
介紹一個對陌生程式快速進行效能瓶頸分析的技巧
前言
工作多年,一直做的是curd系統。前幾年做的系統應用場景,大多對資料庫依賴比較重。例如報表統計,資料遷移,批量對賬等。所以這些系統出現效能瓶頸一般出在資料庫操作上面。
如果程式因為資料庫操作出現效能瓶頸是比較好辦的,因為oracle提供了完善的效能分析工具。往往使用awr報告簡單分析一下(top sql和top event)就可以獲知有哪些sql有異常。
找出問題sql,根據經驗進行優化即可,例如沒索引的加索引,有索引沒走的加hint,IO太慢的話加並行之類。之前我整理過的一些資料庫sql優化經驗在部落格裡面發過。



更多關於資料庫應用優化的知識見這裡:https://www.cnblogs.com/kingstarer/p/9613626.html
但今年做的系統,有時也會出現資料庫資源充足,但由於程式自身寫得不好,導致cpu消耗太高,系統反應緩慢的情況。
這種如果是自己寫的程式相對比較好處理,因為寫的時候大概會知道哪些地方容易出問題。
但有時也會有接手別人的程式出現問題需要優化的情況,這種以前我是都需要花時間重新看一下他們的原始碼,然後結合日誌分析問題出哪裡,效率相對比較低。
不過最近我發現一個工具,能直觀地統計出程式資源消耗,對於優化幫助特別大。今年我有幾次對專案組的程式做優化,都是先用它發現問題關鍵,然後再進行優化的。
這種方式比以前憑經驗分析好,因為有時自己覺得有問題的程式碼,優化後發現效果甚微。(程式碼使用頻率低,或者瓶頸出現在其它地方。)例如今年我曾經把系統取環境變數的程式碼,從原來直接使用getenv,改為從快取裡面取數(getenv是順序查詢,快取取是自己寫的二分查詢),但發現對於系統整體效能提高不到1%。
下面以一次專案組優化的過程為例,給大家介紹一下這個工具----callgrind的用法:
概述
callgrind是vallgrind工具家族中的一員,它相比其它效能測試工具的好處是不需要修改原始碼、編譯選項(推薦加-g,但不是必要的)、系統引數等。但也存在缺點,如分析過程中程式效能下降較大,無法對已啟動的程序進行效能分析,無法分析函式實際耗時(分析的是消耗cpu時間,如果存在sleep、wait之類函式會影響分析結果),對遞迴呼叫展示不友好等。不過好在我們專案中,這些缺點不太影響我們使用。
callgrind分析完程式後會使用Ir(指令執行的次數)來統計程式中函式呼叫消耗,同時還會建立函式呼叫關係圖,需要分析程式流程時可以參考。同時callgrind還能分析程式快取使用情況,幫助我們優化if和switch順序。還有分析鎖順序等其它功能。
每次執行結束時,它會把分析資料寫入一個檔案,之後我們可以通過callgrind_annotate或kcachegrind讀取分析結果展示成可讀的報告。
接下來我介紹callgrind的使用心得。
背景
rcc查詢業務由於業務量增長,現在部署了查詢的三臺機器平時cpu負荷接近50%,在交易量偏大時cpu會增漲到100%。
專案組臨時投入新 機器資源將cpu消耗控制到25~50%,以減少系統性能告警。但後續仍需對應用進行優化,以防故障再次發生。
問題還原與分析
在測試環境上經過一番配置,還原了系統故障現象。仔細觀察可以發現:
在併發數比較低時,系統cpu消耗較低,但併發數高一些時,系統cpu消耗急劇上漲,很快就到達100%,但此時tps基本不變。
| 併發數 |
cpu使用率 |
tps |
| 6 |
約60% |
73 |
| 12 |
約100% |
68 |
觀察top和vmstat資訊,發現兩個異常:
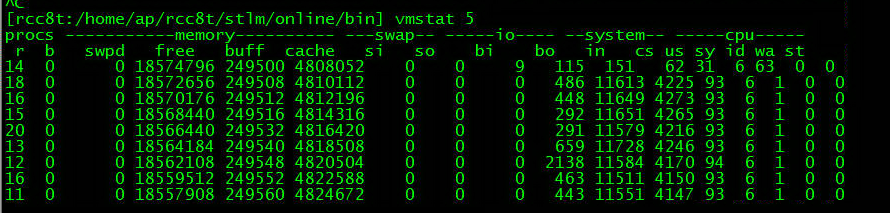
1 vmstat顯示user消耗超過90%,而sys只佔不到10%。對於非計算密集應用,這個比例有點高
2 top顯示系統消耗cpu最多的程序並非業務服務程序,而是加解密相關的服務程序
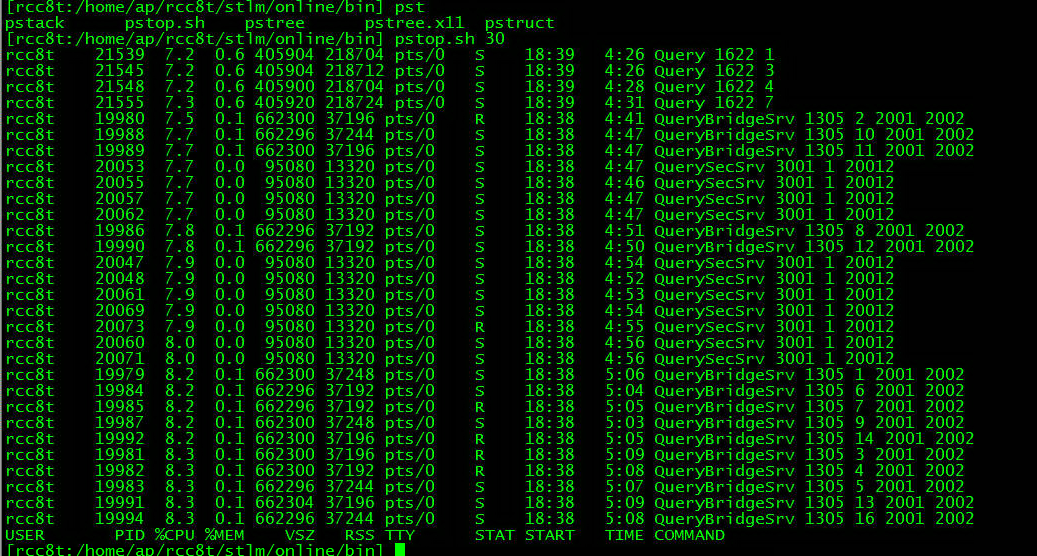
圖示:QueryBridgeSrv和QuerySecSrv消耗了比較多的cpu資源。而Query核心業務程序反而消耗得不是很多。(從下到上cpu消耗逐漸下降)
業務服務程式碼經常修改,專案組開發人員比較熟悉,通過日誌即可迅速定位問題出在哪。但是報文較驗轉換服務由於修改的比較少,比較難定位問題,所以決定使用callgrind輔助分析。
callgrind一般用法
對於一般的程式,我們可以直接啟動callgrind分析程式,只需要在命令列前面加上"valgrind --tool=callgrind ",如下:

等程式執行完退出後會在目錄生成分析檔案,命名為callgrind.out.程序號檔案,我們可以使用callgrind_annotate在命令列介面上對其進行分析,但一般是拿到windows環境下使用kcachegrind分析。

callgrind在專案中的用法
由於專案中的程式是以服務形式啟動的,不會自然退出,所以需要使用另外的方法收集分析結果檔案。
單程序程式QueryBridgeSrv分析方法:
由於QueryBridgeSrv服務是單程序程式,所以只需要直接啟動即可。
不過由於我們專案把很多程式啟動引數放在環境變數,不設定的話啟動會出異常。所以啟動前需要設定環境變數,可以使用以下指令碼獲取QueryBridgeSrv程式環境變數
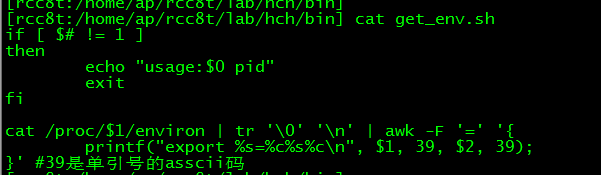
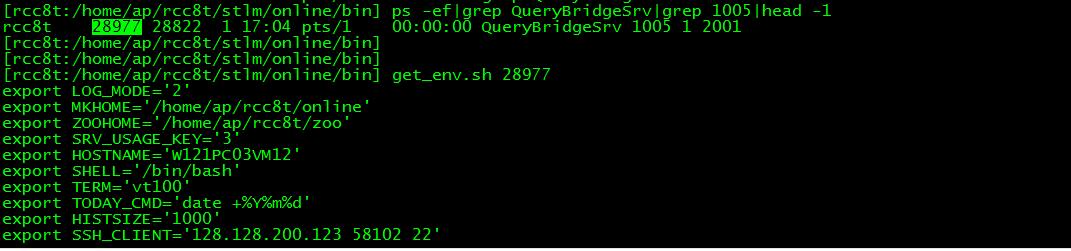
執行指令碼後即可獲取設定環境變數語句,執行後即可正常啟動
time valgrind --tool=callgrind --callgrind-out-file="callgrind.bridge_1305_%p.out" QueryBridgeSrv 1305 17 2001 2002 # callgrind-out-file選項是指定生成的分析檔名字 更多選項可參考man valgrind

程序啟動後我們就可以開始執行正常的測試用例,讓callgrind分析程式執行情況。等執行得差不多了,我們可以在其它會話視窗執行callgrind_control命令將收集的資訊檔案輸出。
callgrind_control選項也不少,一般我們會使用到以下兩個選項:
callgrind_control -d # dump出目前收集的資訊
callgrind_control -k # 停止callgrind(不會輸出收集檔案 所以先要dump)
多程序程式QuerySecSrv分析方法:
對於多程序程式,最好由專案的Daemon程序啟動。所以我們可以設計一個啟動指令碼放到bin目錄下面:

然後修改tbl_srv_param引數,將啟動程式名字由QuerySecSrv改為QuerySecSrv.sh
這樣Daemon就會啟動QuerySecSrv.sh,然後由QuerySecSrv.sh啟動callgrind對QuerySecSrv進行分析。
程序啟動後獲取分析結果檔案方法與QueryBridgeSrv一致。
kcachegrind介紹
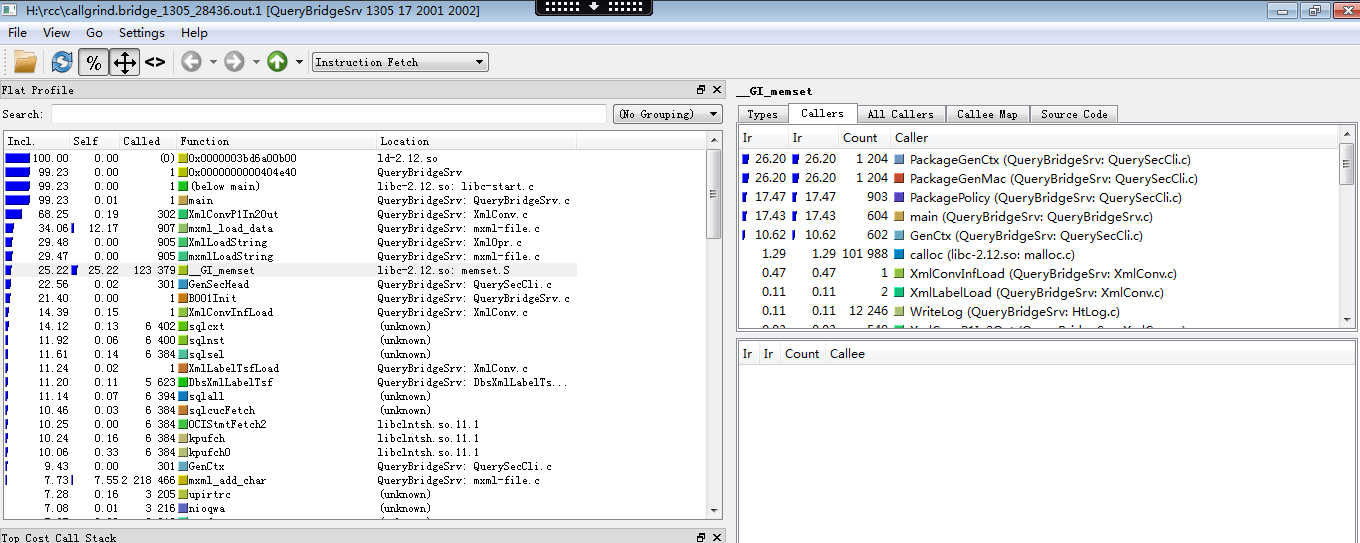
對於生成的檔案,我們可以使用kcachegrind進行分析:使用kcachegrind開啟之前我們分析QueryBridgeSrv的結果檔案(檔案一定要以"callgrind."開頭),顯示如下:

左上角的Flat Profile窗格,第一列是函式消耗的總資源(包括函式本身開銷和函式內部呼叫的子函式開銷之和),第二列是函式本身的開銷。
可以想象,main函式一般是系統中總開銷最大的,因為大部分函式是由main函式呼叫的。但是main函式自身消耗可能不多,大部分指令是它呼叫的其它函式消耗的。
右上角的窗格(後面稱callers窗格),我們一般用來顯示該函式被呼叫的資訊(callers),如圖,可以看出GenCtx函式只有一個呼叫者GenSecHead。
右下角視窗(後面稱callees窗格),我們一般用來顯示該函式呼叫其它函式資訊(callees),如圖,可以看出GenCtx函式呼叫了好多個函式及分別消耗的指令數。
因為我們一般不關心函式實際開銷,而是關心函式相對開銷,所以kcachegrind提供了兩個按鈕,把開銷顯示成百分比。
 (百分號控制的是Flat Profile視窗顯示方式,十字箭頭控制的是Callers和Callees窗格)
(百分號控制的是Flat Profile視窗顯示方式,十字箭頭控制的是Callers和Callees窗格)
按百分比顯示後我們可以清楚地看出memset函式佔用了程式開銷的73%,而且消耗在其自身。(Self)

對於一般應用,memset函式是沒有優化空間的,所以我們要觀察是哪些函式呼叫了memset這麼多次。
在Flat Profile視窗單擊memset函式,可以看到呼叫memset函式的資訊
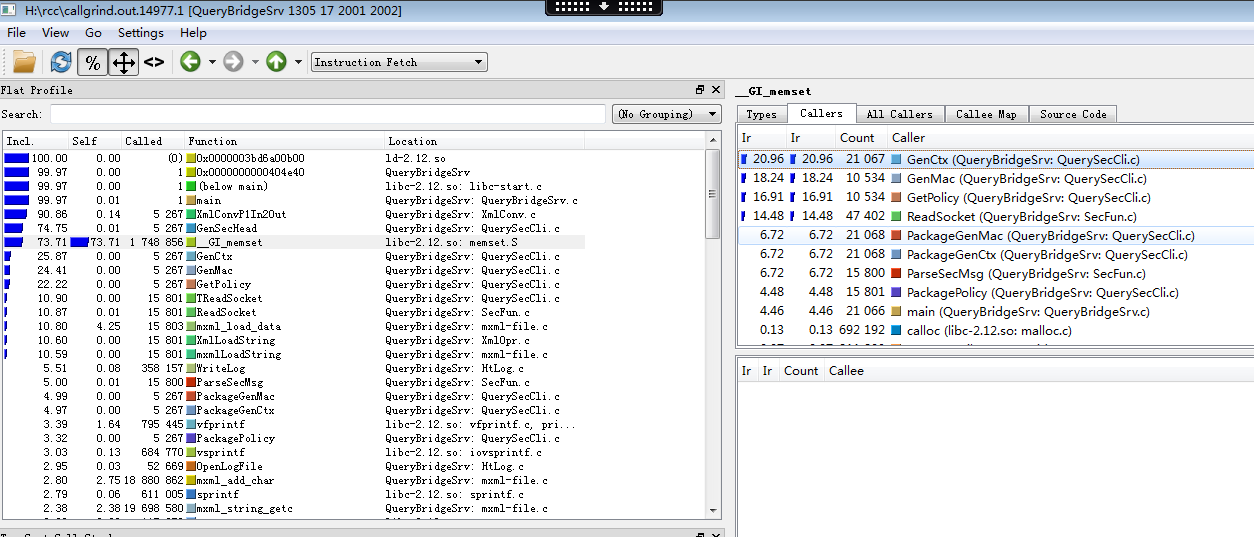
從上圖我們可以看出20%的memset呼叫消耗是由於GenCtx引起的,我們先看看這個函式。在Callers窗格雙擊,可以進到GenCtx函式的分析(分析過程可以使用工具欄的導航按鈕前後跳轉)
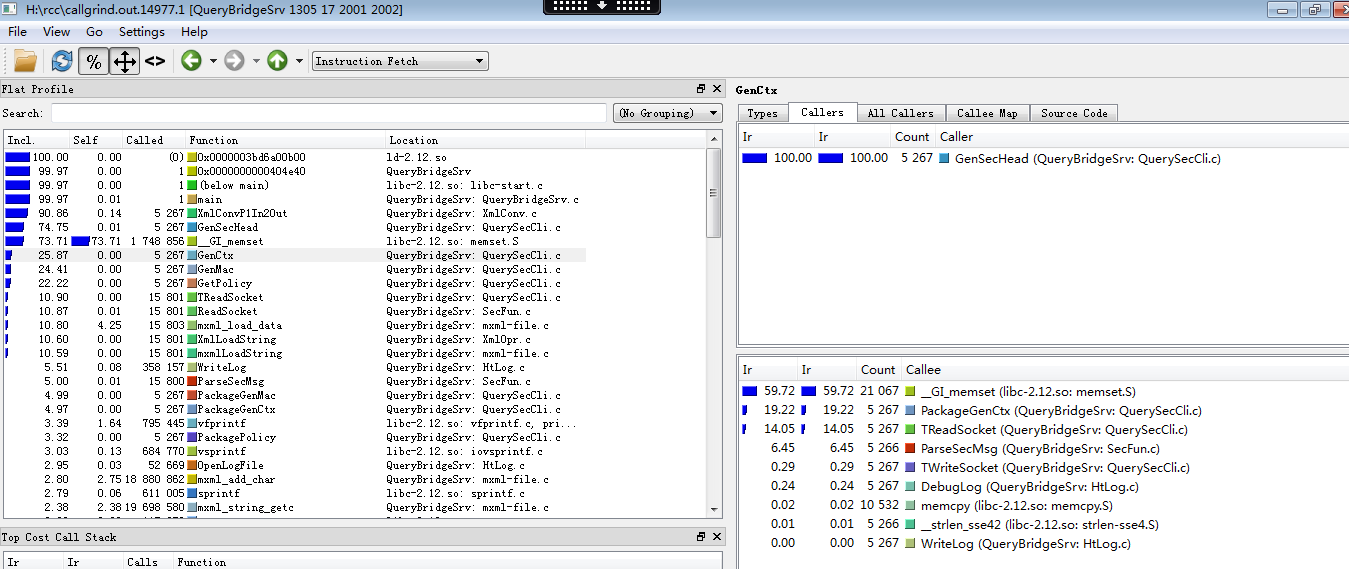
可以看到GenCtx函式50%的消耗在於memset,我們可以到對應函式看有沒有呼叫必要。
在Flat Profile窗格下拉列表選擇source file就可以看到函式所在原始檔。由於windows環境下程式碼路徑問題,無法在kcachegrind直接檢視程式碼資訊,只能另外開啟vs檢視程式碼。(根據網上介紹,使用callgrind_annotate可以直接看到每行程式碼消耗指令數,對於分析長函式幫助很大,暫時未在專案中實踐)
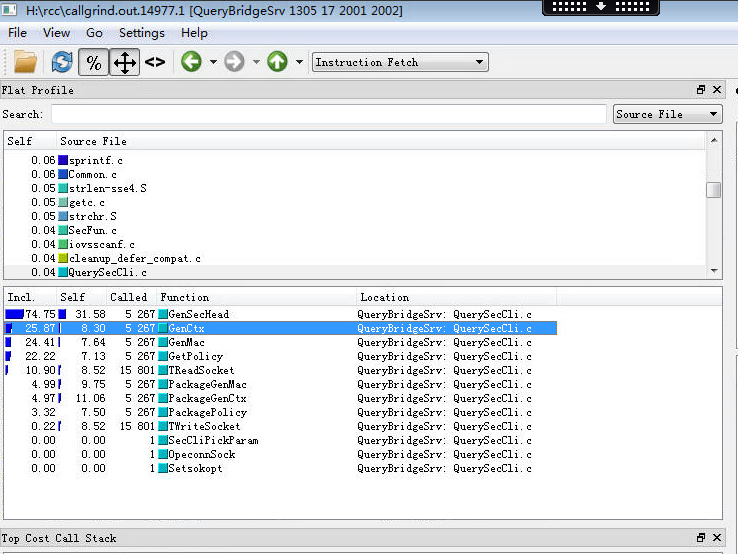
在原始碼裡面我們發現幾處memset呼叫,作用是把某大塊記憶體(395k)初始化為零。經分析,這幾處地方並不是特別需要呼叫memset。應是當時寫程式碼時使用防禦性程式設計技巧,寧殺錯,不放過,統一清零。當這個函式只調用一次時,這些操作對系統性能消耗不算多。但當業務量比較大,函式呼叫次數較多時,這種初始化操作會給系統帶來較大效能消耗。
把初始化程式碼程式碼註釋了(如下),重新編譯程式,驗證發現功能不受影響。
這裡本來應該要貼問題程式碼,但這裡是部落格,就不貼了,避免洩密風險。
//注意,這裡變數初始化為零,其實也可能導致隱式呼叫了memset(具體看編譯器實現)
繼續使用kcachegrind分析其它函式,把不必要的memset都改掉,再重新跑。發現memset消耗降低了很多。
用同樣方法對QuerySecSrv進行分析,發現也主要是memset消耗佔大頭,一樣修改。
kcachegrind輸出函式呼叫關係圖
使用kcachegrind還可以輸出函式呼叫關係及消耗資訊全域性檢視進行分析:
單擊main(或者其它想要分析的函式),在callees窗格切換到Call Graph選項,在出現的程式呼叫圖右鍵可以設定圖例選項。(一般建議修改Min.Node Cost選項,把5%改成1%,預設不顯示呼叫消耗低於5%的函式)
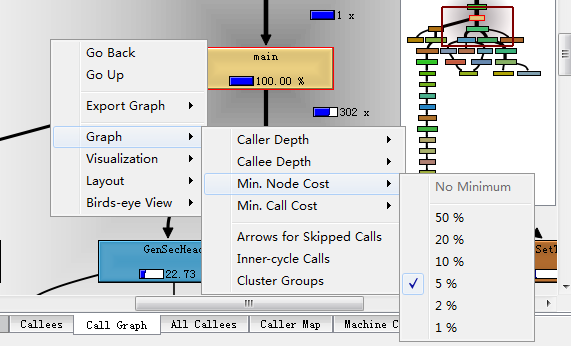
在kcachegrind看大圖片不方便,我們可以使用Export Graph功能匯出圖片,放到看圖工具裡面檢視。

這個功能對於學習程式邏輯也很有幫助。
成果
修改驗證通過後後,對系統重新進行非功能測試,結果如下:
| 併發數 |
cpu使用率 |
tps |
| 9 |
約60% |
252 |
| 30 |
約100% |
335 |
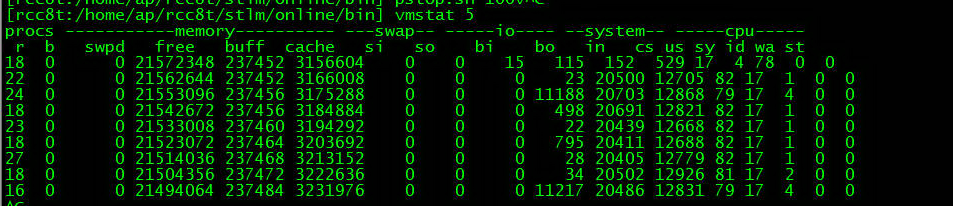
圖示:cpu使用率100%時us/sy有所下降
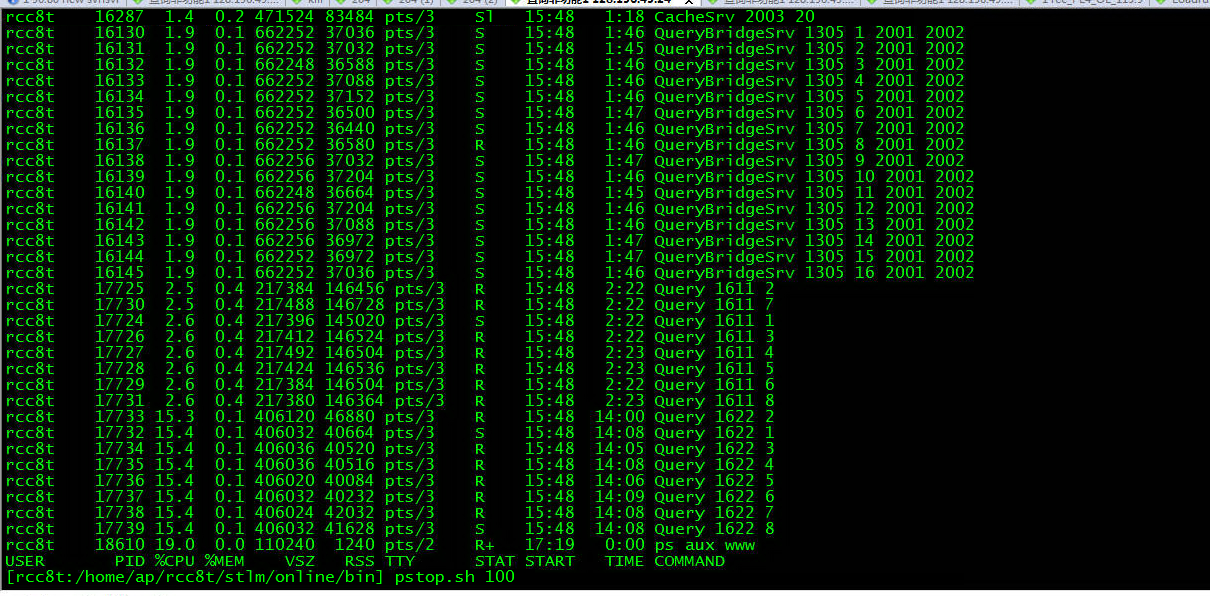
圖示:優化後報文較驗轉換服務已退出cpu佔用top10(從下到上cpu消耗逐漸下降)
結語
使用callgrind可以幫助我們快速定位系統性能瓶頸,根據callgrind分析結果針對性對程式進行優化,分析過程也可以輸出流程圖輔助我們理解程式和單元測試,推薦大家瞭解一下。