
Oracle高階查詢之over(partition by...)
可參考:Oracle高階查詢之over(partition by…)
常用分析函式
row_number() over(partition by ... order by ...) rank() over(partition by ... order by ...) dense_rank() over(partition by ... order by ...) count() over(partition by ... order by ...) max() over(partition by ... order by ...) min() over(partition by ... order by ...) sum() over(partition by ... order by ...) avg() over(partition by ... order by ...) first_value() over(partition by ... order by ...) last_value() over(partition by ... order by ...) lag() over(partition by ... order by ...) lead() over(partition by ... order by ...)
OVER(PARTITION BY)函式介紹
oracle從8.1.6開始提供分析函式,分析函式用於計算基於組的某種聚合值,它和聚合函式的不同之處在於
- 聚合函式對於每個組只返回一條資料
- 而分析函式對於每個組返回多條資料
over後的寫法
over(order by salary)按照salary排序進行累計,order by是個預設的開窗函式
over(partition by deptno)按照部門分割槽
over(partition by deptno order by salary)
函式理解
create table EMP ( empno NUMBER(4) not null, ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(2) ) insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7369, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800, null, 20); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7499, 'ALLEN', 'SALESMAN', 7698, to_date('20-02-1981', 'dd-mm-yyyy'), 1600, 300, 30); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7521, 'WARD', 'SALESMAN', 7698, to_date('22-02-1981', 'dd-mm-yyyy'), 1250, 500, 30); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7566, 'JONES', 'MANAGER', 7839, to_date('02-04-1981', 'dd-mm-yyyy'), 2975, null, 20); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7654, 'MARTIN', 'SALESMAN', 7698, to_date('28-09-1981', 'dd-mm-yyyy'), 1250, 1400, 30); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7698, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850, null, 30); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7782, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450, null, 10); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7788, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000, null, 20); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7839, 'KING', 'PRESIDENT', null, to_date('17-11-1981', 'dd-mm-yyyy'), 5000, null, 10); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7844, 'TURNER', 'SALESMAN', 7698, to_date('08-09-1981', 'dd-mm-yyyy'), 1500, 0, 30); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7876, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100, null, 20); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7900, 'JAMES', 'CLERK', 7698, to_date('03-12-1981', 'dd-mm-yyyy'), 950, null, 30); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7902, 'FORD', 'ANALYST', 7566, to_date('03-12-1981', 'dd-mm-yyyy'), 3000, null, 20); insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (7934, 'MILLER', 'CLERK', 7782, to_date('23-01-1982', 'dd-mm-yyyy'), 1300, null, 10);
1、rank()/dense_rank() over(partition by …order by …)
需求:查詢每個部門工資最高的僱員資訊
select * from (select ename, job, hiredate, e.sal, e.deptno from emp e, (select deptno, max(sal) sal from emp group by deptno) t where e.deptno = t.deptno and e.sal = t.sal) order by deptno;
使用rank() over(partition by…)或dense_rank() over(partition by…)語法,SQL分別如下:
select empno, ename, job, hiredate, sal, deptno
from (select empno, ename, job, hiredate, sal, deptno, rank() over(partition by deptno order by sal desc) r from emp)
where r = 1;
select empno, ename, job, hiredate, sal, deptno
from (select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp)
where r = 1
語法講解:
- over:基於條件之上
- partition by e.deptno:按部門編號劃分(分組)
- order by e.sal desc:按工資從高到低排序(使用rank()/dense_rank() 時,必須要帶order by否則非法)
- ank()/dense_rank(): 分級
整個語句的含義為:在部門分組的基礎上,按工資從高到低對僱員進行排序,"級別"從1~N的數字表示(最小的為1)
那麼rank()和dense_rank()有什麼區別呢?
rank(): 跳躍排序,如果有兩個第一級時,接下來就是第三級。
dense_rank(): 連續排序,如果有兩個第一級時,接下來仍然是第二級。
分解理解:
檢視deptno = 20的記錄
select empno, ename, job, hiredate, sal, deptno from emp where deptno = 20 order by sal;

dense_rank():
select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp where deptno = 20;
dense_rank() over(partition by deptno order by sal desc):基於在(部門分組的基礎上,按工資從高到低對僱員進行排序)的基礎上,通過dense_rank()對組內的記錄進行分級
根據工資的不同從高到低進行分級,同等工資為同一級
rank():
select empno, ename, job, hiredate, sal, deptno, rank() over(partition by deptno order by sal desc) r from emp where deptno = 20;
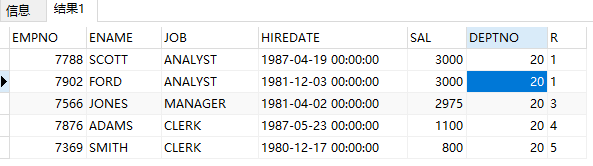
查詢部門最低工資的僱員資訊。
方法:改變分組後的,排序規則,從小到大排序(升序)
select empno, ename, job, hiredate, sal, deptno
from (select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal asc) r from emp)
where r = 1
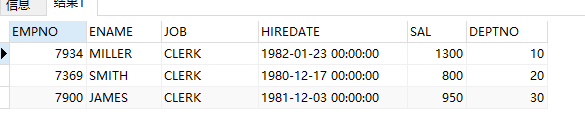
2、min()/max() over(partition by …)
現在我們已經查詢得到了部門最高/最低工資,
需求2:查詢每位僱員資訊的同時算出僱員工資與所屬部門最高/最低員工工資的差額
select e.ename as 姓名, e.job as 職業, e.hiredate as 入職日期, e.sal as 工資, e.deptno as 部門,
(e.sal - t.min_sal) as 最低差額, (t.max_sal - e.sal) as 最高差額
from emp e,
(select deptno, max(sal) as max_sal,min(sal) as min_sal from emp group by deptno) t
where e.deptno = t.deptno order by e.deptno, e.sal
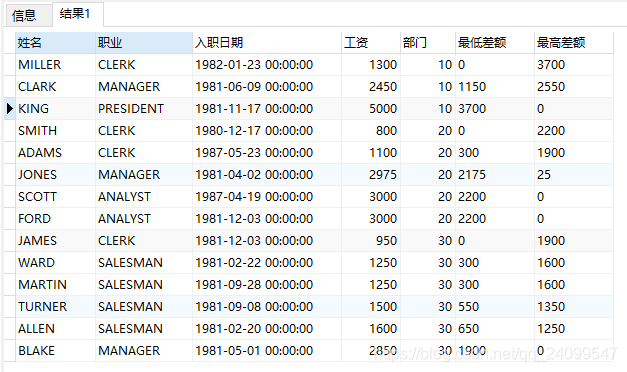
上面我們用到了min()和max(),前者求最小值,後者求最大值。如果這兩個方法配合over(partition by …)使用會是什麼效果呢?大家看看下面的SQL語句:
select ename 姓名, job 職業, hiredate 入職日期, deptno 部門,
min(sal) over(partition by deptno) 部門最低工資,
max(sal) over(partition by deptno) 部門最高工資
from emp order by deptno, sal;
select ename 姓名, job 職業, hiredate 入職日期, deptno 部門,
nvl(sal - min(sal) over(partition by deptno), 0) 部門最低工資差額,
nvl(max(sal) over(partition by deptno) - sal, 0) 部門最高工資差額
from emp order by deptno, sal;
min(sal) over(partition by deptno):基於在(部門分組)的基礎上,通過min(sal)獲取組內最小工資
這兩個語句的查詢結果是一樣的,大家可以看到min()和max()實際上求的還是最小值和最大值,只不過是在partition by分割槽基礎上的。
3、lead()/lag() over(partition by … order by …)
帶order by子句的方法說明在使用該方法的時候必須要帶order by
需求:計算在同一個部門中,個人工資與比自己高一位/低一位工資的差額。
select ename 姓名, job 職業, sal 工資, deptno 部門,
lead(sal, 1, 0) over(partition by deptno order by sal) 比自己工資高的部門前一個,
lag(sal, 1, 0) over(partition by deptno order by sal) 比自己工資低的部門後一個,
nvl(lead(sal) over(partition by deptno order by sal) - sal, 0) 比自己工資高的部門前一個差額,
nvl(sal - lag(sal) over(partition by deptno order by sal), 0) 比自己工資高的部門後一個差額
from emp;
分解:
select ename 姓名, job 職業, sal 工資, deptno 部門 from emp where deptno = 10 ORDER BY sal;
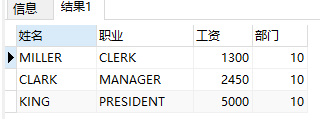
select ename 姓名, job 職業, sal 工資, deptno 部門,
lead(sal, 1, 0) over(partition by deptno order by sal) 上一個級別工資,
lag(sal, 1, 0) over(partition by deptno order by sal) 下一個級別工資
from emp where deptno = 10;
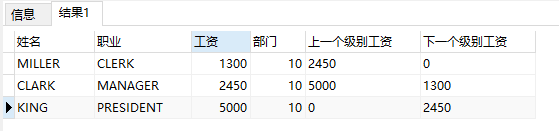
lead(列名,n,m): 當前記錄後面第n行記錄的<列名>的值,沒有則預設值為m;如果不帶引數n,m,則查詢當前記錄後面第一行的記錄<列名>的值,沒有則預設值為null。
lag(列名,n,m): 當前記錄前面第n行記錄的<列名>的值,沒有則預設值為m;如果不帶引數n,m,則查詢當前記錄前面第一行的記錄<列名>的值,沒有則預設值為null。
lead(sal, 1, 0) over(partition by deptno order by sal):基於在(部門分組的基礎上,按工資從低到高對僱員進行排序)的基礎上,通過lead(sal, 1, 0)函式獲取當前記錄後面第1條記錄的sal的值,如果後面沒有記錄了,就顯示為預設值0
4、其餘高階查詢
select ename 姓名, job 職業, sal 工資, deptno 部門,
first_value(sal) over(partition by deptno) first_sal,
last_value(sal) over(partition by deptno) last_sal,
sum(sal) over(partition by deptno) 部門總工資,
avg(sal) over(partition by deptno) 部門平均工資,
count(1) over(partition by deptno) 部門總數,
row_number() over(partition by deptno order by sal) 序號
from emp;

重要提示:大家在讀完本片文章之後可能會有點誤解,就是OVER (PARTITION BY …)比GROUP BY更好,實際並非如此,前者不可能替代後者,而且在執行效率上前者也沒有後者高,只是前者提供了更多的功能而已,所以希望大家在使用中要根據需求情況進行選擇。
row_number()淺析:
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根據COL1分組,在分組內部根據 COL2排序,而此函式計算的值就表示每組內部排序後的順序編號(組內連續的唯一的).
與rownum的區別在於:
使用rownum進行排序的時候是先對結果集加入偽列rownum然後再進行排序
而此ro
row_number()和rownum差不多,功能更強一點(可以在各個分組內從1開時排序)。
在使用 row_number() over()函式時候,over()裡頭的分組以及排序的執行晚於 where group by order by 的執行。