
【NLP】Tika 文字預處理:抽取各種格式檔案內容
作者 白寧超
2016年3月30日18:57:08
摘要:本文主要針對自然語言處理(NLP)過程中,重要基礎部分抽取文字內容的預處理。首先我們要意識到預處理的重要性。在大資料的背景下,越來越多的非結構化半結構化文字。如何從海量文字中抽取我們需要的有價值的知識顯得尤為重要。另外文字格式常常不一,諸如:pdf,word,excl,xml,ppt,txt等常見檔案型別你或許經過一番周折還是有辦法處理的。倘若遇到database,html,郵件,RTF,影象,語音等檔案,你是否素手無策了。基於此本文總結Apache Tika內容抽取工具,其強大之處在於可以處理各種檔案,另外節約您更多的時間用來做重要的事情。本文第一節採用核心概念講解第二節知識擴充套件補充。第三節典型DOME配有原始碼第四節參考核心檔案和Tika工具的JAR包共享。(本文作者原創,彙編整理所得,轉載請註明:
Tika常見格式檔案抽取內容並做預處理)
目錄
1 Tika介紹
Tika概念
Tika是一個內容分析工具,自帶全面的parser工具類,能解析基本所有常見格式的檔案,得到檔案的metadata,content等內容,返回格式化資訊。總的來說可以作為一個通用的解析工具。特別對於搜尋引擎的資料抓去和處理步驟有重要意義。Tika是Apache的Lucene專案下面的子專案,在lucene的應用中可以使用tika獲取大批量文件中的內容來建立索引,非常方便,也很容易使用。Apache Tika toolkit可以自動檢測各種文件(如word,ppt,xml,csv,ppt等)的型別並抽取文件的元資料和文字內容。Tika集成了現有的文件解析庫,並提供統一的介面,使針對不同型別的文件進行解析變得更簡單。Tika針對搜尋引擎索引、內容分析、轉化等非常有用。
Tika架構
應用程式設計師可以很容易地在他們的應用程式整合Tika。Tika提供了一個命令列介面和圖形使用者介面,使它比較人性化。在本章中,我們將討論構成Tika架構的四個重要模組。下圖顯示了Tika的四個模組的體系結構:
- 語言檢測機制。
- MIME檢測機制。
- Parser介面。
- Tika Facade 類.
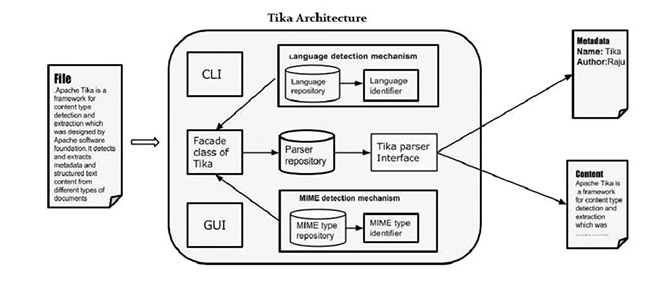
語言檢測機制
每當一個文字檔案被傳遞到Tika,它將檢測在其中的語言。它接受沒有語言的註釋檔案和通過檢測該語言新增在該檔案的元資料資訊。支援語言識別,Tika 有一類叫做語言識別符號在包org.apache.tika.language及語言識別資料庫裡面包含了語言檢測從給定文字的演算法。Tika 內部使用N-gram演算法語言檢測。
MIME檢測機制
Tika可以根據MIME標準檢測文件型別。Tika預設MIME型別檢測是使用org.apache.tika.mime.mimeTypes。它使用org.apache.tika.detect.Detector 介面大部分內容型別檢測。內部Tika使用多種技術,如檔案匹配替換,內容型別提示,魔術位元組,字元編碼,以及其他一些技術。
解析器介面
org.apache.tika.parser 解析器介面是Tika解析文件的主要介面。該介面從提取文件中的文字和元資料,並總結了其對外部使用者願意寫解析器外掛。採用不同的具體解析器類,具體為各個文件型別,Tika 支援大量的檔案格式。這些格式的具體類不同的檔案格式提供支援,無論是通過直接實現邏輯分析器或使用外部解析器庫。
Tika Facade 類
使用的Tika facade類是從Java呼叫Tika的最簡單和直接的方式,而且也沿用了外觀的設計模式。可以在 Tika API的org.apache.tika包Tika 找到外觀facade類。通過實現基本用例,Tika作為facade的代理。它抽象了的Tika庫的底層複雜性,例如MIME檢測機制,解析器介面和語言檢測機制,並提供給使用者一個簡單的介面來使用。
Tika的特點
-
統一解析器介面:Tika封裝在一個單一的解析器介面的第三方解析器庫。由於這個特徵,使用者逸出從選擇合適的解析器庫的負擔,並使用它,根據所遇到的檔案型別。
-
低記憶體佔用:Tika因此消耗更少的記憶體資源也很容易嵌入Java應用程式。也可以用Tika平臺像移動那樣PDA資源少,執行該應用程式。
-
快速處理:從應用連結內容檢測和提取可以預期的。
-
靈活元資料:Tika理解所有這些都用來描述檔案的元資料模型。
-
解析器整合:Tika可以使用可在單一應用程式中每個檔案型別的各種解析器庫。
-
MIME型別檢測: Tika可以檢測並從所有包括在MIME標準的媒體型別中提取內容。
-
語言檢測: Tika包括語言識別功能,因此可以在一個多語種網站基於語言型別的文件中使用。
Tika的功能
Tika支援多種功能:
- 文件型別檢測
- 內容提取
- 元資料提取
- 語言檢測
檔案型別檢測
Tika使用不同的檢測技術,檢測給它的檔案的型別。

內容提取
Tika有一個解析器庫,可以分析各種文件格式的內容,並提取它們。然後檢測所述文件的型別,它從解析器庫選擇的適當的分析器,並傳遞該文件。不同類別的Tika方法來解析不同的檔案格式。

元資料提取
隨著內容,Tika提取具有相同的程式的檔案的元資料中的內容的提取。對於某些檔案型別,Tika有介面類提取元資料。

語言檢測
在內部,Tika如下像一個n-gram演算法來檢測所述內容的語言的給定文件中。Tika取決於類,如語言識別和Profiler的語言識別。

2 核心知識擴充套件
解析器介面
org.apache.tika.parser.Parser 介面是 Apache Tika 的關鍵元件。它隱藏了不同檔案格式和解析庫的複雜性,而同時又為客戶應用程式從各種不同的文件提取結構化的文字內容以及元資料提供了一個簡單且功能強大的機制。所有這些都是通過一個簡單的方法實現的:
void parse(InputStream stream, ContentHandler handler, Metadata metadata) throws IOException, SAXException, TikaException;
parse 方法接受要被解析的文件以及相關的元資料作為輸入,並輸出 XHTML SAX 事件以及額外的元資料作為結果。導致這一設計的主要條件如表 1 所示。
表 1. Tika 解析設計的條件
| 條件 | 解釋 |
|---|---|
流線化的解析 |
此介面不應要求客戶應用程式或解析器實現將完整的文件內容儲存在記憶體內或存放到磁碟。這就讓即便很大的文件在沒有過多的資源要求的情況下也可被解析。 |
結構化的內容 |
一個解析器實現應該能夠包括所提取內容內的結構資訊(標題、連結等)。客戶應用程式可以使用這個資訊,比如,來更好地判斷這個被解析文件不同部分的相關性。 |
輸入元資料 |
一個客戶應用程式應該能夠包括像要被解析的文件的檔名或被宣告的內容型別這類元資料。這個解析器實現可使用這一資訊來更好地指導這個解析過程。 |
輸出元資料 |
一個解析器實現應能夠返回除文件內容外的文件元資料。很多文件格式都包含對客戶應用程式非常有用的元資料,比如作者名字。 |
這些條件在 parse 方法的引數內有所體現。
Document InputStream
第一個引數是 InputStream,用來讀取要被解析的文件。
如果此文件流不能被讀取,解析就會停止並且丟擲的 IOException 就會被傳遞給客戶應用程式。如果這個流可被讀取但不能被解析(比如文件被破壞了),解析器就會丟擲一個 TikaException。此解析器實現將會使用這個流,但不會關閉它。關閉流是由最初開啟它的這個客戶應用程式負責的。清單 1 顯示了用 parse 方法使用流的建議模式。
清單 1. 用 parse 方法使用流的建議模式
InputStream stream = ...; // open the stream
try {
parser.parse(stream, ...); // parse the stream
} finally {
stream.close(); // close the stream
}
XHTML SAX 事件
此文件流的被解析內容被作為 XHTML SAX 事件的一個序列返回給客戶應用程式。XHTML 用來表達此文件的結構化內容,SAX 事件用來啟用流線化的處理。請注意這裡使用了 XHTML 格式,僅僅是為了表達結構化資訊,不是為了呈現文件以供瀏覽。由此解析器實現生成的這些 XHTML SAX 事件被髮送至給到 parse 方法的一個 ContentHandler 例項。如果此內容處理程式處理一個事件失敗,解析就會停止並且所丟擲的 SAXException 會被髮送給客戶應用程式。清單 2 顯示了所生成的這個事件流的整體結構(並且為了清晰,還添加了縮排)。
清單 2. 所生成的這個事件流的整體結構
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>...</title>
</head>
<body>
...
</body>
</html>
解析器實現通常會使用 XHTMLContentHandler 實用工具類來生成 XHTML 輸出。處理這些原始的 SAX 事件可能會非常複雜,所以 Apache Tika(自 V0.2 開始)攜帶了幾個實用工具類,用來處理事件流並將事件流轉換為其他的表示。
比如,BodyContentHandler 類可用來只提取 XHTML 輸出的主體部分並將其作為 SAX 事件提供給另一個內容處理程式或作為符號提供給一個輸出流、一個編寫器或 一個字串。如下的程式碼片段解析了來自標準輸入流的文件並將所提取的文件內容輸出到標準輸出:
ContentHandler handler = new BodyContentHandler(System.out); parser.parse(System.in, handler, ...);
另一個有用的類是 ParsingReader,它使用了一個後臺執行緒來解析此文件並作為一個字元流返回所提取的文字內容。
清單 3. ParsingReader 的例子
InputStream stream = ...; // the document to be parsed
Reader reader = new ParsingReader(parser, stream, ...);
try {
...; // read the document text using the reader
} finally {
reader.close(); // the document stream is closed automatically
}
文件元資料
parse 方法的最後一個引數用來將文件元資料傳遞進/出此解析器。文件元資料被表述為一個元資料物件。表 2 列出了更有趣的一些元資料屬性。
表 2. 元資料屬性
| 屬性 | 描述 |
|---|---|
Metadata.RESOURCE_NAME_KEY |
包含了此文件的檔案或資源名 — 一個客戶應用程式可設定此屬性來讓解析器通過檔名推斷此文件的格式。如果檔案格式包含了規範的檔名(比如,GZIP 格式有一個針對檔名的槽),那麼檔案解析器實現可設定此屬性。 |
Metadata.CONTENT_TYPE |
此文件的宣告內容型別 — 一個客戶機應用程式可基於,比如 HTTP Content-Type 頭,設定此屬性。所宣告的內容型別可幫助解析器正確地解析文件。解析器實現根據被解析的是哪個文件來將此屬性設定為相應的內容型別。 |
Metadata.TITLE |
文件的標題 — 如果文件格式包含了一個顯式的標題欄位,那麼此屬性將由解析器實現設定。 |
Metadata.AUTHOR |
文件的作者名 — 如果文件格式包含了一個顯式的作者欄位,那麼此屬性將由解析器實現設定。 |
注意到,元資料處理還在 Apache Tika 開發團隊的討論之中,所以在 Tika V1.0 之前的版本,在元資料處理方面有可能會有一些(後向不相容的)差異。
解析器實現
Apache Tika 自帶一些解析器類來解析各種文件格式,如表 3 所示。
表 3. Tika 解析器類
| 格式 | 描述 |
|---|---|
| Microsoft® Excel® (application/vnd.ms-excel) | 在所有的 Tika 版本中都有對 Excel 電子資料表的支援,基於的是 POI 的 HSSF 庫。 |
| Microsoft Word®(application/msword) | 在所有的 Tika 版本中都有對 Word 文件的支援,基於的是 POI 的 HWPF 庫。 |
| Microsoft PowerPoint® (application/vnd.ms-powerpoint) | 在所有的 Tika 版本中都有對 PowerPoint 演示的支援,基於的是 POI 的 HSLF 庫。 |
| Microsoft Visio® (application/vnd.visio) | 在 Tika V0.2 中加入了對 Visio 圖表的支援,基於的是 POI 的 HDGF 庫。 |
| Microsoft Outlook® (application/vnd.ms-outlook) | 在 Tika V0.2 中加入了對 Outlook 訊息的支援,基於的是 POI 的 HSMF 庫。 |
| GZIP 壓縮 (application/x-gzip) | 在 Tika V0.2 中加入了對 GZIP 的支援,基於的是 Java 5 類庫中的 GZIPInputStream 類。 |
| bzip2 壓縮 (application/x-bzip) | 在 Tika V0.2 中加入了對 bzip2 的支援,基於的是 Apache Ant 的 bzip2 解析程式碼,而它最初基於的是 Aftex Software 的 Keiron Liddle 的工作成果。 |
| MP3 音訊(audio/mpeg) | 在 Tika V0.2 中加入了對 MP3 檔案的 ID3v1 標記的解析。如果找到,如下的元資料將被提取並設定:
|
| MIDI 音訊 (audio/midi) | Tika 使用 javax.audio.midi 內的 MIDI 支援來解析 MIDI 序列檔案。很多卡拉 OK 檔案格式都基於的是 MIDI 幷包含嵌入文字歌曲形式的歌詞,並且 Tika 知道該如何提取。 |
| Wave 音訊 (audio/basic) | Tika 通過 javax.audio.sampled 包支援取樣的 wave 音訊(.wav 檔案等)。只有取樣元資料才被提取。 |
| Extensible Markup Language (XML) (application/xml) | Tika 使用 javax.xml 類解析 XML 檔案。 |
| HyperText Markup Language (HTML) (text/html) | Tika 使用 CyberNeko 庫解析 HTML 檔案。 |
| 影象 (image/*) | Tika 使用 javax.imageio 類從影象檔案中提取元資料。 |
| Java 類檔案 | Java 類檔案的解析基於的是 ASM 庫以及 JCR-1522 的 Dave Brosius 的工作成果。 |
| Java Archive Files | JAR 檔案的解析是綜合使用 ZIP 和 Java 這兩種類檔案解析器完成的。 |
| OpenDocument (application/vnd.oasis.opendocument.*) | Tika 使用 Java 語言中的內建 ZIP 和 XML 特性來解析多為 OpenOffice V2.0 或更高版本所用的 OpenDocument 文件型別。較早的 OpenOffice V1.0 格式也受支援,但它們目前不能像較新的格式那樣被自動檢測。 |
| 純文字 (text/plain) | Tika 使用 International Components for Unicode Java 庫(ICU4J)來解析純文字。 |
| Portable Document Format (PDF) (application/pdf) | Tika 使用 PDFBox 庫來解析 PDF 文件。 |
| Rich Text Format (RTF) (application/rtf) | Tika 使用 Java 的內建 Swing 庫來解析 RTF 文件。 |
| TAR (application/x-tar) | Tika 使用來自 Apache Ant 的 TAR 解析程式碼的調整版本來解析 TAR 檔案。而此 TAR 程式碼基於的是 Timothy Gerard Endres 的工作成果。 |
| ZIP (application/zip) | Tika 使用 Java 的內建 ZIP 類來解析 ZIP 檔案。 |
您可以使用您自己的解析器來擴充套件 Apache Tika,您對 Tika 所做的任何貢獻都是受歡迎的。Tika 的目標是儘可能地重用現有的解析器庫(比如 Apache PDFBox 或 Apache POI),因此 Tika 內的大多數解析器類都是適應於這些外部庫。Apache Tika 還包含一些不針對任何特定文件格式的通用解析器實現。其中最值得一提的是 AutoDetectParser 類,它將所有的 Tika 功能包裝進一個能處理任何文件型別的解析器。這個解析器可自動決定入向文件的型別,然後會相應解析此文件。現在,我們可以進行一些實際操作了。如下的這些類是我們在整個教程中要開發的:
BudgetScramble— 顯示瞭如何使用 Apache Tika 元資料來決定哪個文件最近被更改以及在何時更改。TikaMetadata— 顯示瞭如何獲得某個文件的所有 Apache Tika 元資料,即便沒有資料(只顯示所有的元資料型別)。TikaMimeType— 顯示瞭如何使用 Apache Tika 的 mimetypes 來檢測某個特定文件的 mimetype。TikaExtractText— 顯示了 Apache Tika 的檔案提取功能並將所提取的文字儲存為合適的檔案。LanguageDetector —介紹了 Nutch 語言的識別功能來識別特定內容的語言。Summary —總結了 Tika 特性,比如MimeType、內容 charset 檢測和元資料。此外,它還引入了 cpdetector 功能來決定一個檔案的 charset 編碼。最後,它顯示了 Nutch 語言識別的實際使用。
3 Tika文字抽取例項分析
Tika主要通過5個部分完成常規資料抽取:
1 InputStream input=new FileInputStream(new File("./myfile/Active Learning.pdf")); //構建InputStream來讀取資料,可以寫檔案路徑,pdf,word,html等
2 BodyContentHandler textHandler=new BodyContentHandler(); //獲取內容
3 Metadata matadata=new Metadata();//Metadata物件儲存了作者,標題等元資料
4 PDFParser ParseContext context=new ParseContext(); //這裡Parser解析器根據不同檔案採用不同解析器
5 Parser parser=new AutoDetectParser();//當呼叫parser,AutoDetectParser會自動估計文件MIME型別,此處輸入pdf檔案,因此可以使用
6 parser.parse(input, textHandler, matadata, context);//執行解析過程
原始碼:
/**
* Tika AutoDetectParser類來識別和抽取內容
* @throws TikaException
* @throws SAXException
* @throws IOException
*/
public static void getTextFronPDF() throws IOException, SAXException, TikaException{
//構建InputStream來讀取資料
InputStream input=new FileInputStream(new File("./myfile/Active Learning.pdf"));//可以寫檔案路徑,pdf,word,html等
BodyContentHandler textHandler=new BodyContentHandler();
Metadata matadata=new Metadata();//Metadata物件儲存了作者,標題等元資料
Parser parser=new AutoDetectParser();//當呼叫parser,AutoDetectParser會自動估計文件MIME型別,此處輸入pdf檔案,因此可以使用PDFParser
ParseContext context=new ParseContext();
parser.parse(input, textHandler, matadata, context);//執行解析過程
input.close();
System.out.println("Title: "+matadata.get(Metadata.TITLE));
System.out.println("Type: "+matadata.get(Metadata.TYPE));
System.out.println("Body: "+textHandler.toString());//從textHandler列印正文
}
執行結果:
