
一種基於CNN的自動化提取n-gram feanture的文字分類模型
今天寫的部落格主要參考了清華大學黃民烈老師團隊2018年在IJCAI上發表的paper《Densely Connected CNN with Multi-scale Feature Attention for Text Classification》。
這篇paper其實就是使用基於CNN的網路來進行文字的情感分類,但是它針對的問題是傳統的多層次的CNN網路使用static視窗來進行卷積,每次針對句子中提取n-gram feature 都是一樣的,如果遇到以下例子,就會影響模型的準確性:
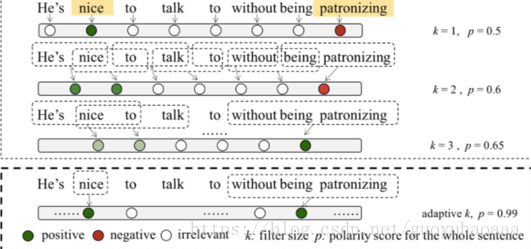
在該樣例中,不管是單純的1-gram還是3-gram都不太合適:針對“nice”這個單詞需要1-gram,但是針對“without being patronizing”這個片語需要3-gram。如何設計模型,讓其能夠自動地識別這種區別,是這篇paper主要解決的問題。
在正式介紹模型之前,作者提出了“a deeper model is more elegant than a wider solution”。因為使用小視窗的deeper model在模型高層次部分,其卷積器真正觀測到的原始句子序列中的視野是越來越大的。於是,參照在影象處理中常見的一種結構,作者設計了一種網路結構如下所示:
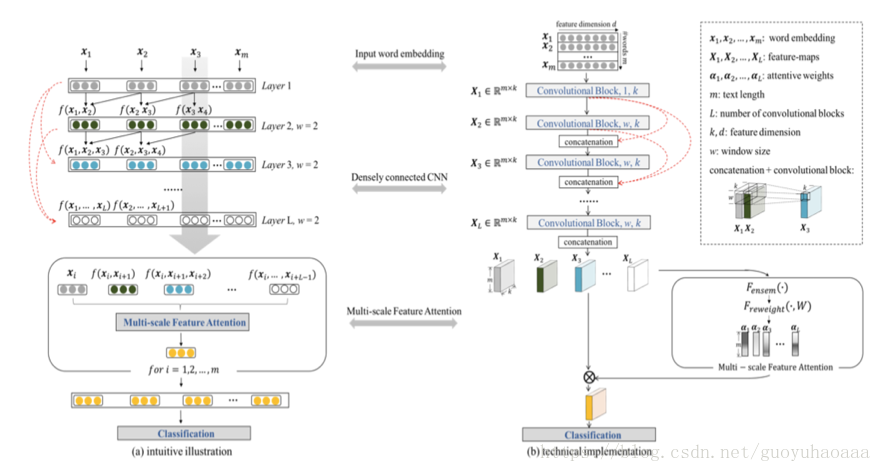
左邊是模型的邏輯運作示意圖,右邊是模型的真實實現示意圖。其實圖中最需要關注的就是那幾條紅線。假設模型的層次一共是層,那麼第層結果計算公式如下所示:
其中引數矩陣維度為,其中w代表了寬度,一個k代表了卷積器的個數,一個k代表了中間詞向量的維度。可以看出這裡面,…都是維度為的矩陣,代表了句子中單詞的個數。在使用卷積處理之後,結果依然是個維度為結果矩陣,然後使用矩陣的對位相加操作得當最終的為。
按照這樣的計算方式,最終模型的輸出層有,每一個矩陣的每一行都代表了以該行號為下標的n-gram,接下來就是設計一種attention從中選擇對分類最有意義的n-gram。整個過程如下圖所示:
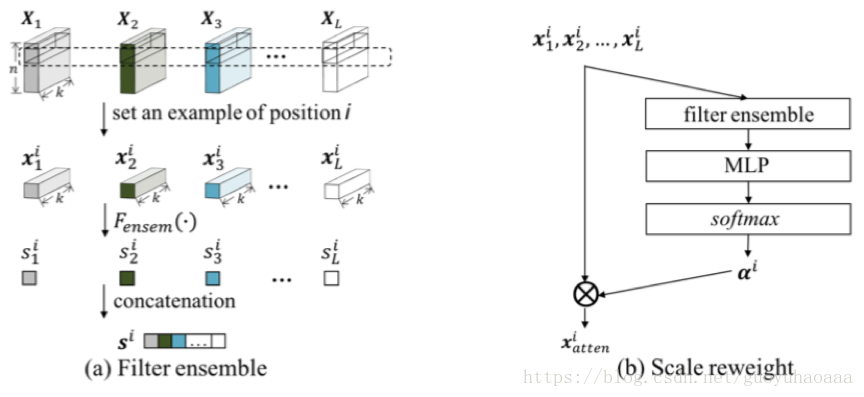
假設代表第l層下標為i的語義向量,設
其中
最終句子的表徵為