
【文章閱讀】【超解像】--Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
【文章閱讀】【超解像】–Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
論文連結:https://arxiv.org/abs/1609.04802
code(tensorflow):https://github.com/tensorlayer/srgan
本文將GAN網路引入到了SR應用中,有挺多的創新點,現將文中的主要內容總結如下,後續方便閱讀。該主題文章從2016年到2017年一共有5個版本,本文為最新版本V5的閱讀理解。
1.主要貢獻
針對傳統超分辨中存在結果過平滑問題,在PSNR和SSIM評價指標上能得到很好的結果,但影象細節顯示依舊較差,利用對抗網路結構的方法,得到了視覺特性上較好結果,本文主要貢獻如下:
- 建立了使用PSNR和SSIM為評價標準的SRResNet,對影象進行放大4倍,取得了最好的測試結果。
- 提出了SRGAN網路,該網路結構根據對抗網路網路結構提出了一種新的視覺損失函式(perceptual loss),利用VGG的網路特徵作為內容損失函式(content loss),代替了之前的MSE損失函式。
- 對生成的影象進行MOS(mean opinion score)進行評價。
先上圖看一下影象最終的影象效果:

2.論文分析
基於CNN的超解析度方法主要以最優化思想進行目標函式優化,受到目標函式的影響較大。之前的很多研究以最小化平方方差(MSE)作為損失函式,該方法能得到較好的信噪比,但影象會缺失高頻資訊導致影象的視覺效果差。

1)用MSE作為損失函式影象模糊
文中解釋了為什麼MSE為損失函式的影象會損失影象的高頻資訊,MSE以畫素空間的比較為參考,一個低解析度的影象塊可能對應高解析度中的多個影象塊,而GAN只有唯一的對應,這樣,通過MSE為目標函式的處理方式會將多個高解析度的影象塊進行平均,所以最終得到的結果有一些模糊。

2) 網路結構
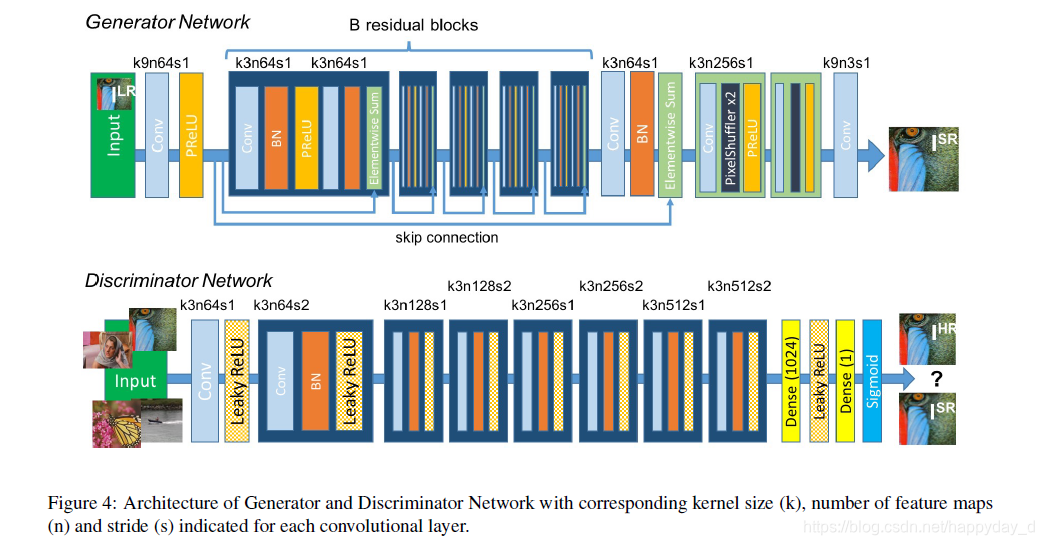
上圖上部分為:生成網路結構,基於Resnet網路結構;
上圖下部分為:辨別網路結構,利用LeakyReLU(0.2)為啟用函式,網路層數從64到512,後面連線兩個全連線層和一個sigmoid層,用來判斷是否為同一影象的概率;
3)損失函式
(a) 訓練生成器和判別器
對給定的HR影象進行降取樣得到LR圖片,將LR影象作為輸入,訓練生成器,生成對應的HR影象,該訓練過程與訓練前饋CNN類似,對網路引數
進行優化,如下:
其中
為視覺損失函式,後面詳細介紹。
文中定義的判別器為
,生成器和判別器交替優化如下式子:
(b) 視覺損失函式(perceptual loss function)
本文設計的視覺損失函式,是本文演算法效能的保證,如下,分為內容損失(Content loss)和對抗損失(Adversarial loss)
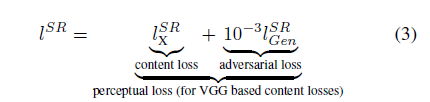
(1) 內容損失
常用的畫素級內容損失函式為MSE,如下,該損失函式能取得較高的PSNR,但導致內容缺乏高頻影象內容,使最終的顯示內容過於平滑。
文中對內容損失函式進行了改進,在pre-trained 19層 VGG網路(ReLU損失函式)結構基礎上定義了VGG loss: