
中文分詞研究入門
導讀
本文首先簡單介紹了自然語言處理和科研過程中重要的四部曲——調研、思考、程式設計和寫作,然後對中文分詞問題進行了說明,介紹了中文分詞存在的難點如消歧、顆粒度問題、分詞標準等。接著,本文總結了調研文獻中的分詞方法,包括基於詞典的最大匹配法以及其相應的改進方法、基於字標註的分詞方法等,同時也介紹了當前中文分詞的研究進展和方向,如統計與詞典相結合、基於深度學習的分詞方法等。而後,本文具體介紹瞭如何基於詞典的雙向最大匹配法以及基於字標註的平均感知機進行分詞的實驗,對實驗結果進行了分析並給出了幾種改進模型的思路。最後,本文給出了相應的參考文獻以及其他資料。
1. 導論
1.1 自然語言處理簡介
自然語言處理(NLP, Natural Language Processing)是用機器處理人類語言(有別於人工語言,如程式設計語言)的理論和技術。自然語言處理是人工智慧的一個重要分支,屬於計算機應用技術(有別於計算機技術)。計算機應用技術作為二級學科所屬於一級學科計算機科學技術。自然語言處理又可以稱作自然語言理解或計算語言學。
自然語言處理是一個貼近應用的研究方向。NLP大致可分為基礎研究和應用技術研究。基礎研究包括詞法分析、句法分析、語義分析和篇章理解等;應用技術研究包括文字挖掘、自動問答、資訊檢索、資訊抽取、機器翻譯等。
1.2 科學研究方法
研究活動的大致流程可以遵循如下四個階段[1]:
- 閱讀 (Reading)
- 思考 (Thinking)
- 程式設計 (Programming)
- 寫作 (Writing)
第一階段閱讀大約佔整個過程的30%。收集並閱讀資料是研究過程的第一步。現在的資料浩如煙海,如何收集到有價值的資料極為重要。研究的資料主要是論文,我們應該閱讀重要的論文,而重要的論文往往具有以下一種或多種特徵:
- 發表在高水平(頂級)會議或期刊上:對於NPL領域,國際高水平會議包括ACL、EMNLP、COLING等,國內重要的NLP期刊如中文資訊學報;
- 引用數多;
-
近5年尤其是近3年的論文: 由於學術發展較快,我們應該閱讀最新的論文。
如何閱讀一篇論文?閱讀論文時應注意以下幾點:
- 以作者為線索理清脈絡: 閱讀論文時要注意論文作者和研究機構。以作者為線索理清該作者研究工作的脈絡,以此熟悉該研究方向。
- 抓住論文要害: 論文要害主要包括研究工作的目的、待解決的問題、解決問題的難點、針對問題難點的解決方法、該方法與其他方法的對比、該方法的不足等。
- 批判式閱讀: 每一篇學術論文都不是完美的,閱讀論文時應帶著批判的心理,在閱讀中不斷找出論文的問題或不足之處,並積極思考如何做可以更好的解決問題。
第二階段思考大約佔整個過程的20%。"學而不思則罔",在閱讀過程中以及閱讀後應該積極思考。
第三階段程式設計大約佔整個過程的20%。第一步是收集資料,資料可以是標準的評測資料,也可以是自己採集的真實資料。第二步是編寫程式,實現演算法。第三步是分析結果。
第四階段寫作大約佔整個過程的30%。寫作是科學研究的一個重要過程。論文是研究成果的體現,將自己的研究成果很好的展示給學術界,才能體現出研究的價值。
上述四個階段不是瀑布式而是螺旋式,是對研究的方向不斷深入的過程。
1.3 中文分詞問題介紹
中文資訊處理是指自然語言處理的分支,是指用計算機對中文進行處理。和大部分西方語言不同,書面漢語的詞語之間沒有明顯的空格標記,句子是以字串的形式出現。因此對中文進行處理的第一步就是進行自動分詞,即將字串轉變成詞串。
自動分詞的重要前提是以什麼標準作為詞的分界。詞是最小的能夠獨立運用的語言單位。詞的定義非常抽象且不可計算。給定某文字,按照不同的標準的分詞結果往往不同。詞的標準成為分詞問題一個很大的難點,沒有一種標準是被公認的。但是,換個思路思考,若在同一標準下,分詞便具有了可比較性。因此,只要保證了每個語料庫內部的分詞標準是一致的,基於該語料庫的分詞技術便可一較高下[3]。
分詞的難點在於消除歧義,分詞歧義主要包括如下幾個方面:
-
交集歧義, 例如:
研究/ 生命/ 的/ 起源
研究生/ 命/ 的/ 起源 -
組合歧義,例如:
他 / 從 / 馬 / 上 / 下來
他 / 從 / 馬上 / 下來
-
未登入詞,例如:
蔡英文 / 和 / 特朗普 / 通話
蔡英文 / 和 / 特朗 / 普通話
除了上述歧義,有些歧義無法在句子內部解決,需要結合篇章上下文。例如,"乒乓球拍賣完了",可以切分為"乒乓/球拍/賣/完/了",也可以切分成"乒乓球/拍賣/完/了"。這類分詞歧義使得分詞問題更加複雜。
詞的顆粒度選擇問題是分詞的一個難題。研究者們往往把"結合緊密、使用穩定"視為分詞單位的界定準則,然而人們對於這種準則理解的主觀性差別較大,受到個人的知識結構和所處環境的很大影響[3]。選擇什麼樣的詞的顆粒度與要實現具體系統緊密相關。例如在機器翻譯中,通常顆粒度大翻譯效果好。比如"聯想公司"作為一個整體時,很容易找到它對應的英文翻譯Lenovo,如果分詞時將其分開,可能翻譯失敗。然而,在網頁搜尋中,小的顆粒度比大的顆粒度好。比如"清華大學"如果作為一個詞,當用戶搜尋"清華"時,很可能就找不到清華大學。[10]
2. 中文分詞文獻調研
2.1 最大匹配法
樑南元在1983年發表的論文《書面漢語的自動分詞與另一個自動分詞系統CDWS》提到,蘇聯學者1960年左右研究漢俄機器翻譯時提出的 6-5-4-3-2-1 分詞方法。其基本思想是先建立一個最長詞條字數為6的詞典, 然後取句子前6個字查詞典,如查不到, 則去掉最後一個字繼續查, 一直到找著一個詞為止。樑南元稱該方法為最大匹配法——MM方法(The Maximum Matching Method)。由MM方法自然引申,有逆向的最大匹配法。它的分詞思想同MM方法,不過是從句子(或文章)末尾開始處理的,每次匹配不成詞時去掉最前面的字。雙向最大匹配法即為MM分詞方法與逆向MM分詞方法的結合。樑南元等人首次將MM方法應用於中文分詞任務,實現了我國第一個自動漢語自動分詞系統CDWS。[2]
2.2 複雜最大匹配法
複雜最大匹配演算法, 由Chen 和Liu在《Word identification for Mandarin Chinese sentences》提出[4]。該文提出了三詞語塊(three word chunks)的概念。三詞語塊生成規則是: 在對句子中的某個詞進行切分時,如果有歧義拿不定主意,就再向後展望兩個漢語詞,並且找出所有可能的三詞語塊。在所有可能的三詞語塊中根據如下四條規則選出最終分詞結果。
規則1: 最大匹配 (Maximum matching)
其核心的假設是:最可能的分詞方案是使得三詞語塊(three-word chunk)最長。
規則2: 最大平均詞長(Largest average word length)
在句子的末尾,很可能得到的"三詞語塊"只有一個或兩個詞(其他位置補空),這時規則1就無法解決其歧義消解問題,因此引入規則2:最大平均詞長,也就是從這些語塊中找出平均詞長最大的語塊,並選取其第一詞語作為正確的詞語切分形式。這個規則的前提假設是:在句子中遇到多字詞語的情況比單字詞語更有可能。
規則3:最小詞長方差(Smallest variance of word lengths)
還有一些歧義是規則1和規則2無法解決的。因此引入規則3:最小詞長方差,也就是找出詞長方差最小的語塊,並選取其第一個詞語作為正確的詞語切分形式。在概率論和統計學中,一個隨機變數的方差描述的是它的離散程度。因此該規則的前提假設是:句子中的詞語長度經常是均勻分佈的。
規則4:最大單字詞語語素自由度之和(Largest sum of degree of morphemic freedom of one-character words)
有可能兩個"三詞語塊"擁有同樣的長度、平均詞長及方差,因此上述三個規則都無法解決其歧義消解問題。規則4主要關注其中的單字詞語。直觀來看,有些漢字很少作為詞語出現,而另一些漢字則常常作為詞語出現,從統計角度來看,在語料庫中出現頻率高的漢字就很可能是一個單字詞語,反之可能性就小。計算單詞詞語語素自由度之和的公式是對"三詞語塊"中的單字詞語頻率取對數並求和。規則4則選取其中和最大的三詞語塊作為最佳的詞語切分形式。
最大匹配演算法以及其改進方案是基於詞典和規則的。其優點是實現簡單,演算法執行速度快,缺點是嚴重依賴詞典,無法很好的處理分詞歧義和未登入詞。因此,如何設計專門的未登入詞識別模組是該方法需要考慮的問題。
2.3 基於字標註的分詞法
2002年,Xue等人在《Combining Classifiers for Chinese Word Segmentation》一文中首次提出對每個字進行標註,通過監督機器學習演算法訓練出分類器從而進行分詞[5]。一年後,Xue在最大熵(ME, Maximum Entropy)模型上實現的基於字標註的分詞系統參加了Bakeoff-2003的評測獲得很好的成績引起關注。而後,Xue在《Chinese word segmentation as character tagging》一文中較為詳細的闡述了基於字標註的分詞法[6]。
基於字標註的分詞法基本思想是根據字所在詞的位置,對每個字打上LL、RR、MM和LR四種標籤中的一個。四種標籤的具體含義如下:
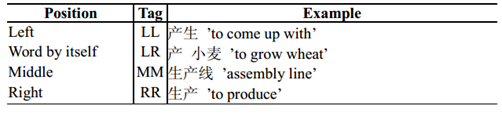
類似於詞性標註中的POS(part-of-speech) tags,我們稱上述字標籤為POC(position-of-character) tags。這樣,我們將分詞問題轉變成對漢字進行序列標註的問題。例如:

POC tags反映了的一個事實是,分詞歧義問題是由於一個漢字可以處於一個詞的不同位置,而漢字的位置取決於字的上下文。
字標註本質上是訓練出一個字的分類器。模型框架如圖1所示。
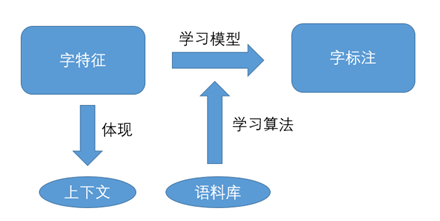
圖1 字標註訓練模型框架
設計字特徵的關鍵是包含足夠的上下文關係。黃昌寧等人在《中文分詞十年回顧》中提到,在[3]中所有語料庫99%以上的詞都是5字或5字以下的詞。因此,使用寬度為5個字的上下文視窗足以覆蓋真實文字中絕大多數的構詞情形。進一步,該文提到了一個確定有效詞位標註集的定量標準——平均加權詞長。其定義為:
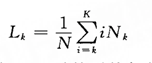
是i≥k時的平均加權詞長,是語料中詞長為k的詞次數,K是語料中出現過的最大詞長,N是語料庫的總詞次數。如果k=1,那麼代表整個語料的平均詞長。
經統計,Bakeoff-2003和Bakeoff-2005所有語料庫的平均加權詞長在1.51~1.71之間。因此,5字長的上下文視窗恰好大致表達了前後各一個詞的上下文。
Xue在[6]文給出瞭如下的特徵模板。

學習演算法是指監督機器學習演算法,常用的有最大熵演算法、條件隨機場(CRF, Conditional Random Fields)、支援向量機(SVM, Support Vector Machine)、平均感知機(AP, Averaged Perceptron)等。
基於字標註的分詞方法是基於統計的。其主要的優勢在於能夠平衡地看待詞表詞和未登入詞的識別問題。其缺點是學習演算法的複雜度往往較高,計算代價較大,好在現在的計算機的計算能力相較於以前有很大提升;同時,該方法依賴訓練語料庫,領域自適應較差。基於字標註的分詞方法是目前的主流分詞方法。
2.4中文分詞研究進展
2.4.1 統計與字典相結合
張梅山等人在《統計與字典相結合的領域自適應中文分詞》提出通過在統計中文分詞模型中融入詞典相關特徵的方法,使得統計中文分詞模型和詞典有機結合起來。一方面可以進一步提高中文分詞的準確率,另一方面大大改善了中文分詞的領域自適應性。[7]
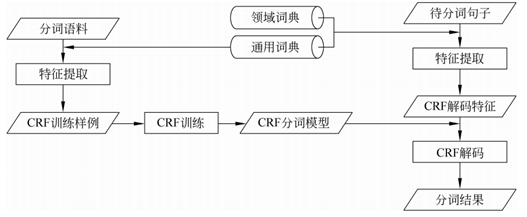
圖2 領域自適應性分詞系統框架圖
2.4.2基於深度學習的分詞方法
近幾年,深度學習方法為分詞技術帶來了新的思路,直接以最基本的向量化原子特徵作為輸入,經過多層非線性變換,輸出層就可以很好的預測當前字的標記或下一個動作。在深度學習的框架下,仍然可以採用基於子序列標註的方式,或基於轉移的方式,以及半馬爾科夫條件隨機場。[11]深度學習主要有兩點優勢:
- 深度學習可以通過優化最終目標,有效學習原子特徵和上下文的表示;
- 基於深層網路如 CNN、 RNN、 LSTM等,深度學習可以更有效的刻畫長距離句子資訊。
《Neural Architectures for Named Entity Recognition》一文中提出了一種深度學習框架,如圖3,利用該框架可以進行中文分詞。具體地,首先對語料的字進行嵌入,得到字嵌入後,將字嵌入特徵輸入給雙向LSTM,輸出層輸出深度學習所學習到的特徵,並輸入給CRF層,得到最終模型。[9]
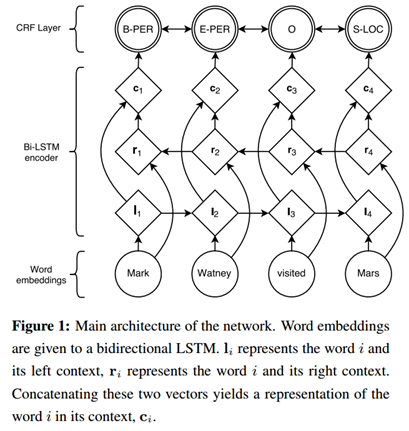
圖3 一個深度學習框架
3. 中文分詞方法實踐
3.1 基本思路
我們首先利用正則表示式提取URL、英文一類特殊詞,對文字資料進行預處理。而後分別實現雙向最大匹配法和基於字標註的平均感知機分詞兩個分詞模組並一起整合到分詞系統。在使用平均感知機進行分詞訓練時嘗試增加訓練資料集,如使用Bakeoff-2005的PKU訓練資料集和雙向最大匹配法的分詞結果進行增量訓練。
3.2 雙向最大匹配法
雙向最大匹配法即對句子分別用正向最大匹配和逆向最大匹配進行分詞,然後根據一定的規則選擇某一分詞結果。我們在實現是所制定的規則為:
- 如果正反向分詞結果詞數不同,則取分詞數量較少的那個;
-
如果分詞結果詞數相同:
- 分詞結果相同,可返回任意一個;
- 分詞結果不同,返回其中單字較少的那個。
3.3 基於字標註的平均感知機分詞方法
3.3.1 特徵設計
我們選擇5個字為上下文視窗大小,即:
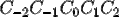
該上下文視窗包含如下7個特徵:

由於感知機的基本形式是二分類的,而字標註為四分類(多分類)。為了基於感知機實現多分類,將每個字的某一特徵權重設計為長度為4的向量,向量的每個分量對於某一分類的權值,如圖4所示。

圖4 字的特徵設計
3.3.2 演算法設計
對於預測演算法而言,如果是簡單的序列標註問題,那麼取得分最高的標籤即可,但是在中文分詞問題中,當前字的標籤與前一個字的標籤密切相關,例如若前一個字標籤為S(單字成詞),則當前字的標籤只可能為S或B(詞首),為了利用上述資訊,我們引入狀態轉移和Viterbi演算法。預測演算法的虛擬碼如圖5所示。

圖5 預測演算法虛擬碼
在使用隨機梯度下降法的訓練過程中,我們採取平均化引數方法防止某一訓練資料對結果影響較大。訓練演算法的虛擬碼如圖6所示。

圖6 訓練演算法虛擬碼
3.3.3 增量訓練
在增量訓練中,首先使用初始訓練語料訓練一個初始模型,然後結合初始模型以及增量語料進行增量訓練得到一個增量模型。增量訓練可以提高分詞系統的領域適應性,進一步提高切分中文分詞準確率, 同時避免了對初始語料的需求以及使用全部語料訓練模型所需要的時間。[8]模型增量訓練流程圖如圖7所示:
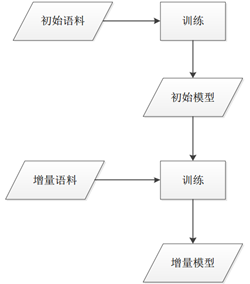
圖7 模型增量訓練流程圖
3.4 實驗結果及分析
表1給出了不同模型下測試資料1(130KB)的評測結果。該測試資料為新聞文字。從表1中可以看出,雙向最大匹配的分詞結果還算不錯,並且演算法效率高。平均感知機模型在使用Bakeoff2005的PKU訓練集進行增量訓練後效果提升顯著,同時需要花費額外的訓練時間。最後我們希望結合統計與詞典的優點,嘗試使用最大雙向匹配分詞結果集進行增量訓練,分詞結果有少量提升但並不明顯。
表2給出了不同模型下測試資料2(31KB)的評測結果。該測試資料為微博文字。從表2中可以看出,測試資料2的分詞結果比測試資料1的分詞結果差。並且,值得注意的是,基於平均感知機使用原始訓練集訓練出的模型分詞效果不太理想,而在增量訓練後效果提升非常顯著。這是微博文字相較於新聞文字更加不規範,新詞(如網路詞)更多等原因造成的。可以推測,若使用分詞標準一致的微博訓練集進行增量訓練,將進一步提高測試資料2的分詞結果。
表1 不同模型下測試資料1的評測結果
|
模型 |
訓練時間 |
測試時間 |
Precision |
Recall |
F-Measure |
|
雙向最大匹配 |
—— |
0.03s |
0.943 |
0.945 |
0.944 |
|
平均感知機 |
58.7s |
0.02s |
0.932 |
0.896 |
0.914 |
|
平均感知機+增量訓練(Bakeoff2005 PKU訓練集,6434KB) |
58.7s +568.1s |
0.02s |
0.944 |
0.941 |
0.943 |
|
平均感知機+增量訓練(Bakeoff2005 PKU訓練集6434KB+最大雙向匹配分詞結果集) |
58.7s +568.1s +37.4s |
0.02s |
0.952 |
0.941 |
0.947 |
表2 不同模型下測試資料2的評測結果
|
模型 |
訓練時間 |
測試時間 |
Precision |
Recall |
F-Measure |
|
雙向最大匹配 |
—— |
0.01s |
0.887 |
0.901 |
0.894 |
|
平均感知機 |
58.7s |
0.01s |
0.797 |
0.726 |
0.759 |
|
平均感知機+增量訓練(Bakeoff2005 PKU訓練集,6434KB) |
58.7s +568.1s |
0.01s |
0.886 |
0.900 |
0.893 |
|
平均感知機+增量訓練(Bakeoff2005 PKU訓練集6434KB+最大雙向匹配分詞結果集) |
58.7s +568.1s +20.9s |
0.01s |
0.892 |
0.900 |
0.896 |
3.5 模型改進思路
基於字標註的平均感知機分詞模型的分詞結果已經達到不錯的精度,但是在模型效能和模型分詞精度上仍有提升的空間。
為了提高模型效能,有如下幾種思路[8]:
- 感知機並行訓練演算法:從表1中可以看出,當訓練資料規模較大時,感知機的訓練過程是非常耗時的。並行訓練能大幅度的提高訓練效率。演算法的基本思想是當訓練資料規模較大時,將訓練資料劃分為S個不相交的子集,然後在這S個不相交子集上並行訓練多個子模型,對多個子模型進行融合得到最終的模型。
- 模型壓縮:在實際應用中,即使訓練語料規模不是特別大,根據模版提取的特徵數量仍然會到達百萬級甚至是千萬級之多,消耗大量記憶體。實際上,模型中存在很大一部分特徵的權重很小,對於計算狀態序列的分數影響微乎其微,因此可以通過統計特徵的權重對模型進行壓縮,將對計算分數結果影響特別小的特徵從模型中刪除。這樣在不顯著影響效能的前提下既可以減小模型檔案的大小還可以降低對記憶體的需求。
- 多執行緒並行測試:利用多核處理器,在進行分詞測試時,只需要共享同一個模型,實現對檔案中的多個句子的多執行緒並行解碼。
為了提高模型的分詞精度,有如下幾種思路:
- 增量訓練:進一步增加分詞標準一致的領域訓練集進行訓練。
- 統計與詞典相結合:實驗結果表明,直接使用雙向最大匹配演算法的分詞結果集進行並不能較好的利用詞典資訊從而提高分詞正確率。為了更好的利用詞典資訊,可以將詞典資訊進行特徵表示,融入到統計模型中。[8]
[2] 樑南元, 書面漢語的自動分詞與另一個自動分詞系統CDWS, 中國漢字資訊處理系統學術會議, 桂林, 1983
[3] 黃昌寧,趙海. 中文分詞十年回顧. 中文資訊學報. 2007
[4] Chen, K. J. and Liu S.H. Word identification for Mandarin Chinese sentences. Proceedings of the 14th International Conference on Computational Linguistics. 1992.
[5] Nianwen Xue and Susan P. Converse. Combining Classifiers for Chinese Word Segmentation, First SIGHAN Workshop attached with the 19th COLING, Taipei, 2002
[6] Nianwen Xue. Chinese word segmentation as character tagging. Computational Linguistics and Chinese Language Processing. 2003
[7] 張梅山. 鄧知龍. 統計與字典相結合的領域自適應中文分詞. 中文資訊學報. 2012
[8] 鄧知龍,基於感知器演算法的高效中文分詞與詞性標註系統設計與實現,哈爾濱工業大學,2013
[9] Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360. 2016
[10] 吳軍. 數學之美(第二版).人民郵電出版社. 2014
[11] 李正華等,中文資訊處理髮展報告(2016). 中國中文資訊學會. 2016
5. 其他資料
另附常見分詞系統評測結果如下(圖片來源見水印):
