
【大創_社區劃分】——PageRank演算法MapReduce實現
舉例來講:
假設每個網頁都有一個自己的預設PR值,相當於人為新增給它是一種屬性,用來標識網頁的等級或者重要性,從而依據此標識達到排名目的。假設有ID號是1的一個網頁,PR值是10,假如它產生了到ID=3,ID=6,ID=8 ,ID=9這4個網頁的連結。那麼可以理解為ID=1的網頁向ID=3,6,8,9的4個網頁各貢獻了2.5的PR值。如果想求任意一個網頁假設其ID=3的PR值,需要得到所有的其他網頁對ID=3這個網頁的貢獻的總和,再按照函式“所求PR”=“總和”*0.85+0.15得到。經過迴圈多次上述過程求得的網頁PR值,可以作為網頁排名的標識。
1:準備資料
理論資料是通過網頁爬蟲得到了某個特定封閉系統的所有網頁的資訊,為了測試程式,可以自己模擬生成自己定義特定格式的資料。下面是我用來測試的資料,儲存方式如圖
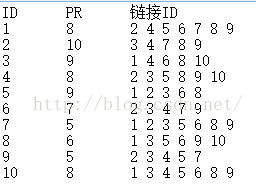
(注:對於自定義模擬資料,在PR初始值的選取時,所有的網頁是“平等”的,不會說自己寫的網頁和Google的熱門網頁有多少差別,但是按照某種法則經過一定運算後PR是不一樣的,比如很多其他的網頁可能會連結到google,它的PR自然會比你的高。所以初始值的選取按照這種邏輯來講符合現實些,即所有網頁預設PR值相等。但是即使初始值定的不一樣,整個系統的PR總和可能會變化,最後的每個網頁PR也會發生變化,但是這種量之間的變化,不會影響到網頁自身的通過比較大小方式上的邏輯排名。
2:MapReduce過程
map接受的資料格式預設是<偏移量,文字行>這樣的<key,value>對,形如<0,1 5 2 3 4 5><20,2 10 3 5 8 9>.
目標 :將預設資料格式,轉換成自定義格式<key,value>對。
已知 :hadoop框架在Map階段的時候會自動實現sort過程,就是將相同的key的所有value儲存到list,形如<key,list(1,1,1,2)>這種形式,例如上述對ID=2的網頁有ID=1,6,7,8.這4個網頁貢獻(1.25,1,5/3,5),那麼如果你採用的key是網頁ID,那麼hadoop框架會以此種形式<2,list(1.25,1,5/3,5)>輸出,傳遞給reduce。
Reduce階段:
分析:這個階段操作就相對簡單很多,讀取map的輸出<key,value>,並解析出來。
具體操作:把values中的數字相加即為對應id的PageRank值。
結果如下圖:

程式碼如下
package pageRank;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class pageRank {
public static class Map extends Mapper<Object,Text,IntWritable,FloatWritable>{
private final IntWritable word = new IntWritable();
private String pr;
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString());
if(itr.hasMoreTokens()) {String id = itr.nextToken();}
else return;
pr = itr.nextToken(); //網頁的pr值
int count = itr.countTokens(); //連結ID的數目
float average_pr = Float.parseFloat(pr)/count;
while(itr.hasMoreTokens()){
word.set(Integer.parseInt(itr.nextToken()));
context.write(word, new FloatWritable(average_pr));
}
}
}
public static class Reduce extends Reducer<IntWritable,FloatWritable,IntWritable,FloatWritable>{
float sum;
public void reduce(IntWritable key,Iterable<FloatWritable>values,Context context) throws IOException, InterruptedException{
for(FloatWritable val:values){
sum += val.get();
}
context.write(key,new FloatWritable(sum));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Job job = new Job();
job.setJarByClass(pageRank.class);
job.setNumReduceTasks(1);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(FloatWritable.class);
FileInputFormat.addInputPath(job, new Path("/thinkgamer/input"));
FileOutputFormat.setOutputPath(job, new Path("/thinkgamer/output"));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}