
使用spark對輸入目錄的檔案進行過濾
阿新 • • 發佈:2018-12-31
使用spark進行檔案過濾
在使用spark的很多情形下, 我們需要計算某個目錄的資料.
但這個資料夾下面並不是所有的檔案都是我們想要計算的
比如 : 對於某一天的資料,我們只想計算其中的幾個小時,這個時候就需要把剩下的資料過濾掉
更壞的一種情形 : 對於那些正在copy(還沒有完成),或者是.tmp臨時檔案,
程式在讀取的過程中,檔案發生變化已經複製完成或者被刪除,都會導致程式出錯而停掉
為了避免上述問題的出現, 我們就需要對 輸入目錄下的檔案進行過濾:
即保證我們textFile的時候, 只讀取那些我們想要的資料.
1.基本操作
獲取到spark的context,程式碼如下 : SparkConf sparkConf = new SparkConf(); sparkConf.setAppName("spark.fileFilter"); sparkConf.setMaster("local"); JavaSparkContext jsc = new JavaSparkContext(sparkConf);
2. 關鍵操作
1. 通過spark的context得到hadoop的configuration,並對hadoop的conf進行設定 程式碼如下 : Configuration conf = jsc.hadoopConfiguration(); //通過spark上下文獲取到hadoop的配置 conf.set("fs.defaultFS", "hdfs://192.168.1.31:9000"); conf.set("mapreduce.input.pathFilter.class", "cn.mastercom.bigdata.FileFilter"); // 設定過濾檔案的類,這是關鍵類!! 2. 過濾類FileFilter的寫法 關鍵點 : 實現PathFilter介面,重寫裡面的accept方法
一個簡單的測試demo如下 :
package cn.mastercom.bigdata; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.PathFilter; /** * 輸入路徑的檔案過濾 * 過濾掉臨時檔案和正在複製的檔案 * @author xmr * */ public class FileFilter implements PathFilter { @Override public boolean accept(Path path) { String tmpStr = path.getName(); if(tmpStr.indexOf(".tmp") >= 0) { return false; } else if(tmpStr.indexOf("_COPYING_") >= 0) { return false; } else { return true; } } }
3. 讀取目錄(檔案), 進行rdd操作,輸出結果
經過以上設定,使用spark對輸出目錄的檔案進行過濾的功能就已經實現了!
接下來的rdd操作,就只會針對那些沒有被過濾掉的檔案了!!
具體的執行又分為以下幾種情況 :(測試進行的rdd操作為最簡單的map,直接將輸入的結果輸出出來)
1. 直接讀取被過濾掉的檔案(.tmp檔案或者是正在複製的檔案)
舉例 :
JavaRDD<String> testRdd = jsc.textFile("hdfs://192.168.1.31:9000/test/spark/part-00003.tmp");
這種情況下會丟擲檔案不存在的異常 :
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException:
Input path does not exist: hdfs://192.168.1.31:9000/test/spark/part-00003.tmp
詳細報錯情況如下圖 : !!
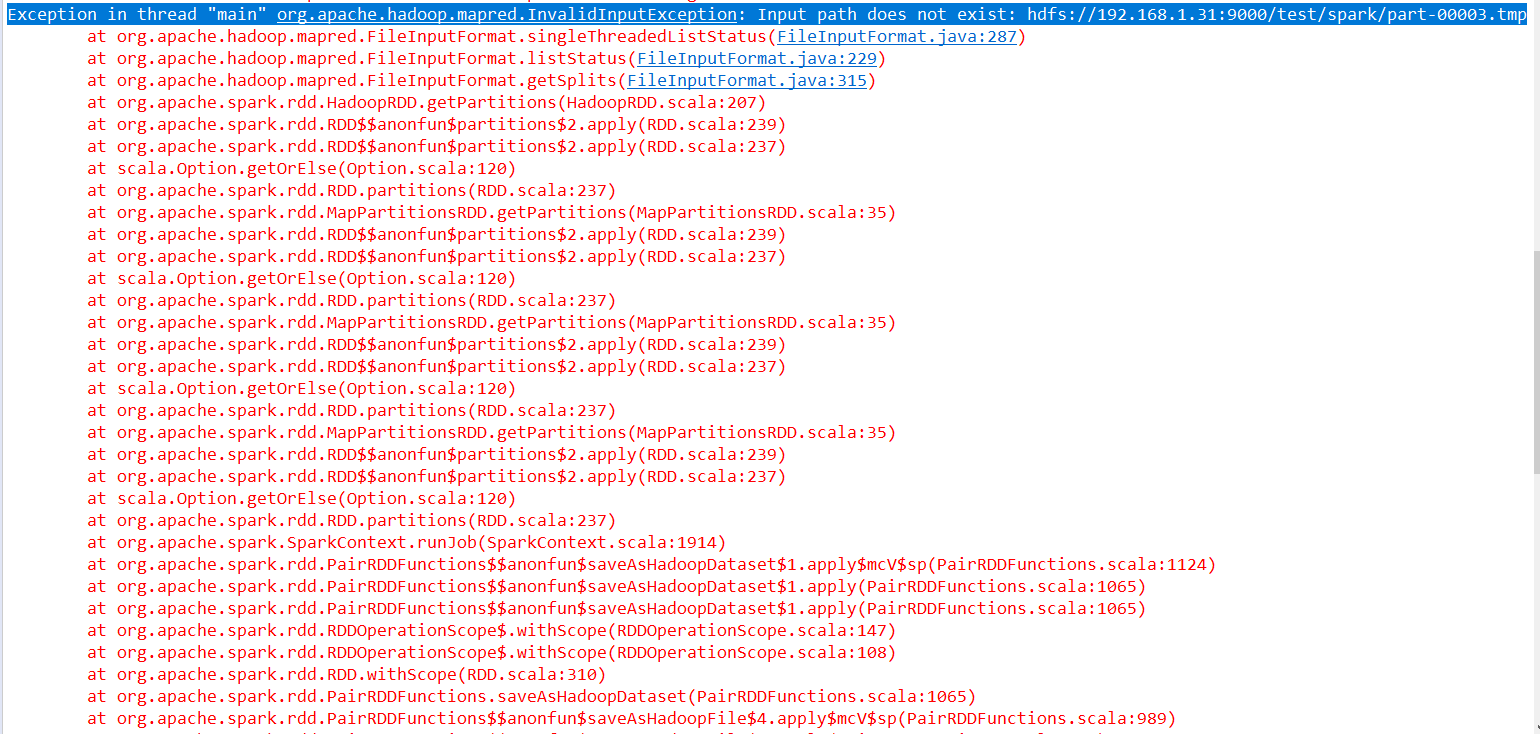
但是這個檔案在hdfs上面命名是存在的,為什麼會碰到這個問題呢? 去原始碼裡面看,發現程式碼如下 :
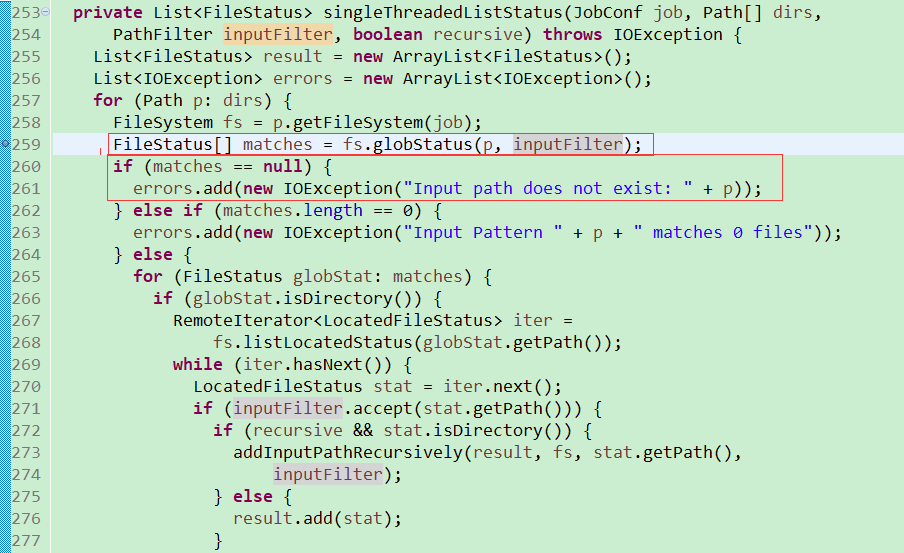
紅框標註的 p ,就是我們傳入的path, inputFilter就是我們FileFilter裡面設定的檔案過濾
而這個檔案剛好在我們的過濾範圍內,globstatus就會返回一個空值
在matches是一個空值的情況下,就會丟擲 : Input path does not exist: 的異常
2. 讀取正常檔案(不在過濾的範圍內)
執行情況與正常執行的spark程式相同,不再贅述
3. 讀取一個全部都是要被過濾掉檔案的資料夾
舉例 :
JavaRDD<String> testRdd = jsc.textFile("hdfs://192.168.1.31:9000/test/spark");
// 這個資料夾下所有的檔案都是.tmp檔案或者是_COPYING_檔案
這種情形下雖然沒有任何的結果輸出出來(因為所有的檔案都被過濾掉)
但是也並沒有丟擲 Input path does not exist: 的異常,這是為什麼呢?
原因 : 我們的Filter過濾, 過濾掉的是這個目錄下面的所有檔案
但是這個資料夾,對於框架來說,確實是存在的,所以才不會報錯
如果我們換一種寫法 :
JavaRDD<String> testRdd = jsc.textFile("hdfs://192.168.1.31:9000/test/spark/*"); // 讀取這個資料夾下面全部的檔案
這種情況下就會有錯誤丟擲啦!
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException: Input Pattern hdfs://192.168.1.31:9000/test/spark/* matches 0 files
詳細報錯資訊如下:!
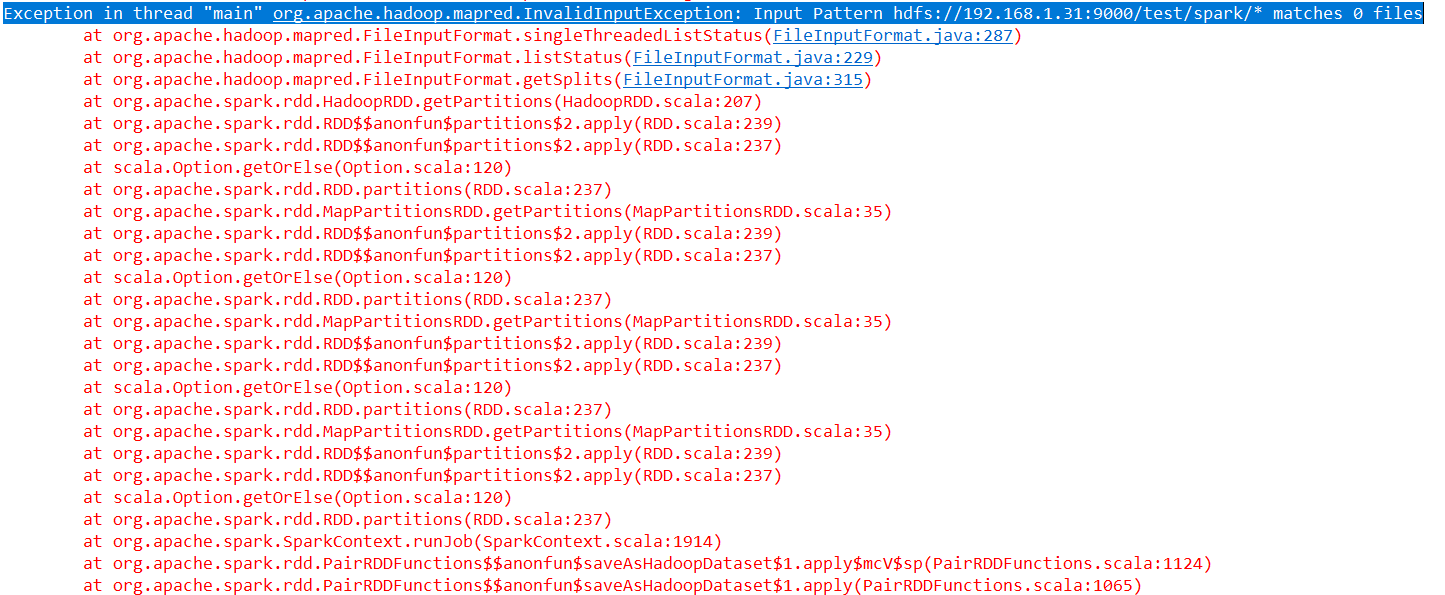
這錯誤就是說 : 這個目錄下沒有檔案匹配~
同樣的目的,換一種寫法,結果就截然不同,還是挺奇妙的吧!!
4. 讀取一個不全都是要被過濾掉檔案的資料夾
結果 : 符合過濾條件的檔案被過濾掉,其餘的檔案正常運算跑出結果
總結 : spark的檔案過濾最關鍵的還是得到hadoop的configuration
並且對這個configuration進行設定!
在讀取檔案的時候,框架就會自動在最合適的時候進行檔案的過濾~
hadoop,spark還是很強大的QAQ!