
Elasticsearch 5.0 簡介(medcl微信直播實錄)
大家好,非常高興能在這裡給大家分享,感謝InfoQ提供的這個微信的平臺,首先簡單自我介紹一下,我叫曾勇,是Elastic的工程師。
Elastic將在今年秋季的時候釋出一個Elasticsearch V5.0的大版本,這次的微信分享將給大家介紹一下5.0版裡面的一些新的特性和改進。
5.0? 天啦嚕,你是不是覺得版本跳的太快了。
好吧,先來說說背後的原因吧。

相信大家都聽說ELK吧,是Elasticsearch、Logstash、Kibana三個產品的首字母縮寫,現在Elastic又新增了一個新的開源專案成員:Beats,

有人建議以後這麼叫:ELKB?為了未來更好的擴充套件性:) ELKBS?ELKBSU?…..所以我們打算將產品線命名為ElasticStack,同時由於現在的版本比較混亂,每個產品的版本號都不一樣,Elasticsearch和Logstash目前是2.3.4;Kibana是4.5.3;Beats是1.2.3;

版本號太亂了有沒有,什麼版本的ES用什麼版本的Kibana?有沒有相容性問題?
所以我們打算將這些的產品版本號也統一一下,即v5.0,為什麼是5.0,因為Kibana都4.x了,下個版本就只能是5.0了,其他產品就跟著跳躍一把,第一個5.0正式版將在今年的秋季釋出,目前最新的測試版本是:5.0 Alpha 4
上面就是整個ElasticStack了,其實還是之前的那些啦
目前各團隊正在緊張的開發測試中,每天都有新的功能和改進,本次分享主要介紹一下Elasticsearch的主要變化。
首先來看看5.0裡面都引入了哪些新的功能吧。
首先看看跟效能有關的,第一個就是Lucene 6.x 的支援,
Elasticsearch5.0率先集成了Lucene6版本,其中最重要的特性就是 Dimensional Point Fields,多維浮點欄位,ES裡面相關的欄位如date, numeric,ip 和 Geospatial 都將大大提升效能,這麼說吧,磁碟空間少一半;索引時間少一半;查詢效能提升25%;IPV6也支援了。
為什麼快,底層使用的是Block k-d trees,核心思想是將數字型別編碼成定長的位元組陣列,對定長的位元組陣列內容進行編碼排序,然後來構建二叉樹,然後依次遞迴構建,目前底層支援8個維度和最多每個維度16個位元組,基本滿足大部分場景。
說了這麼多,看圖比較直接
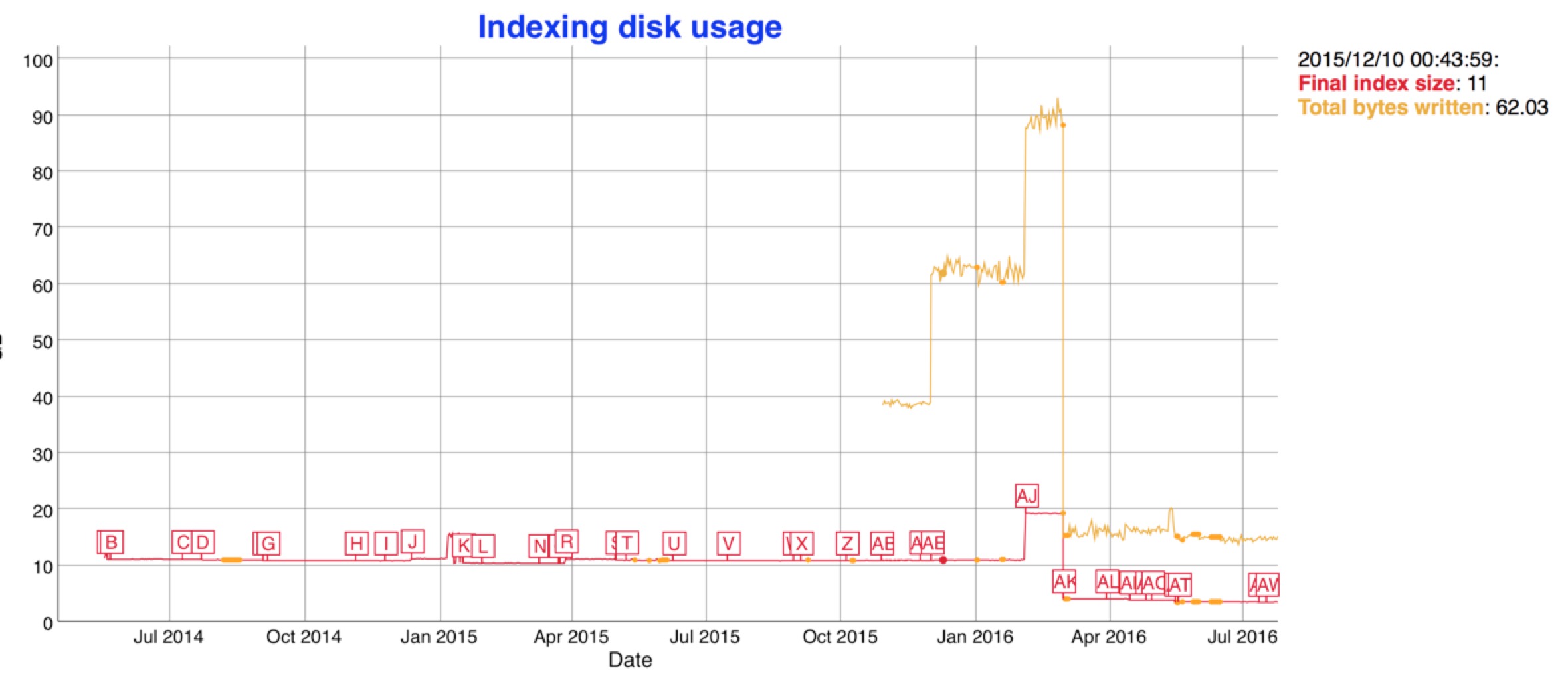
圖中從2015/10/32 total bytes飆升是因為es啟用了docvalues,我們關注紅線,最近的引入新的資料結構之後,紅色的索引大小隻有原來的一半大小。索引小了之後,merge的時間也響應的減少了,看下圖
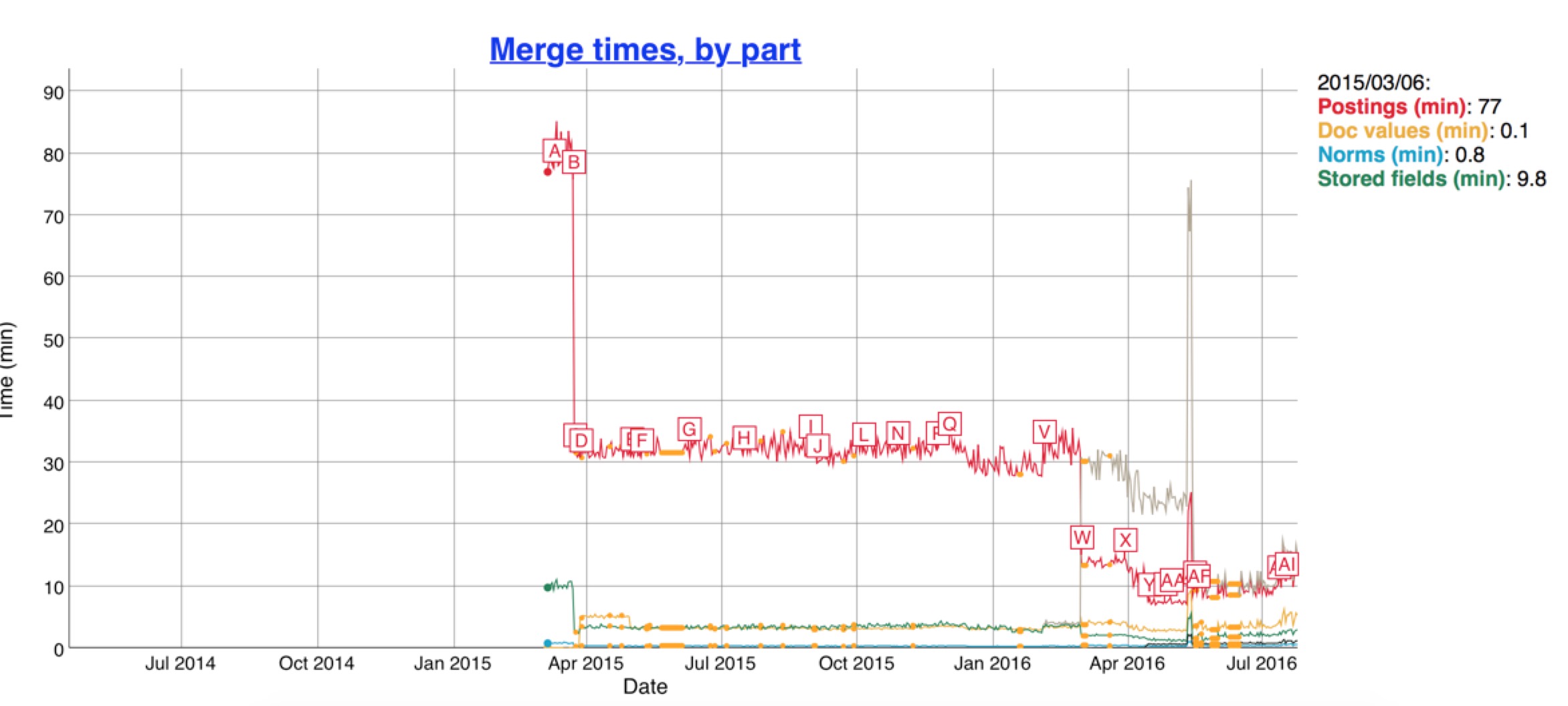
相應的Java堆記憶體佔用只原來的一半:
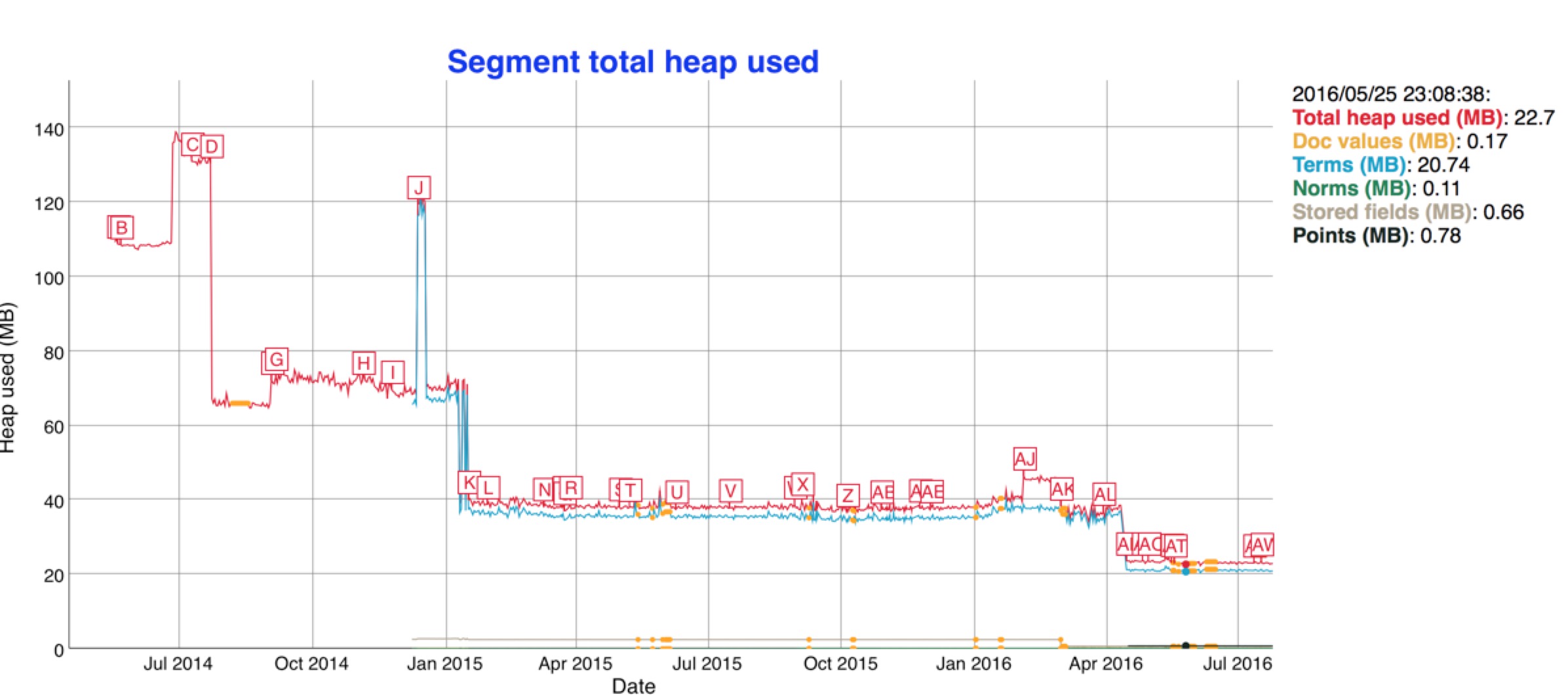
再看看索引的效能,也是飆升
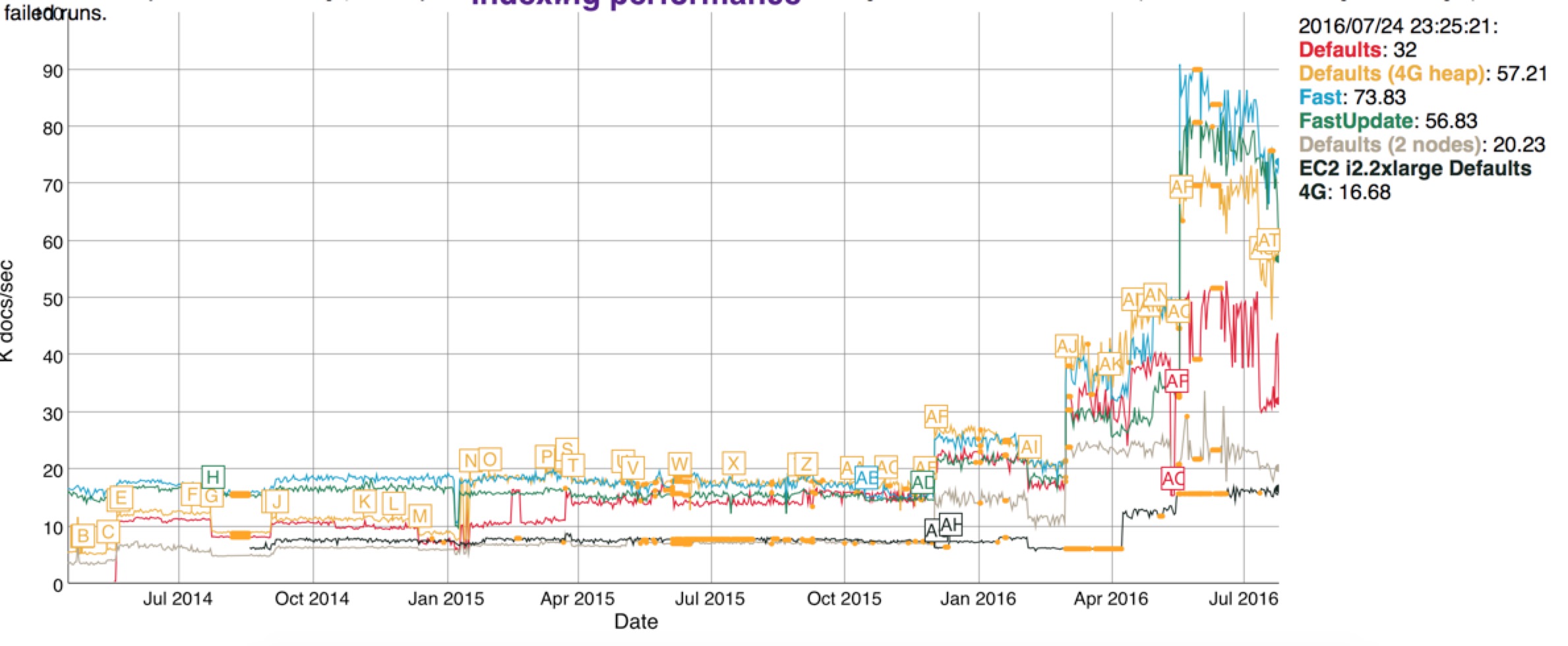
當然Lucene6裡面還有很多優化和改進,這裡沒有一一列舉。我們再看看索引效能方面的其他優化
ES5.0在Internal engine級別移除了用於避免同一文件併發更新的競爭鎖,帶來15%-20%的效能提升 #18060
另一個和aggregation的改進也是非常大,Instant Aggregations
Elasticsearch已經在Shard層面提供了Aggregation快取,如果你的資料沒有變化,ES能夠直接返回上次的快取結果,但是有一個場景比較特殊,就是 date histogram,大家kibana上面的條件是不是經常設定的相對時間,如:from:now-30d to:now,好吧,now是一個變數,每時每刻都在變,所以query條件一直在變,快取也就是沒有利用起來,經過一年時間大量的重構,現在可以做到對查詢做到靈活的重寫,首先now關鍵字最終會被重寫成具體的值,其次,每個shard會根據自己的資料的範圍來重寫查詢為 match_all或者是match_none查詢,所以現在的查詢能夠被有效的快取,並且只有個別資料有變化的Shard才需要重新計算,大大提升查詢速度。
另外再看看和Scroll相關的吧,現在新增了一個:Sliced Scroll
用過Scroll介面吧,很慢?如果你資料量很大,用Scroll遍歷資料那確實是接受不了,現在Scroll介面可以併發來進行資料遍歷了,
每個Scroll請求,可以分成多個Slice請求,可以理解為切片,各Slice獨立並行,利用Scroll重建或者遍歷要快很多倍。
看看這個demo

可以看到兩個scroll請求,id分別是0和1,max是最大可支援的並行任務,可以各自獨立進行資料的遍歷獲取。
我們再看看es在查詢優化這塊做的工作,
新增了一個Profile API
都說要致富先修路,要調優當然需要先監控啦,elasticsearch在很多層面都提供了stats方便你來監控調優,但是還不夠,其實很多情況下查詢速度慢很大一部分原因是糟糕的查詢引起的,玩過SQL的人都知道,資料庫服務的執行計劃(execution plan)非常有用,可以看到那些查詢走沒走索引和執行時間,用來調優,elasticsearch現在提供了Profile API來進行查詢的優化,只需要在查詢的時候開啟profile:true就可以了,一個查詢執行過程中的每個元件的效能消耗都能收集到。
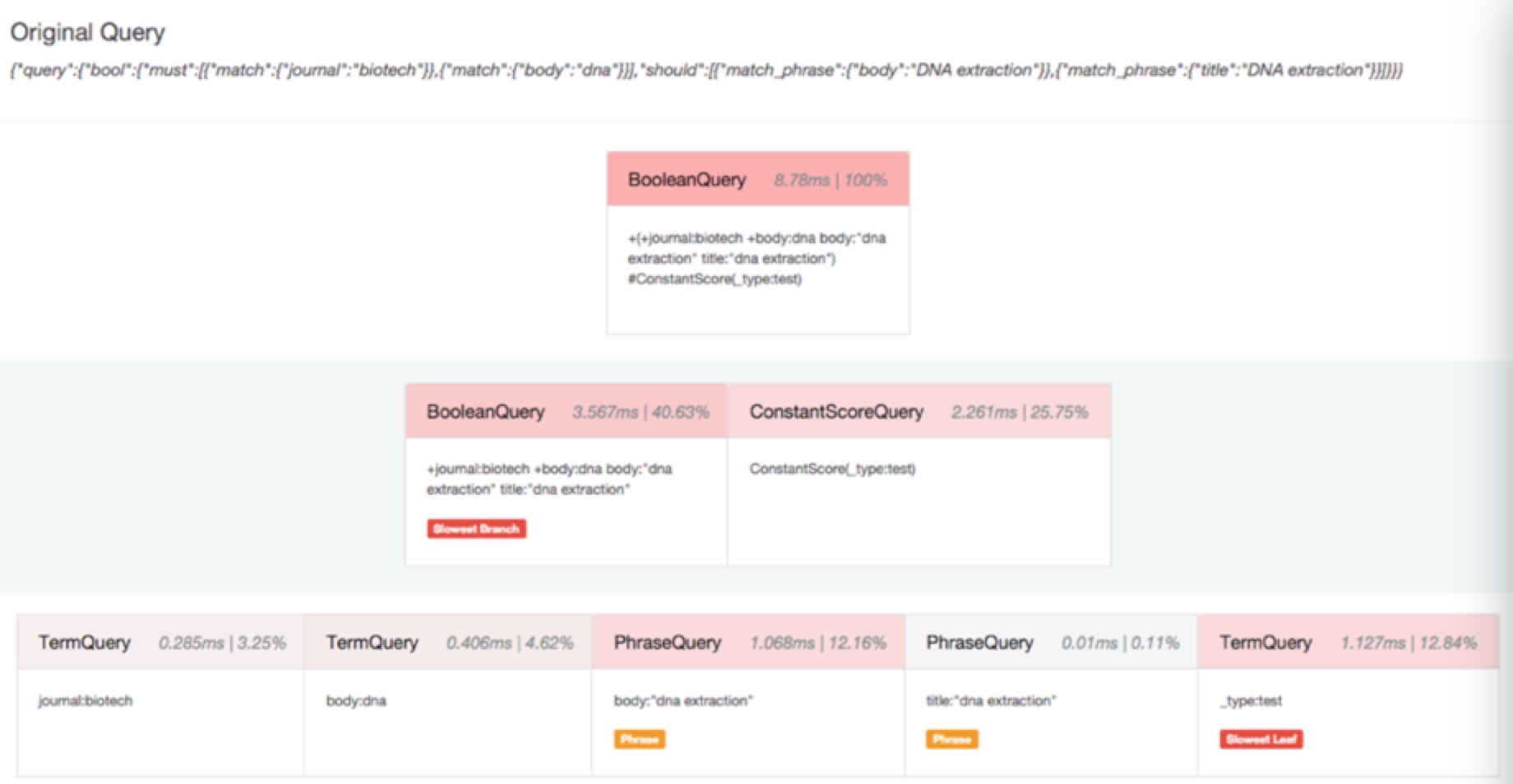
那個子查詢耗時多少,佔比多少,一目瞭然,同時支援search和aggregation的profile
還有一個和翻頁相關的問題,就是深度分頁,是個老大難的問題,因為需要全域性排序(number_of_shards * (from + size)),所以需要消耗大量記憶體,以前的es沒有限制,有些同學翻到幾千頁發現es直接記憶體溢位掛了,後面elasticsearch加上了限制,from+size不能超過1w條,並且如果需要深度翻頁,建議使用scroll來做,但是scroll有幾個問題,第一個是沒有順序,直接從底層segment進行遍歷讀取,第二個實時性沒法保證,scroll操作有狀態,es會維持scroll請求的上下文一段時間,超時後才釋放,另外你在scroll過程中對索引資料進行了修改了,這個時候scroll介面是拿不到的,靈活性較差,現在有一個新的 Search After 機制,其實和scroll類似,也是遊標的機制,它的原理是對文件按照多個欄位進行排序,然後利用上一個結果的最後一個文件作為起始值,拿size個文件,一般我們建議使用_uid這個欄位,它的值是唯一的id。來看一個Search After 的demo 吧,比較直觀的理解一下

上面的demo,search_after後面帶的兩個引數,就是sort的兩個結果,根據你的排序條件來的,三個排序條件,就傳三個引數
再看看跟索引與分片管理相關的新功能吧,新增了一個Shrink API
相信大家都知道elasticsearch索引的shard數是固定的,設定好了之後不能修改,如果發現shard太多或者太少的問題,之前如果要設定Elasticsearch的分片數,只能在建立索引的時候設定好,並且資料進來了之後就不能進行修改,如果要修改,只能重建索引,現在有了Shrink介面,它可將分片數進行收縮成它的因數,如之前你是15個分片,你可以收縮成5個或者3個又或者1個,那麼我們就可以想象成這樣一種場景,在寫入壓力非常大的收集階段,設定足夠多的索引,充分利用shard的並行寫能力,索引寫完之後收縮成更少的shard,提高查詢效能。
這裡是一個API呼叫的例子

上面的例子對my_source_index伸縮成一個分片的my_targe_index,使用了最佳壓縮. 有人肯定會問慢不慢?非常快! Shrink的過程會藉助作業系統的Hardlink進行索引檔案的連結,這個操作是非常快的,毫秒級Shrink就可收縮完成,當然windows不支援hard link,需要拷貝檔案,可能就會很慢了。
再來看另外一個比較有意思的新特性,除了有意思,當然還很強大,新增了一個Rollover API
前面說的這種場景對於日誌類的資料非常有用,一般我們按天來對索引進行分割(資料量更大還能進一步拆分),我們以前是在程式裡設定一個自動生成索引的模板,大家用過logstash應該就記得有這麼一個模板logstash-[YYYY-MM-DD]這樣的模板,現在es5.0裡面提供了一個更加簡單的方式:Rollover API, API呼叫方式如下:

從上面可以看到,首先建立一個logs-0001的索引,它有一個別名是logs_write,然後我們給這個logs_write建立了一個rollover規則, 即這個索引文件不超過1000個或者最多儲存7天的資料,超過會自動切換別名到logs-0002,你也可以設定索引的setting、mapping等引數,剩下的es會自動幫你處理。這個特性對於存放日誌資料的場景是極為友好的。
另外關於索引資料,大家之前經常重建,資料來源在各種場景,重建起來很是頭痛,那就不得不說說現在新加的Reindex介面了,Reindex可以直接在Elasticsearch叢集裡面對資料進行重建,如果你的mapping因為修改而需要重建,又或者索引設定修改需要重建的時候,藉助Reindex可以很方便的非同步進行重建,並且支援跨叢集間的資料遷移。
比如按天建立的索引可以定期重建合併到以月為單位的索引裡面去。
當然索引裡面要啟用_source。
來看看這個demo吧,重建過程中,還能對資料就行加工。

再看看跟Java開發者最相關的吧,就是 RestClient了
5.0裡面提供了第一個Java原生的REST客戶端SDK,相比之前的TransportClient,版本依賴繫結,叢集升級麻煩,不支援跨Java版本的呼叫等問題,新的基於HTTP協議的客戶端對Elasticsearch的依賴解耦,沒有jar包衝突,提供了叢集節點自動發現、日誌處理、節點請求失敗自動進行請求輪詢,充分發揮Elasticsearch的高可用能力,並且效能不相上下。 #19055
然後我們再看看其他的特性吧:
新增了一個Wait for refresh功能,簡單來說相當於是提供了文件級別的Refresh, 索引操作新增refresh引數,大家知道elasticsearch可以設定refresh時間來保證資料的實時性,refresh時間過於頻繁會造成很大的開銷,太小會造成資料的延時,之前提供了索引層面的_refresh介面,但是這個介面工作在索引層面,我們不建議頻繁去呼叫,如果你有需要修改了某個文件,需要客戶端實時可見怎麼辦?
在 5.0中,Index、Bulk、Delete、Update這些資料新增和修改的介面能夠在單個文件層面進行refresh控制了,有兩種方案可選,一種是建立一個很小的段,然後進行重新整理保證可見和消耗一定的開銷,另外一種是請求等待es的定期refresh之後再返回。
呼叫例子:

再一個比較重要的特性就是IngestNode了,
大家之前如果需要對資料進行加工,都是在索引之前進行處理,比如logstash可以對日誌進行結構化和轉換,現在直接在es就可以處理了,
目前es提供了一些常用的諸如convert、grok之類的處理器,在使用的時候,先定義一個pipeline管道,裡面設定文件的加工邏輯,在建索引的時候指定pipeline名稱,那麼這個索引就會按照預先定義好的pipeline來處理了;
Demo again.

上圖首先建立了一個名為my-pipeline-id的處理管道,然後接下來的索引操作就可以直接使用這個管道來對foo欄位進行操作了,上面的例子是設定foo欄位為bar值。
上面的還不太酷,我們再來看另外一個例子,現在有這麼一條原始的日誌,內容如下:
{
“message”: “55.3.244.1 GET /index.html 15824 0.043”
}
google之後得知其Grok的pattern如下:)
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
那麼我們使用Ingest就可以這麼定義一個pipeline:
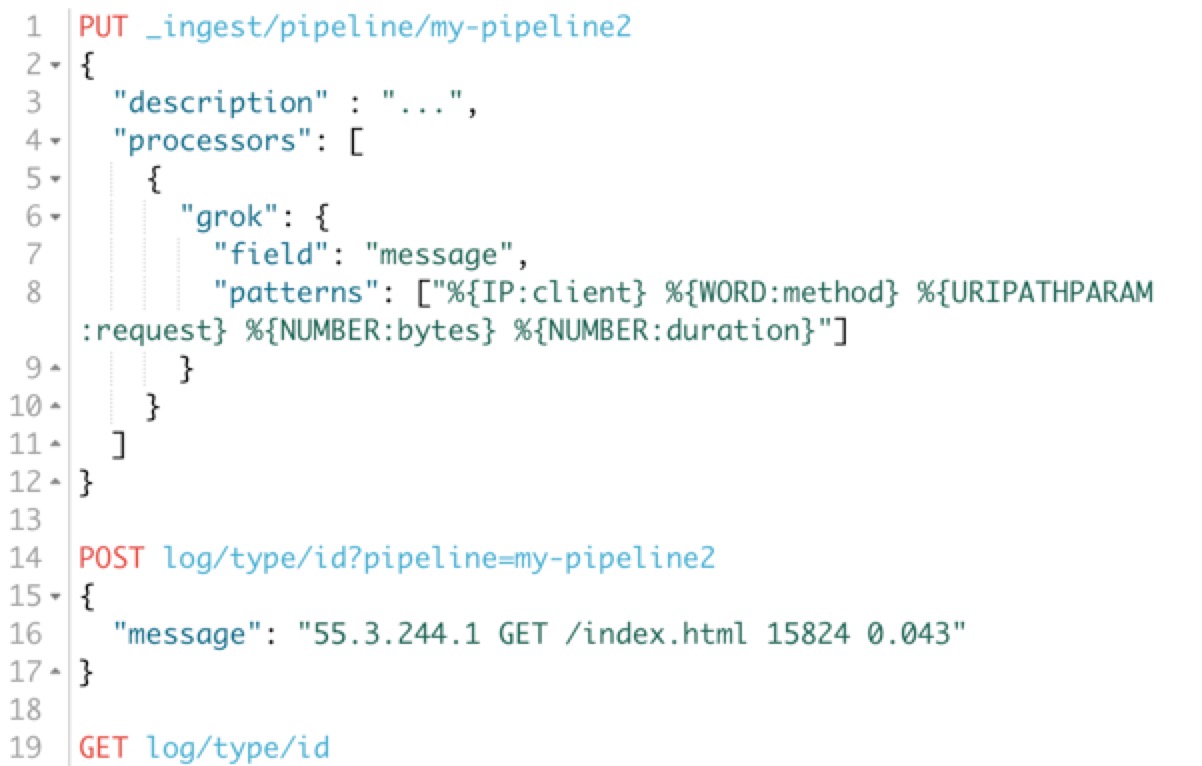
那麼通過我們的pipeline處理之後的文件長什麼樣呢,我們獲取這個文件的內容看看:

很明顯,原始欄位message被拆分成了更加結構化的物件了。
再看看指令碼方面的改變
還記得Groove指令碼的漏洞吧,Groove指令碼開啟之後,如果被人誤用可能帶來的漏洞,為什麼呢,主要是這些外部的指令碼引擎太過於強大,什麼都能做,用不好或者設定不當就會引起安全風險,基於安全和效能方面,我們自己開發了一個新的指令碼引擎,名字就叫Painless,顧名思義,簡單安全,無痛使用,和Groove的沙盒機制不一樣,Painless使用白名單來限制函式與欄位的訪問,針對es的場景來進行優化,只做es資料的操作,更加輕量級,速度要快好幾倍,並且支援Java靜態型別,語法保持Groove類似,還支援Java的lambda表示式。
我們對比一下效能,看下圖
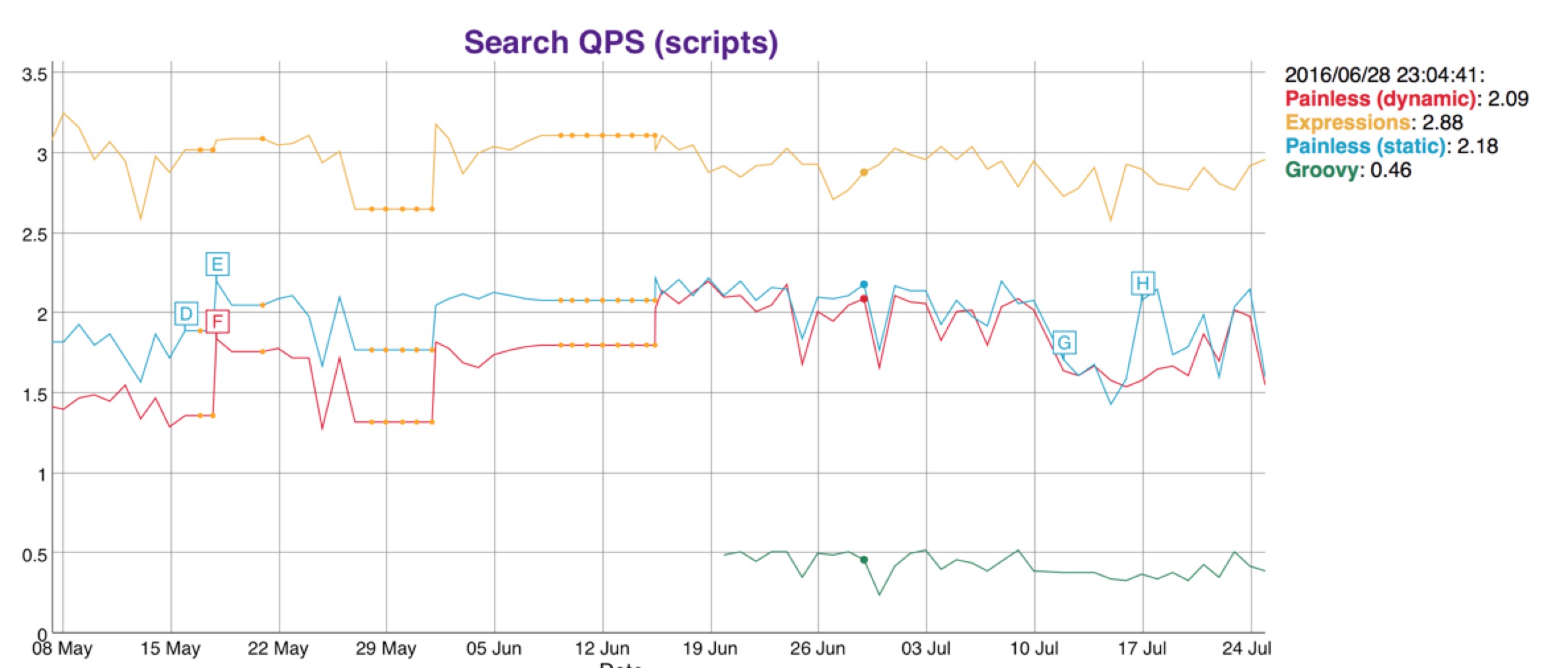
Groovy是弱弱的綠色的那根。
再看看如何使用:
def first = input.doc.first_name.0;
def last = input.doc.last_name.0;
return first + " " + last;是不是和之前的寫法差不多, 或者還可以是強型別(10倍速度於上面的動態型別)
String first = (String)((List)((Map)input.get("doc")).get("first_name")).get(0);
String last = (String)((List)((Map)input.get("doc")).get("last_name")).get(0);
return first + " " + last;指令碼可以在很多地方使用,比如搜尋自定義評分;更新時對欄位進行加工等, 如:
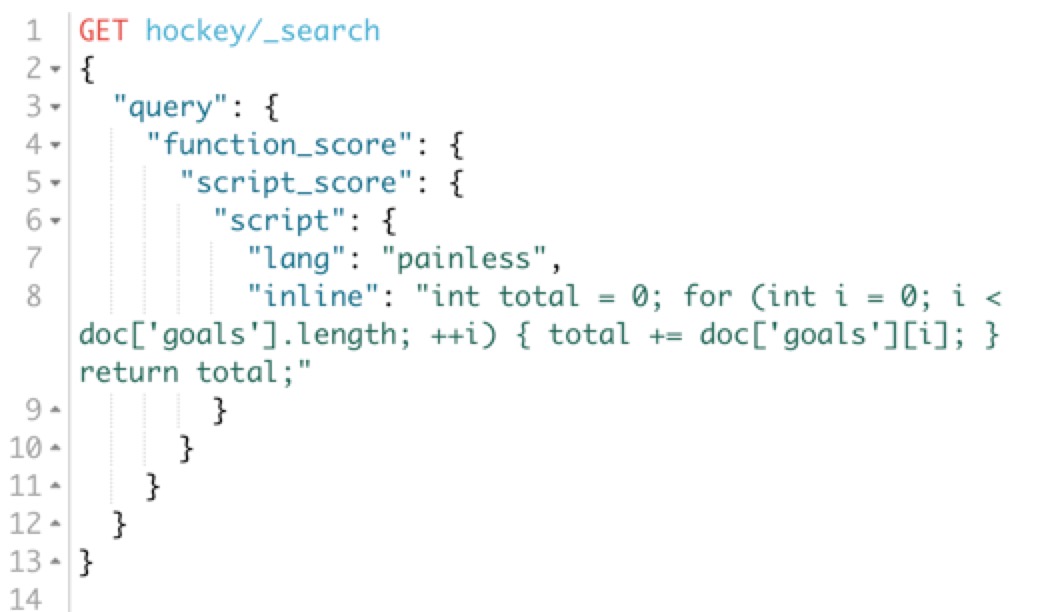
再來看看基礎架構方面的變化
新增:Task Manager
這個是5.0 引入任務排程管理機制,用來做
離線任務的管理,比如長時間執行的reindex和update_by_query等都是執行在TaskManager機制之上的,並且任務是可管理的,你可以隨時cancel掉,並且任務狀態持久化,支援故障恢復;
還新增一個:Depreated logging
大家在用ES的時候,其實有些介面可能以及打上了Depreated標籤,即廢棄了,在將來的某個版本中就會移除,你當前能用是因為一般廢棄的介面都不會立即移除,給足夠的時間遷移,但是也是需要知道哪些不能用了,要改應用程式碼了,所以現在有了Depreated日誌,當開啟這個日誌之後,你呼叫的介面如果已經是廢棄的介面,就會記錄下日誌,那麼接下來的事情你就知道你應該怎麼做了。
新增一個: Cluster allocation explain API
『誰能給我一個shard不能分配的理由』,現在有了,大家如果之前遇到過分片不能正常分配的問題,但是不知道是什麼原因,只能嘗試手動路由或者重啟節點,但是不一定能解決,其實裡面有很多原因,現在提供的這個explain介面就是告訴你目前為什麼不能正常分配的原因,方便你去解決。
另外在資料結構這塊,新增: half_float 型別
只使用 16 位 足夠滿足大部分儲存監控數值型別的場景,支援範圍:2負24次方 到 65504,但是隻佔用float一半的儲存空間。
Aggregation新增: Matrix Stats Aggregation #18300
金融領域非常有用的,可計算多個向量元素協方差矩陣、相關係數矩陣等等
另外一個重要的特性:為索引寫操作新增順序號 #10708
大家知道es是在primary上寫完然後同步寫副本,這些請求都是併發的,雖然可以通過version來控制衝突,
但是沒法保證其他副本的操作順序,通過寫的時候產生順序號,並且在本地也寫入checkpoint來記錄操作點, 這樣在副本恢復的時候也可以知道當前副本的資料位置,而只需要從指定的資料開始恢復就行了,而不是像以前的粗暴的做完整的檔案同步,另外這些順序號也是持久化的,重啟後也可以快速恢復副本資訊,想想以前的大量無用拷貝吧和來回倒騰資料吧。
我們再看看mapping這塊的改進吧
引入新的欄位型別Text/Keyword 來替換 String
以前的string型別被分成Text和Keyword兩種型別,keyword型別的資料只能完全匹配,適合那些不需要分詞的資料,
對過濾、聚合非常友好,text當然就是全文檢索需要分詞的欄位型別了。將型別分開的好處就是使用起來更加簡單清晰,以前需要設定analyzer和index,並且有很多都是自定義的分詞器,從名稱根本看不出來到底分詞沒有,用起來很麻煩。另外string型別暫時還在的,6.0會移除
還有關於Index Settings 的改進
Elasticsearch的配置實在太多,在以前的版本間,還移除過很多無用的配置,經常弄錯有沒有?現在,配置驗證更加嚴格和保證原子性,如果其中一項失敗,那個整個都會更新請求都會失敗,不會一半成功一半失敗。下面主要說兩點:
- 設定可以重設會預設值,只需要設定為
null即可 - 獲取設定介面新增引數
?include_defaults,可以直接返回所有設定和預設值
叢集處理的改進: Deleted Index Tombstones
在以前的es版本中,如果你的舊節點包含了部分索引資料,但是這個索引可能後面都已經刪掉了,你啟動這個節點之後,會把索引重新加到叢集中,是不是覺得有點陰魂不散,現在es5.0會在叢集狀態資訊裡面保留500個刪除的索引資訊,所以如果發現這個索引是已經刪除過的就會自動清理,不會再重複加進來了。
文件物件的改進: 欄位名重新支援英文句號,再2.0的時候移除過dot在欄位名中的支援,現在問題解決了,又重新支援了。
es會認為下面兩個文件的內容一樣:

還有其他的一些改進,快速過一下吧,時間有限
- Cluster state的修改現在會和所有節點進行ack確認
- Shard的一個副本如果失敗了,Primary標記失敗的時候會和Master節點確認完畢再返回。
- 使用UUID來作為索引的物理的路徑名,有很多好處,避免命名的衝突
- _timestamp 和 _ttl已經移除,需要在Ingest或者程式端處理。
- ES可直接用HDFS來進行備份還原(Snapshot/Restore )了 #15191
- Delete-by-query和Update-by-query重新回到core,以前是外掛,現在可以直接使用了,也是構建在Reindex機制之上
- HTTP請求預設支援壓縮,當然http呼叫端需要在header資訊裡面傳對應的支援資訊。
- 建立索引不會再讓叢集變紅了,不會因為這個卡死叢集了
- 預設使用BM25評分演算法,效果更佳,之前是TF/IDF
- 快照Snapshots新增UUID解決衝突 #18156
- 限制索引請求大小,避免大量併發請求壓垮ES #16011
- 限制單個請求的shards數量,預設1000個,避免誤用 #17396
- 移除 site plugins,就是說head、bigdesk都不能直接裝es裡面了,不過可以部署獨立站點(反正都是靜態檔案)或開發kibana外掛 #16038
- 允許現有parent型別新增child型別 #17956
這個功能對於使用parent-child特性的人應該非常有用
支援分號(;)來分割url引數,與符號(&)一樣 #18175
比如下面這個例子
curl http://localhost:9200/_cluster/health?level=indices;pretty=true
好吧,貌似很多,其實上面說的還只是眾多特性和改進的一部分,es5.0做了非常非常多工作,本來還打算講講bug修復的,但是太多了,時間有限,一些重要的bug在2.x都已經第一時間解決了,
大家可以檢視下面的連結瞭解更多更詳細的更新日誌:
謝謝大家,今天的分享內容就是上面這些,再次感謝大家參與這次分享活動,感謝聊聊架構社群提供的免費交流機會。

有問到是否有用es做hbase的二級索引的,這種案例說實話比較少,因為成本比較高,在兩套分散式系統裡面做結合,並且要滿足足夠的效能,有點難度,不建議這樣去做。
批量更新資料 會出現少量資料更新不成功
這個首先要看少量失敗的原因是什麼,es的返回資訊裡面會包含具體的資訊,如果json格式不合法也是會失敗的
問:ik外掛有沒有計劃支援同義詞,專有名詞熱更新?對於詞庫更新比較頻繁的應用場景,只能採取全部重新建立索引的方式嗎?
同義詞有單獨的filter,可以和ik結合一起使用的,關於熱更新這個確實是需要重建,詞庫變化之後,分詞產生的term不一樣了,不重建的話,倒排很可能匹配不上,查詢會失敗。
問:老師,你好,我有個問題想諮詢一下,我們原來的商品基本資料,商品評價資料,收藏量這些都在mysql裡,但我們現在想上es,我們想把商品的基本資料放es,收藏、評價這些實時資料,還是放mysql,但做排序功能的時候,會參考一個商品的收藏量,評價量,這時候在還涉及資料分頁的情況下,怎麼結合es和mysql的資料進行排序呢?
這個問題得具體看業務場景,如果更新頻繁,但是還在es承受能力範圍和業務響應指標內,可以直接放es裡面,在es裡面做排序,如果太大,建議放外部儲存,外部儲存和es的結合方式又有很多種,收藏評價是否真的需要那麼實時?另外es的評分機制是可以擴充套件的,在評分階段使用自定義外掛讀取外部資料來源,進行混合打分也是可行的。
問:現在大agg查詢可以cancel嗎
現在還不能,目前暫時還沒計劃
問:128g記憶體的機器,官方建議機器上放兩個es例項,目前也是推薦這樣做嗎
這個其實看場景的,單臺機器上面的索引比較大的話,建議多留一點給作業系統來做快取,多個例項可以提供足夠吞吐。
問:請問在es5中,每個伺服器有256G記憶體,那每個伺服器帶的儲存多少比較合適?是24T,48T還是可以更多?
這個看場景啦,有超過48T的
問:請問下Elastic Stack是隻要安裝一次這個就行,還是要像原來elk一樣,分別安裝不同的元件?
安裝方式和之前一樣的
問:請問es中的如何做到按某個欄位去重?具體問題是這樣的,我們有一個文章索引,其中有2億資料量,每次搜尋的結果總是存在大量重複的title,我們希望在查詢時能根據title進行去重。也就是Field Collapsing特性,官方有一個通過terms aggregation進行去重的方案,但效果不是很理想,仍然會有很多重複,我們希望哪怕是按title嚴格相等來去重也可以接受。 另外我們有一個通過simhash來去重的思路,就是計算title的simhash,一併存入索引,在搜尋階段通過simhash計算相似性,但這需要全量重新計算,資料量太大。所以還是希望能在不動現有索引的情況下,通過某種技巧,實現這個功能。
直接去重,這個目前沒有比較好的方案,不過很多變通的做法,首先你的場景需要確認,title重複是不是不允許的,如果是,那麼建索引的時候就可以hash掉作為主鍵,這樣就不會有重複的了,如果你覺得原始資料也要,那麼索引階段產生一個獨立的去除title的索引,來做join,當然還是要看你業務的場景具體研究。
問:硬體受限的情況下,清理過期資料的策略
如果你的資料結構固定,結合5.0的Rollover介面,估計能夠承載的最大索引,定期檢測刪索引就行了。