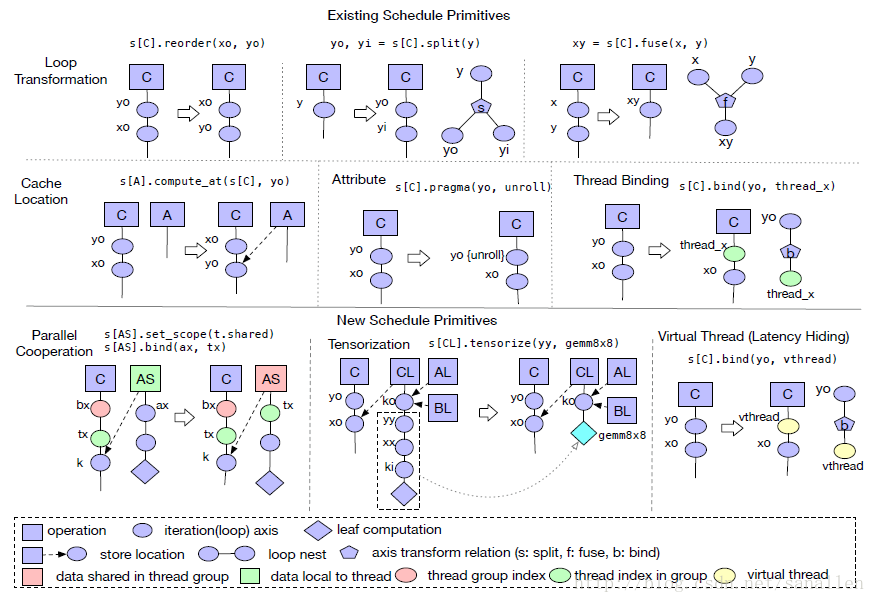
我們採用一些Halide中有效的排程器基元,另外引進了一些新的排程器基元Tensorization/Virtual Thread。接下來將會詳細介紹這些排程器基元。
3.3 協作式巢狀並行化
針對深度學習工作負載而言,並行程式設計的關鍵是改善計算密集型Kernel的計算效率。現代GPU提供了大規模的並行化,需要我們將並行編譯模型加入到排程器裡面。大部分現有的解決方案都是採用了巢狀並行編譯的方法,是一種fork-join的並行模式。具體而言,我們能使用一個並行排程器基元來處理一個數據並行任務。每個並行任務都能夠被遞迴地細分到一個子任務以實現多級執行緒。
我們稱這種模型為 shared-nothing nested parallelism,即一個工作執行緒不能觀察到相同計算階段內的相鄰執行緒的資料。相鄰執行緒之前的互動只能發生在join階段,join發生在子任務結束並且下個階段所需的資料已經準備好時。這種程式設計模型禁止執行緒在相同計算階段內進行協作。下圖展示了一個遵循這種限制的矩陣乘法示例:
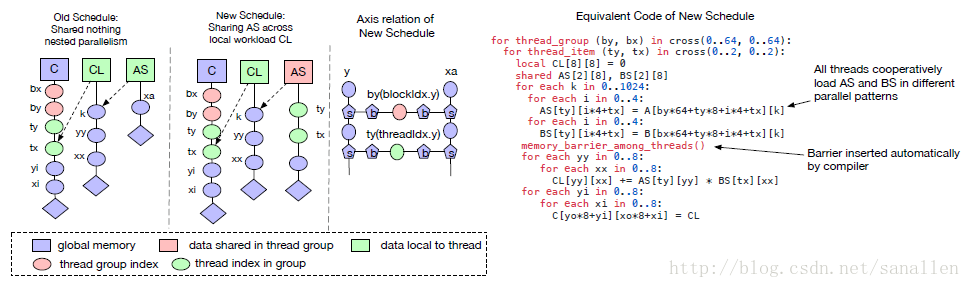
在一個GPU上矩陣乘法一般會被切割成小分塊,每個分塊指定一個執行緒組。如果使用shared-nothing nested parallelism的話,每個執行緒在Reduction階段就需要保證獲取的資料是獨立無依賴的。
一個更好的替代方案是執行緒在獲取資料時採用shared-nothing的手段。這種模式被使用在一些流行度非常高的GPU程式語言中,例如CUDA,OpenCL和Metal,但是沒有一個排程器基元採用這種手段。我們將memory scopes的概念引進到排程器空間,可以標記一個階段是可共享的。如果不指定memory scopes,自動Scope推理機制將會標記相關的階段是thread-local的,如下圖所示:
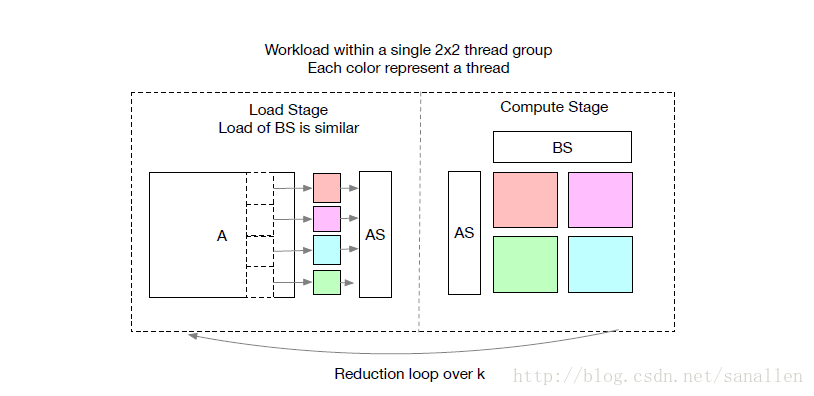
共享的任務需要計算所有組內工作執行緒的依賴關係,我們可以通過分發載入任務到一組執行緒從而有效地的排程資料載入任務。我們強制使用相同的執行緒工作在共享任務的一個專區上是非常不值得的,需要保證執行緒能持續在載入階段和計算階段之間切換。這種改進的實現需要額外的編譯器支援。具體來說,需要設計一個處理範圍約束的推理演算法,這個演算法能夠推斷出共享任務的範圍,能夠把具有協作關係的執行緒合併在一起。另外,記憶體同步屏障也需要正確地被插入以確保這些共享的資料對資料的消費者可見。
下圖展示了shared-nothing nested parallelism和with cooperation在GPU上面的效能對比,另外也加入了TVM和Halide的對比資料:
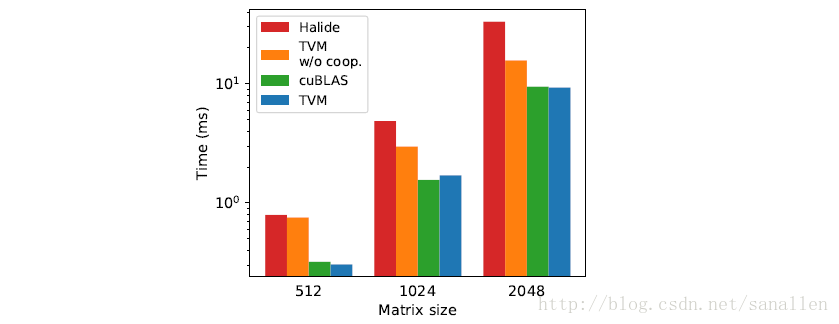
從上面的效能對比資料來看,我們發現採用新排程器基元的方案在GPU上取得了最佳的效能。最後,上面介紹的memory scopes的概念也可以引進到針對特定深度學習加速器的程式碼生成過程中。
3.4 張量化:生成硬體介面
深度學習工作負載擁有比較高的計算密度,這些計算可以被典型地分解成Tensor操作,像矩陣-矩陣乘法或一維卷積。這些自然的分解引領了當前新增Tensor操作基元的趨勢,這些新興的計算原型是相當多種多樣的,包括矩陣-矩陣乘法、矩陣-向量點乘、一維卷積等等。這些新的基元對於Tensor操作排程提出了新的挑戰:排程器必須使用這些基元從而獲得它們的加速特性。我們稱之為Tensorization問題,類似於SIMD架構下的向量化問題。
Tensorization顯著地不同於Vectorization。Tensor計算基元的輸入是多維資料,可能是固定長度或者變長,並且存在不同的資料佈局。更重要的是我們不能依靠於一組固定的基元,因為新的深度學習加速器採用特殊的Tensor指令。因此我們需要一個解決方案用來支援未來新的特定的加速器。
為了解決上面的問題,我們從排程器中分離了硬體介面。具體來說,我們引進了一套Tensor內聯宣告機制。我們可以使用Tensor表示式語言來宣告每個新的硬體內聯的行為,和給他分配底層原語是一樣的。另外我們引進了一個排程器基元Tensorization來作為基元的計算單元。下圖展示了一個Tensorization的示例:
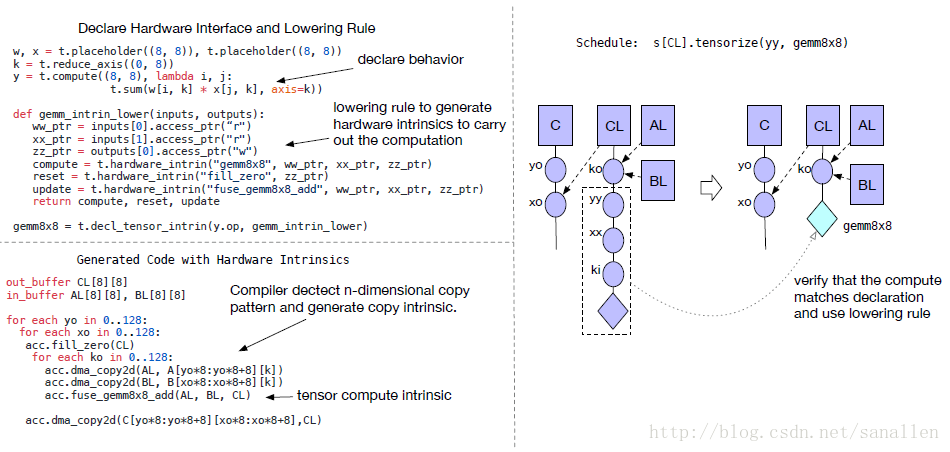
Tensor表示式語言能夠同時描述使用者準備的計算描述資訊和硬體暴露介面的抽象資訊。Tensorization把排程器從硬體基元中解耦出來,這樣能夠使TVM更容易擴充套件新的硬體架構。Tensorization排程器生成的程式碼經過實踐具有很高的計算效能:將複雜的操作分解成一系列重複的微型Kernel呼叫。因此我們能夠使用Tensorization基元來發揮手工製作的彙編微型Kernel的效能優勢,這種方法在一些硬體平臺上是非常有益的。例如,在AMD Vega GPU上,通過Tensorizing半精度GEMM到一個手動製作的4x4微型Kernel獲得1.5倍的效能加速效果。
3.5 編譯器的延遲隱藏支援
延遲隱藏指的是針對一個在計算過程中重疊記憶體操作的過程最大化訪存和計算利用率。針對不同的硬體它需要採用不同的策略。對於CPU而言訪存延遲隱藏通過同步多執行緒或者硬體預取技術達到。對於GPU而言,則通過成千上萬的執行緒組快速切換達到訪存延遲隱藏。對於特定深度學習加速器,經常會傾向於使用精簡控制流和編譯器堆疊。
下圖展示了編譯器如何在一個流水線式深度學習加速器中顯式地處理資料依賴:
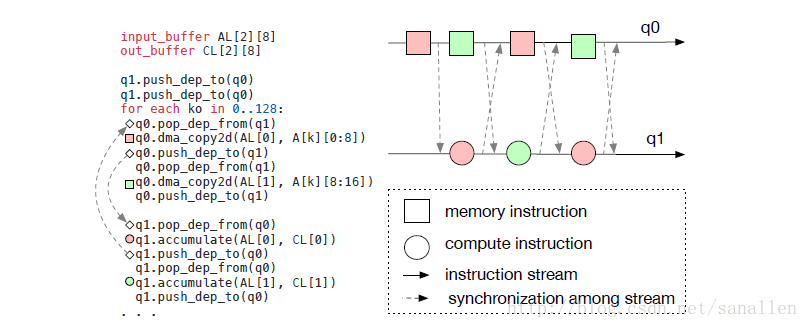
上面的示例遵循了運算/訪存分離的哲學。
4 程式碼生成和執行時支援
經過排程器優化之後,接下來的任務就是生成能執行在特定硬體平臺下的程式碼,並且方便已生成Kernel的部署和效能分析。
4.1 程式碼生成
對於一個特定的多元資料流宣告,座標系相關的超圖和排程樹,我們可以通過迭代遍歷排程樹的方案生成Lowered程式碼,並且推斷出輸入Tensor的依賴範圍(使用座標系相關的超圖),接下來生成迴圈巢狀的low-level程式碼。low-level程式碼是通過類C的迴圈程式具象化而來,在這個過程中我們使用了一個Halide迴圈程式資料結構的變體,我們也使用了Halide常用的lowering primitives,像是storage flattening,迴圈展開,對於GPU和特定深度學習加速器而言,則使用了同步點檢測、虛擬執行緒注入、模組化生成機制。最終,迴圈程式被翻譯成LLVM/CUDA/Metal/OpenCL原始碼。
4.2 執行時支援
對於GPU程式而言,我們會獨立的構建host端和device端的模組並且提供一個執行時模組系統來啟動Kernel。我們也為基於FPGA的深度學習加速器構建了一套驅動程式,這套驅動程式使用C語言API,可以實現構造指並推送到目標加速器上執行。我們的程式碼生成演算法然後將加速器程式翻譯成一系列Runtime API。
4.3 自動調優
本篇論文著重於提供一套新穎的優化框架,這套框架能夠為深度學習系統編譯高效能底層實現。我們已經完成的優化效果給我們展示了對於排程器生成高效能程式碼而言還有很大的值得探索的空間。我們正在探索一個非常早期的自動排程器技術和一個自動內聯注入操作的Pass。像高維卷積、矩陣乘法和深度卷積這樣的複雜操作可以被一套排程器模板進行自動調優。我們相信結合我們更精細化的優化技術,在未來還會有效能改善。
觀點:雖然從現階段來看自動調優的效能還不是很理想,但是能預測到硬體效能的自動調優可能是未來的一個大方向。所以fackbook也開源了TensorComprehensions,可以預想到不久之後自動調優很有可能會超過人類專家手動調優的水平。
4.4 遠端部署效能分析
為了嵌入式裝置,TVM設計了一套方便效能分析和自動調優的基礎設施。傳統情況下,嵌入式開發一般是在主機上進行交叉編譯然後複製可執行檔案到目標裝置上執行,上述編譯、執行和效能分析的工作都需要手動進行。在編譯器堆疊中我們提供了一個遠端程式呼叫:通過RPC介面,我們能夠完全在host端完成上面的所有步驟,這樣的方式可以極大地加快在嵌入式裝置和基於FPGA的加速器上的優化工作。
5 評估
我們主要在如下硬體平臺對TVM進行了評估:
- 嵌入式ARM CPU
- 服務端NVIDIA GPU
- FPGA深度學習加速器
效能評估程式是基於真實的深度學習工作負載,包括ResNet和MobileNet。並且選取了MxNet和Tensorflow作為對比框架。
5.1 樹莓派3B評估
我們在樹莓派3B(4核Cortex-A53 1.2Ghz)上面評估了TVM的效能,我們使用了MxNet作為基準系統。

5.2 NVIDIA Tesla K80和GTX1080評估
待補充…
5.3 PYNQ FPGA開發板評估
待補充…
6 相關工作
Tensorflow/CNTK/Theano/MxNet這些深度學習框架為使用者提供了便捷的深度學習工作負載體驗介面,可以容易地將深度學習模型部署到不同的硬體平臺。然而現有的深度學習框架都依賴於廠商獨立定製的Tensor操作庫,現在這些框架能利用TVM軟體堆疊為大量種類的硬體裝置生成優化良好的底層實現程式碼。
高層次計算圖DSLs也是一個表示和執行高層次優化的典型方法。Tensorflow的XLA和之前介紹的DLVM都是屬於這個類別。在這些工作中,計算圖的表示方法是類似的,另外在本篇論文中我們也介紹我們的高層次計算圖DSL。當圖層次的表達能夠很好地和高層次優化匹配的話,也意味著這些DSL對於大量不同種類的硬體後端Tensor操作層面來說已經層次太高了。之前的工作都是依賴於定製lowering規則來直接生成底層的LLVM中間碼或者硬體廠商手工指定的庫。這些方法為了做到多後端裝置相容需要花費大量的工程化投入。
Halide比較明智地採用了計算和排程分離的策略,我們順理成章地在我們的編譯器中採用了Halide的內在思想和現有的有效排程器基元。Tensor操作排程也參考了其他一些為GPU設計的DSL,這些DSL採用了polyhedral-based loop transformation(基於多面體的迴圈轉換)的方案。另外TACO這款軟體提出了一種在CPU上實現生成稀疏Tensor操作的通用方法。Weld是一個用來描述資料處理任務的DSL。我們主要集中處理一些在GPU和特定加速器上的深度學習工作負載的排程挑戰。我們的排程器基元有可能被這些工作負載的任務所採用。更重要的是,我們提供了一個端到端的軟體堆疊,能夠直接從深度學習框架的描述檔案生成優化良好的目標實現程式碼。
當前的比較流行的趨勢是特定領域的定製深度學習加速器的大量出現,現在還沒有編譯器堆疊去適配這些新的硬體裝置。VITA被設計成可以提供了對這些硬體加速器的通用支援。本篇論文為這些特定加速器提供了一個通用有效的解決方案。
7 致謝
原文略,不過值得讚賞的是TVM得到了陳天奇的谷歌博士獎學金的支援。
8 結論
我們的工作是提供了一個端到端的軟體堆疊,可以解決多種硬體後端下的效能優化挑戰。我們希望我們的工作能夠促進更多關於程式語言、編譯的研究。另外TVM也帶來了深度學習系統的軟硬體協同設計的機會,我們已經開源了我們的TVM軟體堆疊,還將開源VITA加速器以鼓勵在這個方案更有意義的研究出現。