
SQLServer建立索引的5種方法
前期準備:
create table Employee (
ID int not null primary key,
Name nvarchar(4),
Credit_Card_ID varbinary(max)); --- 小心這種資料型別。
go說明:本表上的索引,都會在建立下一個索引前刪除。
建立聚集索引
方法 1、
ALTER TABLE table_name ADD CONSTRAINT cons_name priamry KEY(columnname ASC|DESC,[.....]) WITH 這個是一種特別的方法,因為在定義主鍵的時候,會自動新增索引,好在加的是聚集索引還是非聚集索引是我們人為可以控制的。
通過sp_helpindex 可以查看錶中的索引
execute sp_helpindex @objname = 'Employee';
go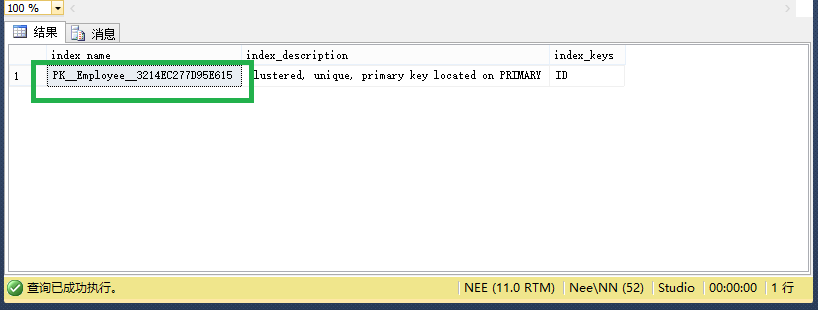
注意:這個索引是無法刪除的,不信! 你去刪一下
drop index Employee.PK__Employee__3214EC277D95E615; 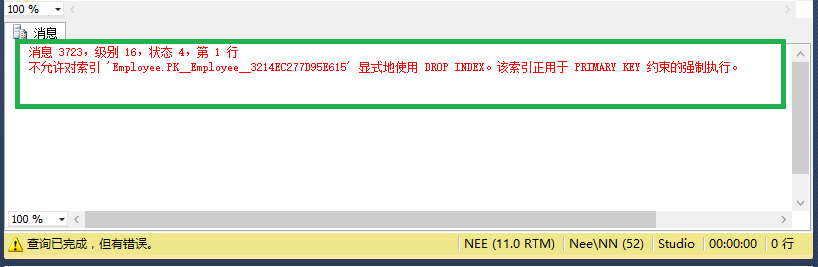
方法 2、
create clustered index ix_name on table_name(columnName ASC|DESC[,......]) with (drop_existing = on);
create clustered index ix_clu_for_employee_ID on Employee(ID);
go檢視建立的索引
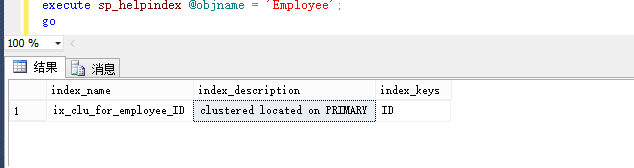
建立複合索引
create index ix_com_Employee_IDName on Employee (ID,Name)with (drop_existing = on);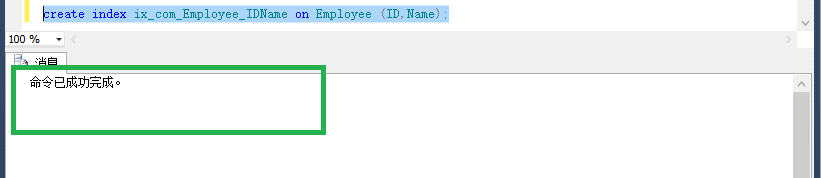
這樣就算是建立一個複合索引了,不過腳下的路很長,我們看下一個複合索引的例句:
create index ix_com_Employee_IDCreditCardID on Employee(ID,Credit_Card_ID);看到這句話,你先問一下自己它有沒有錯!
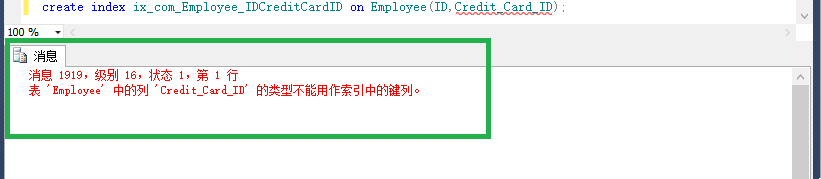
可以發現它錯了,varbinary是不可以建索引的。
建立覆蓋索引
create index index_name on table_Name (columnName ASC|DESC[,......]) include(column_Name_List)with (drop_existing = on);
create index ix_cov_Employee_ID_Name on Employee (ID) include(Name);
go首先,覆蓋索引它只是非聚集索引的一種特別形式,下文說的非聚集索引不包涵覆蓋索引,當然這個約定只適用於這一段話,這樣做的目的是為了說明各中的區別。
首先:
非聚集索引不包涵資料,通過它找到的只是檔案中資料行的引用(表是堆的情況下)或是聚集索引的引用,SQL Server要通這個引用去找到相應的資料行。
正因為非聚集索引它沒有資料,才引發第二次查詢。
覆蓋索引就是把資料加到非聚集索引上,這樣就不需要第二次查找了。這是一種以空間換效能的方法。非聚集索引也是。只是做的沒有它這麼出格。
建立唯一索引
create unique index index_name on table_name (column ASC|DESC[,.....])with (drop_existing = on);正如我前面所說,在建立表上的索引前,我會刪除表上的所有索引,這裡為什麼我要再說一下呢!因為我怕你忘了。二來這個例子用的到它。
目前表是一個空表,我給它加兩行資料。
insert into Employee(ID,Name) values(1,'AAA'),(1,'BBB');
這下我們為表加唯一索引,它定義在ID這個列上
create unique index ix_uni_Employee_ID on Employee(ID);
go -- 可以想到因為ID有重複,所以它建立不了。
結論 1、 如果在列上有重複值,就不可以在這個列上定義,唯一索引。
下面我們把表清空: truncate table Employee;

接下來要做的就是先,建立唯一索引,再插入重複值。
create unique index ix_uni_Employee_ID on Employee(ID);
go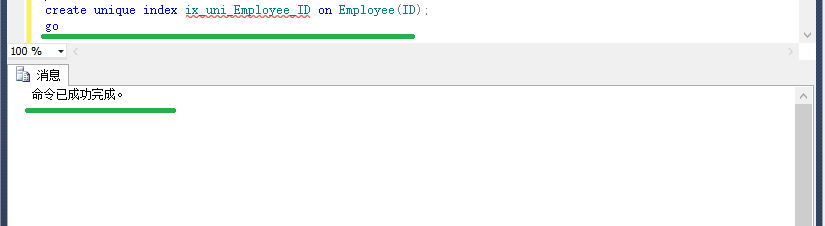
insert into Employee(ID,Name) values(1,'AAA'),(1,'BBB');
go
結論 2、
定義唯一索引後相應的列上不可以插入重複值。
篩選索引
create index index_name on table_name(columName) where boolExpression;
create index ix_Employee_ID on Employee(ID) where ID>100 and ID< 200;
go只對熱點資料加索引,如果大量的查詢只對ID 由 100 ~ 200 的資料感興趣,就可以這樣做。
- 可以減小索引的大小
- 為據點資料提高查詢的效能。
總結:
BTree 索引有聚集與非聚集之分。
就檢視上到聚集索引效能比非聚集索引效能要好。
非聚集索引分
覆蓋索引,唯一索引,複合索引(當然聚集索引也有複合的,複合二字,只是說明索引,引用了多列),一般非聚集索引就檢視上到非聚集索引中覆蓋索引的效能比別的非聚集索引效能要好,它的效能和聚集索引差不多,可是它也不是’銀彈‘ 它會用更多的磁碟空間。
最後說一下這個
with (drop_existing = on|off),加上這個的意思是如果這個索引還在表上就drop 掉然後在create 一個新的。特別是在聚集索引上使用這個就可以不會引起非聚集索引的重建。
with (online = on|off) 建立索引時使用者也可以訪問表中的資料,
with(pad_index = on|off fillfactor = 80); fillfactor 用來設定填充百分比,pad_index 只是用來連線fillfactor 但是它又不能少,這點無語了。
with(allow_row_locks = on|off | allow_page_locks = on |off); 是否允許頁鎖 or 行鎖
with (data_compression = row | page ); 這樣可以壓縮索引大小