
HDFS物件儲存--Ozone架構設計
前言
現在做雲端儲存的公司很多,舉2個比較典型的AWS的S3和阿里雲.他們都提供了一個叫做物件儲存的服務,就是目標資料是從Object中進行讀寫的,然後可以通過key來獲取對應的Object,就是所謂的key-object的儲存.這樣的好處就在於使用者使用起來很方便的,不需要走冗雜的操作流程.但是本文所要闡述的則是HDFS中的物件儲存,對於這樣的需求,Hadoop作為一套完善的分散式系統,當然也要與時俱進,在HDFS-7240中進行了實現,目前此功能真在開發中,名叫Ozone,內部有很多的概念與業界的都是類似的,例如Bucket,Object等.下面是本人對於Ozone設計文件的一個譯文,可能會有翻譯不到位的地方,附上原文連結:
目錄
介紹
1.1 基本要求
1.2 大小要求高層次設計
2.1 與HDFS共享Datanode Storage儲存
2.2 Storage Container儲存容器
2.3 Storage Container Identifier儲存容器標誌符
2.4 Storage Container儲存容器服務的呼叫
2.5 Datanode中的Ozone Handler
2.6 Storage Container Manager儲存容器管理器具體實現
3.1 物件鍵值到儲存容器的對映
3.2 範圍分割槽Vs雜湊分割槽
3.3 bucket到儲存容器的對映
3.4 Storage Container儲存容器的要求
3.5 Storage Container儲存容器實現要點
3.6 Pipeline資料一致性未來工作
4.1 Ozone API
4.2 叢集層級API
4.3 Storage Volumes層級API
4.4 Bucket層級API
4.5 Object層級API引用
介紹
Ozone提供了一個key-object鍵值-物件儲存的服務,類似AWS的S3服務. Key和Object物件是隨機的位元組陣列.單個key的大小期望是小於1k,但是values物件可以從小到幾百位元組大到幾百兆.鍵值/物件被組織進了bucket的概念中.一個bucket擁有唯一的key集合.Bucket存在於Storage-Volume中,並且在Storage-Volume中擁有唯一的名字.一個storage volume擁有全域性唯一的名字.更近一步的說,storage volume對buckets和儲存的資料有配額上的限制.在私有云中,它可以被用來建立給使用者(例如home目錄),工程專案,或者租有者.管理員可以分配一定配額限制的私有storage volume給個體使用者或者公有的共享storage volume.在公有云中,多storage volume可以以獨立的配額分配在每個雲中.
一個bucket被2部分名字的組合唯一標識: storage-volumeName/bucketName
我們的模式類似於Azure Blob Storage(WASB).他們的bucket在每個帳戶中是唯一的.但是,我們用storage volume來取代了這個帳戶概念.因此相比之下,S3的bucket在所有帳號中保持唯一.
資料的組織結構可以以下面的圖形進行展示.
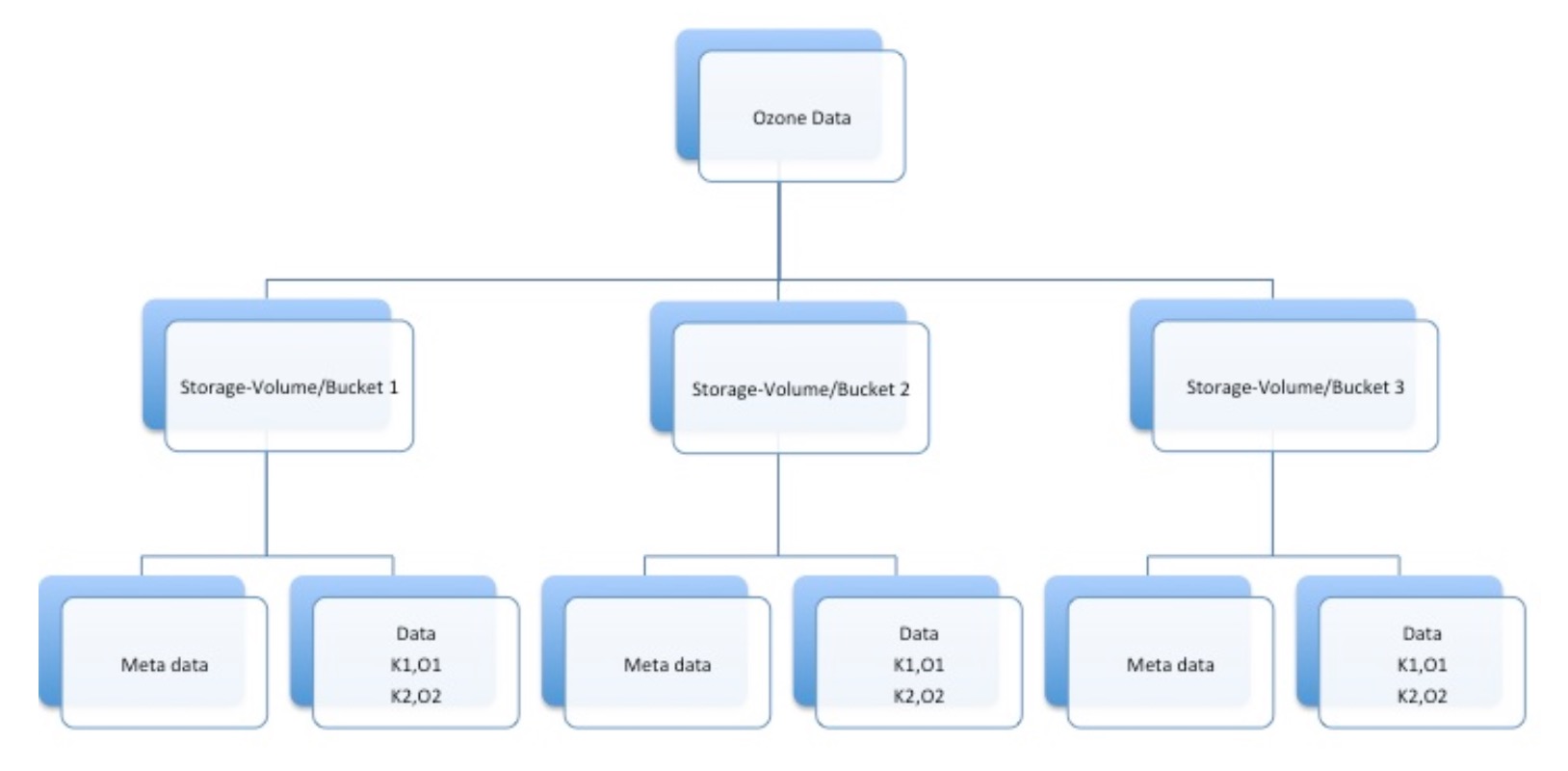
基本要求
Ozone中基本的操作如下(API方法在文件尾部將會給出):
- 管理員建立Storage Volume.
- 建立/刪除 buckets.每個bucket擁有一個獨立的URL.Buckets不能被重新命名.只有storage volume的所屬者或所屬組才能建立/刪除volume中的bucket.
- 在一個storage volume中列出buckets列表.
- 根據給定的key在bucket中建立/刪除object物件.物件的資料或值可以流式的傳輸到Ozone服務中.當物件被寫滿的時候將只會允許讀操作.同時不保證物件的區域性寫.
- 列舉出bucket的內容
- 建立/更新/刪除 buckets的ACL訪問控制列表
大小要求
本節列舉了少部分的限制值來具體化一些要求.下面是目標版本1的一些指標:
- Storage Volume名字: 3~64位元組
- Bucket 名稱: 3~64位元組
- Key大小: 1KB
- Object大小: 5G
- 系統總buckets數量: 1000w
- 每個bucket中物件數量: 100w
- 每個storage volume中的bucket數: 1000
Ozone元資料包括以下內容:
- Storage Volume層級元資料
- Storage volume所屬者
- Storage Volume名稱
- Bucket層級元資料
- Bucket所屬者: 擁有此bucket中資料的所屬使用者.
- Bucket ACL訪問控制資訊
- 全域性唯一的Bucket名稱
- Bucket Id: 與bucket相關的系統產生的數字型的標識
高層級設計
與HDFS共享Datanode資料儲存
DataNode同時為HDFS和Ozone儲存資料.Ozone的資料用的是獨立的blockPool並擁有獨立的blockPool Id.也就是說可以同時存在多種volume名稱空間,每個volume有屬於自己的block pool.同樣的可以同時存在多個獨立的Ozone名稱空間在所屬的block pool下.一個DN可以同時儲存多個HDFS和Ozone的block pool.此關係結構如下圖所示:
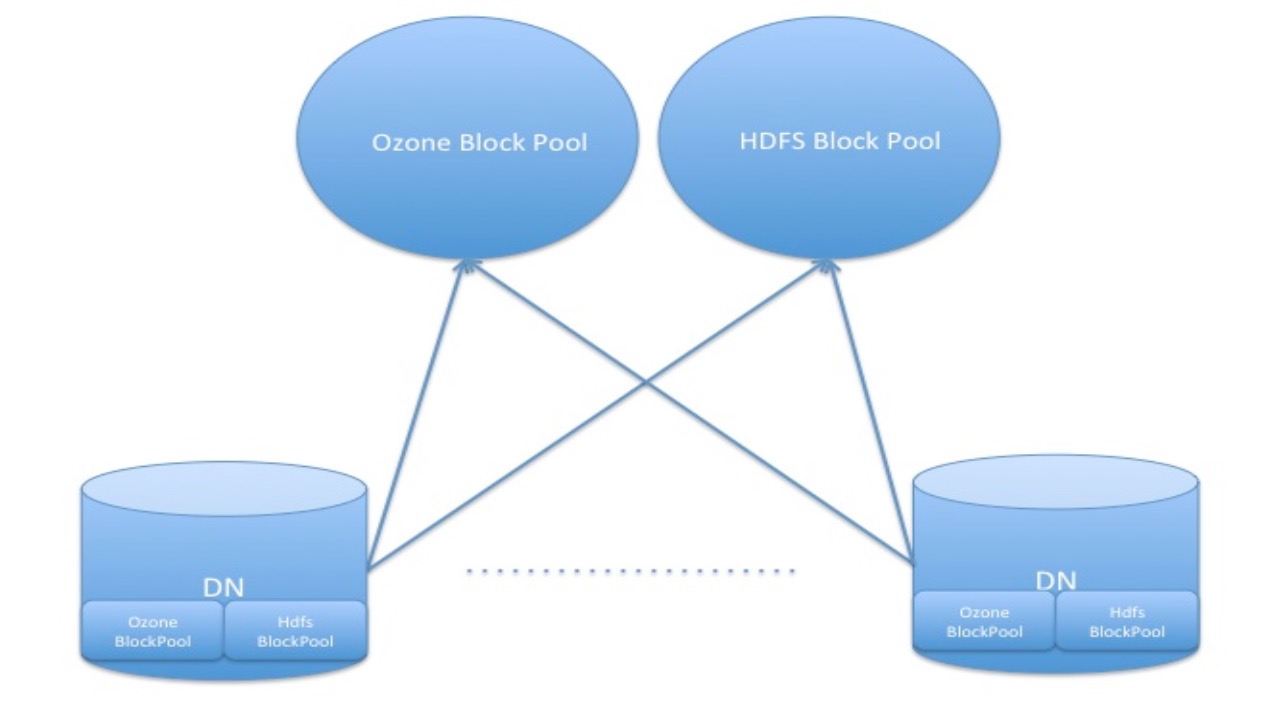
Storage Container容器
一個storage container從概念上來說,指的是用來儲存Ozone資料(就是bucket中的資料)和Ozone元資料的一個儲存單元.Storage container與HDFS的block一樣,共同儲存於DataNode上.但是與HDFS不同的一點,Ozone沒有一個類似於NameNode的中心節點,相反地,他是一個分離的元資料的儲存.這些元資料分散式的存在於各個storage container中.每個storage container以whole的形式存在(類似於HDFS中的block).我們對container副本的成功操作保證了強一致性.Storage container的最大值的大小取決於他的副本複製能力以及從節點故障中恢復的能力.最大值的大小是可配的,但是他至少要大於一個簡單物件所允許的最大值.
一個bucket可以擁有百萬數量級的物件並且在儲存的大小級別上可以達到T級別,這遠遠大於一個storage container.因此一個bucket會被分為很多partion分割槽,每片分割槽會儲存在一個container中.(一個storage container可以包含最大值數量的的分割槽,然而物件只能來自一個bucket.)在我們的初始設計實現中,一個object物件是完全存在於一個單一的container中,這麼做後面可能會輕鬆一些.
Storage container是靠DataNode來實現的(使用者可以通過配置來禁用此功能如果使用者只需要使用HDFS的block功能).本節定義了storage container的一些語義和要求.Storage container需要儲存以下多種型別的資料,每類資料有略微不同的語義:
Bucket元資料
- 個體單元的資料是非常小的-kb級別.每個storage container可以儲存上百萬bucket的元資料.
- 這點要求能夠更新,因為一個bucket的ACL是能夠被更新的,並且要能保證操作的原子性.
- 滿足基本的Get/Put的API設計已經足夠.
- 在container中能執行列表操作以便展示所有的bucket.
Bucket資料
- Storage container需要能夠儲存小到幾百kb大到上百mb的物件資料.
- 物件需要通過物件的key進行訪問(所以container儲存資料也必須包含儲存物件的索引).
- 必須能支援個體物件讀寫的流式API.
- 資料中的物件不支援追加寫以及原地更新.
在後面的小節,我們將闡述DataNode如何實現storage container來達到以上的要求.
Storage Container識別符號
每個storage container都被獨立的storage container識別符號所獨立標識.它是一個邏輯上的獨立標識(類似於HDFS中的blockId)並且不包含真正意義上container的網路位置.
物件的key會對映到storage container識別符號.這個識別符號會傳入storage container manager管理器去定位包含目標物件container所在的DataNode.類似的,bucket的名稱也會對映到storage container識別符號,這個container儲存有bucket的元資料.在後面的小節中,我們會具體提到這個對映關係是如何實現的.Storage container識別符號是64位的,類似於hdfs中的block id.在未來,我們將把它擴充套件到128位.但是那將會是一個大的改變,因為我們想盡可能的複用hdfs的block管理器相關的程式碼.
Storage Container Service中的過程呼叫
下面的圖形展示了Ozone中的典型過程呼叫,其中主要包含了Storage Container Service服務和Ozone Handler處理器:
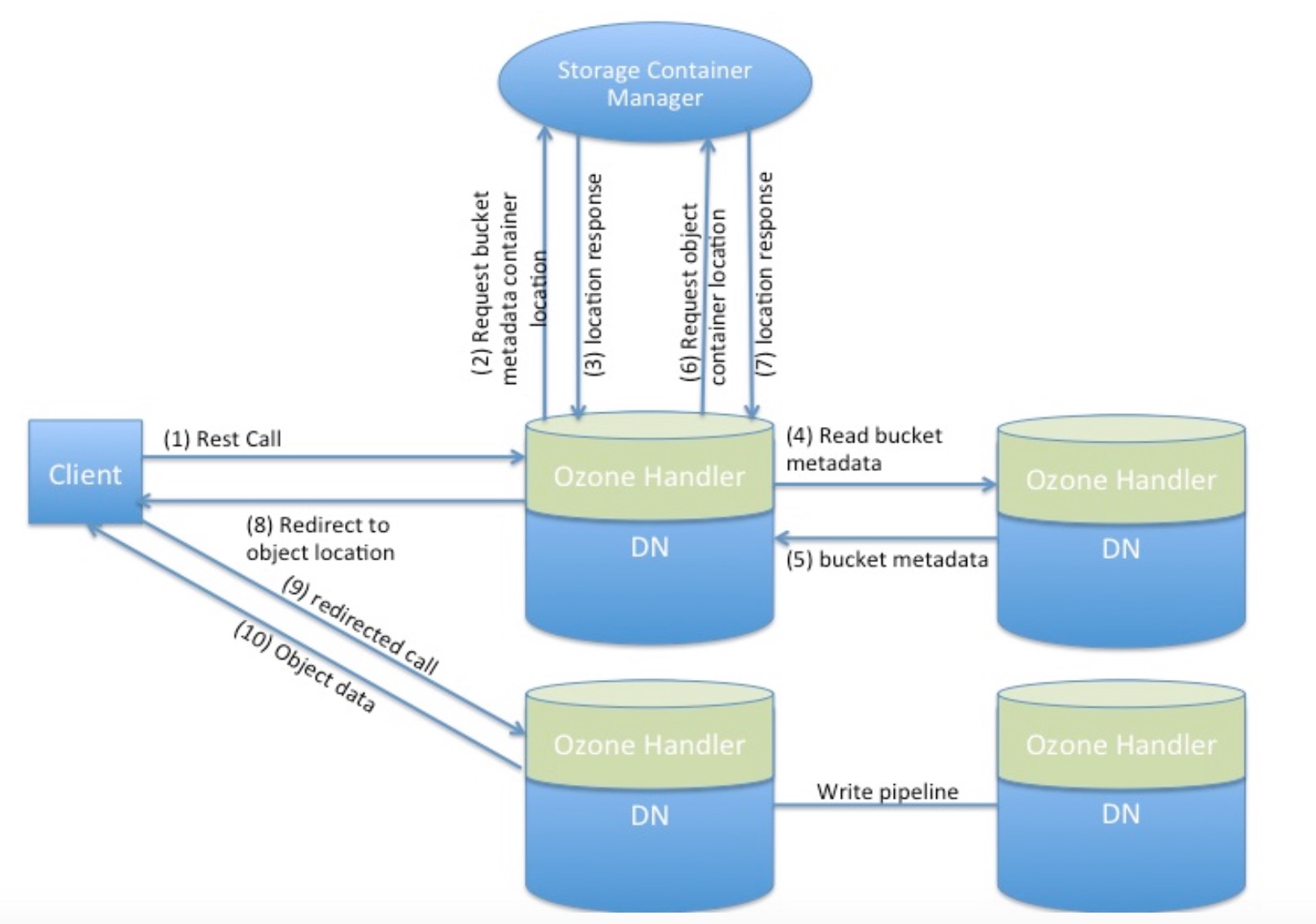
DataNode中的Ozone Handler
Ozone handler是Ozone中的模組元件,被DataNode所持有並對外提供Ozone服務.Handler包含了一個http server並實現了Ozone REST方式API.Ozone Handler與storage container manager管理器互動來查詢container的位置.與DataNode中的storage container互動實現不同的操作.這個功能元件可以被禁用如果使用者只想要使用HDFS而不需要Ozone功能.
Storage Container Manager管理器
Storage container manager管理器非常類似於HDFS中block manager中的管理功能.Storage container manager管理器從各個DataNode中收集心跳,處理storage container的報告並跟蹤每個storage container的位置.他包含了一個storage container對映圖,以此提供了字首匹配的方式去查詢storage container.之前提到過DN能夠同時儲存HDFS和Ozone的資料.Ozone的資料所屬的是分離的block pool並且用的是Storage container manager管理器提供的分離的blockPool Id.圖形展示效果如下.我們計劃儘可能的複用NameNode已有的block管理部分的程式碼實現來實現container的管理.我們同樣可以複用DataNode 中block pool service服務的實現程式碼.
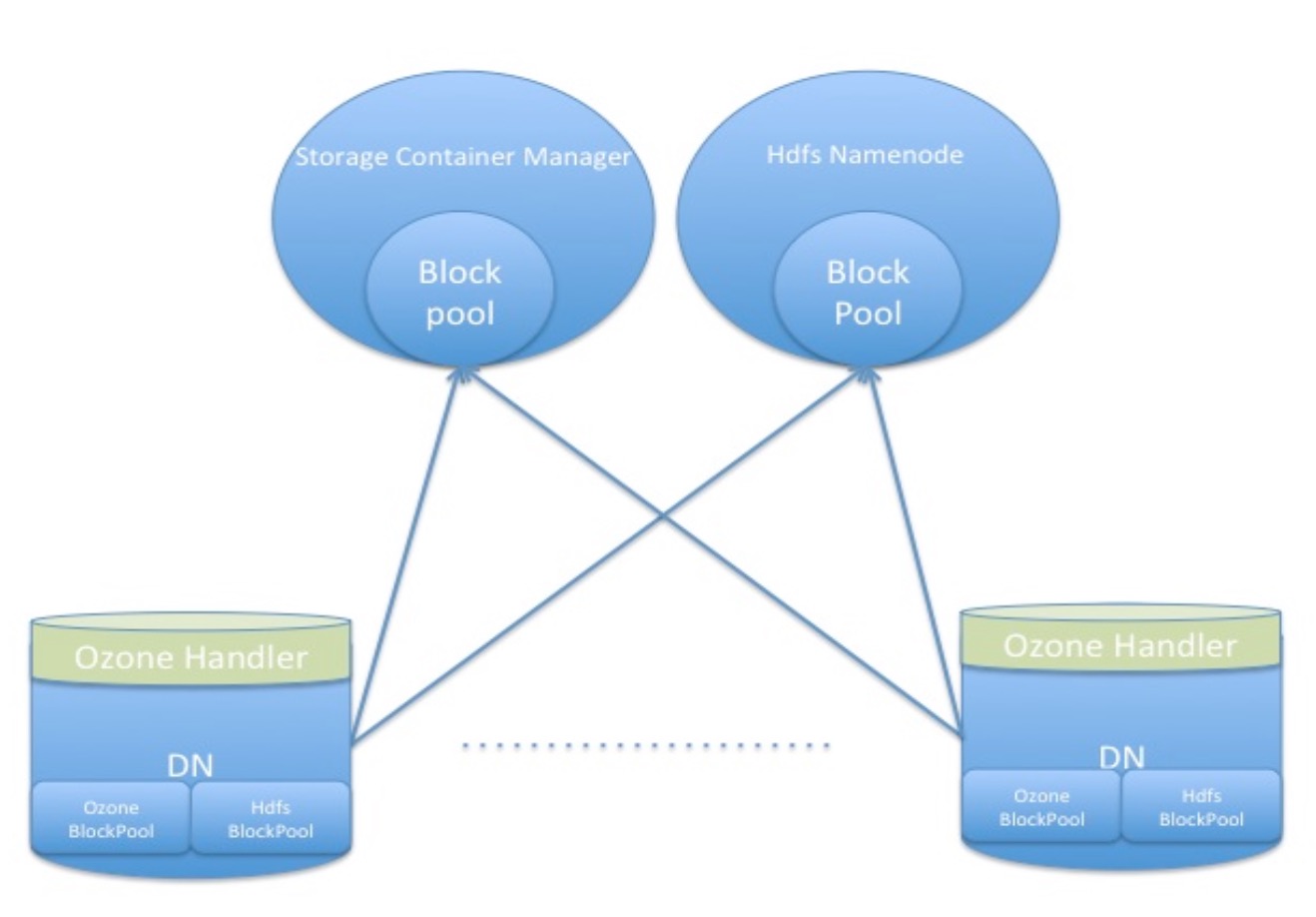
具體實現
對映object-key到storage container
在我們的設計中,我們計劃使用雜湊分割槽的模式來對映key到他所儲存的storage container.Key的值是被雜湊計算的,同時會帶上bucketId的字首.結果值通過字首匹配可以對映到storage container.當container逐漸變大,我們會對此進行分割,並用擴充套件雜湊演算法重新對映key到對應container的對映關係.Storage container manager管理器會儲存這些對映關係到字首樹中以此實現高效的字首匹配.每個bucket都有屬於自己的字首樹.
範圍分割槽 vs 雜湊分割槽
在資料庫和物件儲存中,範圍分割槽是另外一項比較受歡迎的用來對key進行分割槽的技術.以下是2個技術的簡短的比較.我們偏向於使用雜湊分割槽的方法,因為它相比較能更簡單的去實現並且能滿足我們的需求.
- 範圍分割槽模式需要範圍索引.範圍索引同樣非常巨大並且需要分散式的儲存.這複雜化了分割多個分割槽的操作,因為他額外需要索引的更新.
- 範圍分割槽在搜尋過程中多引進了一種額外的跳躍,當第一次範圍索引需要去讀.
- 範圍分割槽同樣有熱點問題.相似名字的key會造成相同範圍內的大併發量的訪問.
- 然而,範圍分割槽提供了有序訪問以及有序列表展示的優勢.但是我們認為對於一個物件儲存而言,一個有序的訪問並不是一個重要的要求.列表有序的展示可以在後面的階段內用二級索引的方式來實現.我們同樣相信對於目前的設計而言是足夠靈活的,如果我們在未來想要對此新增範圍索引的話.
對映bucket到storage container
Bucket的元資料同樣儲存在storage container中.Bucket的名字是被用來作為key做雜湊計算的.多個bucket的元資料可以存在於storage container中.我們在所有與storage container關聯的bucket中設計了一個特殊的bucketId,bucketId字首中會帶上container Id.
Storage Container要求
Storage Container儲存在各個DataNode上.對於Storage Container我們有以下的要求:
- Storage Container能夠可靠地被複制.
- Storage Container保持嚴格的一致性.
- Storage Container對於內部儲存的物件能提供高效的鍵值對的查詢方式.
- Storage Container必須能夠以流式的方式對object進行讀寫操作.
- Storage Container必須能夠支援get/put介面,來儲存和更新bucket元資料.
- Storage Container對於內部儲存的bucket必須能提供一個原子的更新操作.
- Storage Container能夠進行分裂當他們達到一定大小限制的時候.
Storage Container的實現要點
- 我們傾向於儘可能的複用HDFS現有的block pool管理方面的功能程式碼.因此我們會將StorageContainer作為Block類的擴充套件類.一個hdfs block由一個識別符號,生成時間記錄和大小組成.這3個屬性同樣可以應用到storage container中.
- 為了保證一致性和永續性,storage container實現了少量的原子性和持久化的操作,比如事務.Container對這些操作提供了可靠的保證.在第一階段中,我們實現以下事務操作:
- Commit: 這個操作促進了物件從被寫到最後的確認結束.一旦這個操作成功,這個container就會保證物件是可讀的.
- Put: 這個操作適用於小規模的寫操作,例如元資料的寫動作.
- Delete: 刪除物件.
- Container中的每個事務會有一個事務ID,並且必須被持久化.
- 我們計劃為storage container實現一個新的data-pipeline,因為他要求一個不同型別的更新和恢復語義操作.在下一小節中我們會給出data-pipeline的設計概述.
- 我們正在考慮利用leveldbjni來作為storage container的原型設計,leveldbjni正好能滿足我們storgae container鍵值對儲存的需求.
Data Pipeline一致性
Data-Pipeline管道鏈流式複製副本資料到container中.Container的副本也有產生記錄類似於HDFS的block.每個pipeline副本的標記記錄在pipeline建立的時候會被更新,所以任何舊的container會被撤銷.HDFS在block恢復的時候額外使用了block length副本長度來判斷副本是否已經更新到最新.類似地, storage container用了事務ID來判斷container副本是最新的.更多的pipeline設計細節將會上傳到對應hdfs jira上.
未來工作
我們並沒有在文件中仔細闡述下述的要求,但是我們將會在後面階段的工作中實現這些功能:
- High availability: 高可用性,Storage container manager管理器需要是高可用的服務.一個解決方案是利用HDFS Journal的QJM機制實現Active/Standby的方式.另外一種方式做成所有Active的服務配上Paxos環的方式.我們會在第二階段的工作中對這個問題進行社群內的討論.
- Security: 安全,我們可以利用HDFS的kerberos認證機制
- Cross cool replication: 跨型別副本拷貝,我們將會使用一種對HDFS和Ozone都有利的方式去實現這個功能.
Ozone API
Cluster層級APIs
- PUT StorageVolumes
- API - PUT /admin/volume/{StorageVolume}
- 建立一個storage volume
- 只有管理員才允許呼叫這個操作
- API - PUT /admin/volume/{StorageVolume}
- HEAD StorageVolume
- API - HEAD /admin/volume/{StorageVolume}
- 檢測Storage Volume是否存在
- 只有管理員才能呼叫這個操作
- API - HEAD /admin/volume/{StorageVolume}
- GET
- 列出叢集中所有的Storage Volume.
- DELETE Storage Volumes
- API - DELETE /amin/volume/{StorageVolume}
- 刪除一個volume如果他是空的
- API - DELETE /amin/volume/{StorageVolume}
Storage Volume層級APIs
- GET Buckets
- API - GET /
- 利用使用者的認證資訊登入
- 返回請求傳送者所擁有的buckets列表
- Get User Buckets
- API - GET /admin/user/userid
- 利用使用者認證資訊進行登入, 如果他/她有許可權閱讀其他使用者的資訊,返回那個使用者所獨有的buckets列表資訊.
- API - GET /admin/user/userid
Bucket層級API
- LIST objects in a bucket
- API - GET/{bucketName}
- 返回buckets中最多1000個數量的物件key
- API - GET/{bucketName}
- PUT bucket
- API - PUT/{bucketName}
- 為請求傳送者建立bucket
- GET/PUT Bucket ACL
- API - /{Bucket}?acl
- 允許使用者獲取/設定bucket的ACL
- API - PUT/{bucketName}
- HEAD bucket
- API - HEAD/{bucketName}
- 檢查bucket是否存在,前提是請求傳送者有許可權訪問此bucket
- DELETE bucket
- API - DELETE/{bucketName}
- 刪除bucket如果此bucket為空的話
- API - DELETE/{bucketName}
Object層級APIs
- GET object
- API - GET/{bucketName}/{key}
- 返回給定key所代表的物件值,如果這個值存在
- 在第一階段暫不支援ACL,因此只有所屬使用者才能讀寫自身的bucket.
- API - GET/{bucketName}/{key}
- PUT object
- API - PUT/{bucketName}/{key}
- 在bucket中建立一個物件
- 在第一階段暫不支援ACL,因此只有所屬使用者才能讀寫自身的bucket.
- 不支援區域性的上傳,只有物件全部上傳成功了才被認為是一次成功的操作.
- API - PUT/{bucketName}/{key}
- HEAD object
- API - HEAD/{bucketName}/{key}
- 檢測物件是否存在
- 在第一階段只有bucket的所屬使用者才能呼叫此操作
- API - HEAD/{bucketName}/{key}
- DELETE object
- API - DELETE/{bucketName}/{key}
- 刪除物件
- API - DELETE/{bucketName}/{key}