
C++常見面試題
第一篇
1、在函式內定義一個字元陣列,用gets函式輸入字串的時候,如果輸入越界,為什麼程式會崩潰?
答:因為gets無法截斷陣列越界部分,會將所有輸入都寫入記憶體,這樣越界部分就可能覆蓋其他內容,造成程式崩潰。
2、C++中引用與指標的區別
答:聯絡:引用是變數的別名,可以將引用看做操作受限的指標;
區別:
1) 指標是一個實體,而引用僅是個別名;
2)引用只能在定義時必須初始化,指標可以不初始化為空;
3)引用初始化之後其地址就不可改變(即始終作該變數的別名直至銷燬,即從一而終。注意:並不表示引用的值不可變,因為只要所指向的變數值改變。引用的值也就改變了),但指標所指地址是可變的;如下:
int m=23,n=12;
int& a=m;
a=12;//合法,相當於修改m=12
a=n;//不合法,引用指向的記憶體地址不可變
3、C/C++程式的記憶體分割槽
答:其實C和C++的記憶體分割槽還是有一定區別的,但此處不作區分:
1)、棧區(stack)— 由編譯器自動分配釋放 ,存放函式的引數值,區域性變數的值等。其
操作方式類似於資料結構中的棧。
2)、堆區(heap) — 一般由程式設計師分配釋放, 若程式設計師不釋放,程式結束時可能由OS回
收 。注意它與資料結構中的堆是兩回事,分配方式倒是類似於連結串列。
3)、全域性區(靜態區)(static)—,全域性變數和靜態變數的儲存是放在一塊的,初始化的
全域性變數和靜態變數在一塊區域, 未初始化的全域性變數和未初始化的靜態變數在相鄰的另
一塊區域。 - 程式結束後由系統釋放。
4)、文字常量區 —常量字串就是放在這裡的。 程式結束後由系統釋放
5)、程式程式碼區—存放函式體的二進位制程式碼。
棧區與堆區的區別:
1)堆和棧中的儲存內容:棧存區域性變數、函式引數等。堆儲存使用new、malloc申請的變數等;
2)申請方式:棧記憶體由系統分配,堆記憶體由自己申請;
3)申請後系統的響應:棧——只要棧的剩餘空間大於所申請空間,系統將為程式提供記憶體,否則將報異常提示棧溢位。
堆——首先應該知道作業系統有一個記錄空閒記憶體地址的連結串列,當系統收到程式的申請時,會遍歷該連結串列,尋找第一個空間大於所申請空間的堆結點,然後將該結點從空閒結點連結串列 中刪除,並將該結點的空間分配給程式;
4)申請大小的限制:Windows下棧的大小一般是2M,堆的容量較大;
5)申請效率的比較:棧由系統自動分配,速度較快。堆使用new、malloc等分配,較慢;
總結:棧區優勢在處理效率,堆區優勢在於靈活;
記憶體模型:自由區、靜態區、動態區;
根據c/c++物件生命週期不同,c/c++的記憶體模型有三種不同的記憶體區域,即:自由儲存區,動態區、靜態區。
自由儲存區:區域性非靜態變數的儲存區域,即平常所說的棧;
動態區: 用new ,malloc分配的記憶體,即平常所說的堆;
靜態區:全域性變數,靜態變數,字串常量存在的位置;
注:程式碼雖然佔記憶體,但不屬於c/c++記憶體模型的一部分;
4、快速排序的思想、時間複雜度、實現以及優化方法
答:快速排序的三個步驟:
(1)選擇基準:在待排序列中,按照某種方式挑出一個元素,作為 “基準”(pivot);
(2)分割操作:以該基準在序列中的實際位置,把序列分成兩個子序列。此時,在基準左邊的元素都比該基準小,在基準右邊的元素都比基準大;
(3)遞迴地對兩個序列進行快速排序,直到序列為空或者只有一個元素。
基準的選擇:
對於分治演算法,當每次劃分時,演算法若都能分成兩個等長的子序列時,那麼分治演算法效率會達到最大。
即:同一陣列,時間複雜度最小的是每次選取的基準都可以將序列分為兩個等長的;時間複雜度最大的是每次選擇的基準都是當前序列的最大或最小元素;
快排程式碼實現:
我們一般選擇序列的第一個作為基數,那麼快排程式碼如下:
[cpp] view plain copy print?- void quicksort(vector<int> &v,int left, int right)
- {
- if(left < right)//false則遞迴結束
- {
- int key=v[left];//基數賦值
- int low = left;
- int high = right;
- while(low < high) //當low=high時,表示一輪分割結束
- {
- while(low < high && v[high] >= key)//v[low]為基數,從後向前與基數比較
- {
- high–;
- }
- swap(v[low],v[high]);
- while(low < high && v[low] <= key)//v[high]為基數,從前向後與基數比較
- {
- low++;
- }
- swap(v[low],v[high]);
- }
- //分割後,對每一分段重複上述操作
- quicksort(v,left,low-1);
- quicksort(v,low+1,right);
- }
- }
void quicksort(vector<int> &v,int left, int right)
{
if(left < right)//false則遞迴結束
{
int key=v[left];//基數賦值
int low = left;
int high = right;
while(low < high) //當low=high時,表示一輪分割結束
{
while(low < high && v[high] >= key)//v[low]為基數,從後向前與基數比較
{
high--;
}
swap(v[low],v[high]);
while(low < high && v[low] <= key)//v[high]為基數,從前向後與基數比較
{
low++;
}
swap(v[low],v[high]);
}
//分割後,對每一分段重複上述操作
quicksort(v,left,low-1);
quicksort(v,low+1,right);
}
}注:上述陣列或序列v必須是引用型別的形參,因為後續快排結果需要直接反映在原序列中;
優化:
上述快排的基數是序列的第一個元素,這樣的對於有序序列,快排時間複雜度會達到最差的o(n^2)。所以,優化方向就是合理的選擇基數。
常見的做法“三數取中”法(序列太短還要結合其他排序法,如插入排序、選擇排序等),如下:
①當序列區間長度小於 7 時,採用插入排序;
②當序列區間長度小於 40 時,將區間分成2段,得到左端點、右端點和中點,我們對這三個點取中數作為基數;
③當序列區間大於等於 40 時,將區間分成 8 段,得到左三點、中三點和右三點,分別再得到左三點中的中數、中三點中的中數和右三點中的中數,再將得到的三個中數取中數,然後將該值作為基數。
具體程式碼只是在上一份的程式碼中將“基數賦值”改為①②③對應的程式碼即可:
- int key=v[left];//基數賦值
- if(right-left+1<=7){
- insertion_sort(v,left,right);//插入排序
- return;
- }elseif(right-left+1<=8){
- key=SelectPivotOfThree(v,left,right);//三個取中
- }else{
- //三組三個取中,再三個取中(使用4次SelectPivotOfThree,此處不具體展示)
- }
int key=v[left];//基數賦值
if(right-left+1<=7){
insertion_sort(v,left,right);//插入排序
return;
}else if(right-left+1<=8){
key=SelectPivotOfThree(v,left,right);//三個取中
}else{
//三組三個取中,再三個取中(使用4次SelectPivotOfThree,此處不具體展示)
}- void insertion_sort(vector<int> &unsorted,int left, int right) //插入排序演算法
- {
- for (int i = left+1; i <= right; i++)
- {
- if (unsorted[i - 1] > unsorted[i])
- {
- int temp = unsorted[i];
- int j = i;
- while (j > left && unsorted[j - 1] > temp)
- {
- unsorted[j] = unsorted[j - 1];
- j–;
- }
- unsorted[j] = temp;
- }
- }
- }
- int SelectPivotOfThree(vector<int> &arr,int low,int high) //三數取中,同時將中值移到序列第一位
- {
- int mid = low + (high - low)/2;//計算陣列中間的元素的下標
- //使用三數取中法選擇樞軸
- if (arr[mid] > arr[high])//目標: arr[mid] <= arr[high]
- {
- swap(arr[mid],arr[high]);
- }
- if (arr[low] > arr[high])//目標: arr[low] <= arr[high]
- {
- swap(arr[low],arr[high]);
- }
- if (arr[mid] > arr[low]) //目標: arr[low] >= arr[mid]
- {
- swap(arr[mid],arr[low]);
- }
- //此時,arr[mid] <= arr[low] <= arr[high]
- return arr[low];
- //low的位置上儲存這三個位置中間的值
- //分割時可以直接使用low位置的元素作為樞軸,而不用改變分割函數了
- }
void insertion_sort(vector<int> &unsorted,int left, int right) //插入排序演算法
{
for (int i = left+1; i <= right; i++)
{
if (unsorted[i - 1] > unsorted[i])
{
int temp = unsorted[i];
int j = i;
while (j > left && unsorted[j - 1] > temp)
{
unsorted[j] = unsorted[j - 1];
j--;
}
unsorted[j] = temp;
}
}
}
int SelectPivotOfThree(vector<int> &arr,int low,int high) //三數取中,同時將中值移到序列第一位
{
int mid = low + (high - low)/2;//計算陣列中間的元素的下標
//使用三數取中法選擇樞軸
if (arr[mid] > arr[high])//目標: arr[mid] <= arr[high]
{
swap(arr[mid],arr[high]);
}
if (arr[low] > arr[high])//目標: arr[low] <= arr[high]
{
swap(arr[low],arr[high]);
}
if (arr[mid] > arr[low]) //目標: arr[low] >= arr[mid]
{
swap(arr[mid],arr[low]);
}
//此時,arr[mid] <= arr[low] <= arr[high]
return arr[low];
//low的位置上儲存這三個位置中間的值
//分割時可以直接使用low位置的元素作為樞軸,而不用改變分割函數了
} 這裡需要注意的有兩點:
①插入排序演算法實現程式碼;
②三數取中函式不僅僅要實現取中,還要將中值移到最低位,從而保證原分割函式依然可用。
5、 IO模型——IO多路複用機制
答:預備知識介紹:
IO模型有4中:同步阻塞IO、同步非阻塞IO、非同步阻塞IO、非同步非阻塞IO;IO多路複用屬於IO模型中的非同步阻塞IO模型,在伺服器高效能IO構建中常常用到。
上述幾個模型原理如下圖:
同步阻塞IO: 同步非阻塞IO: IO多路複用(非同步阻塞IO):

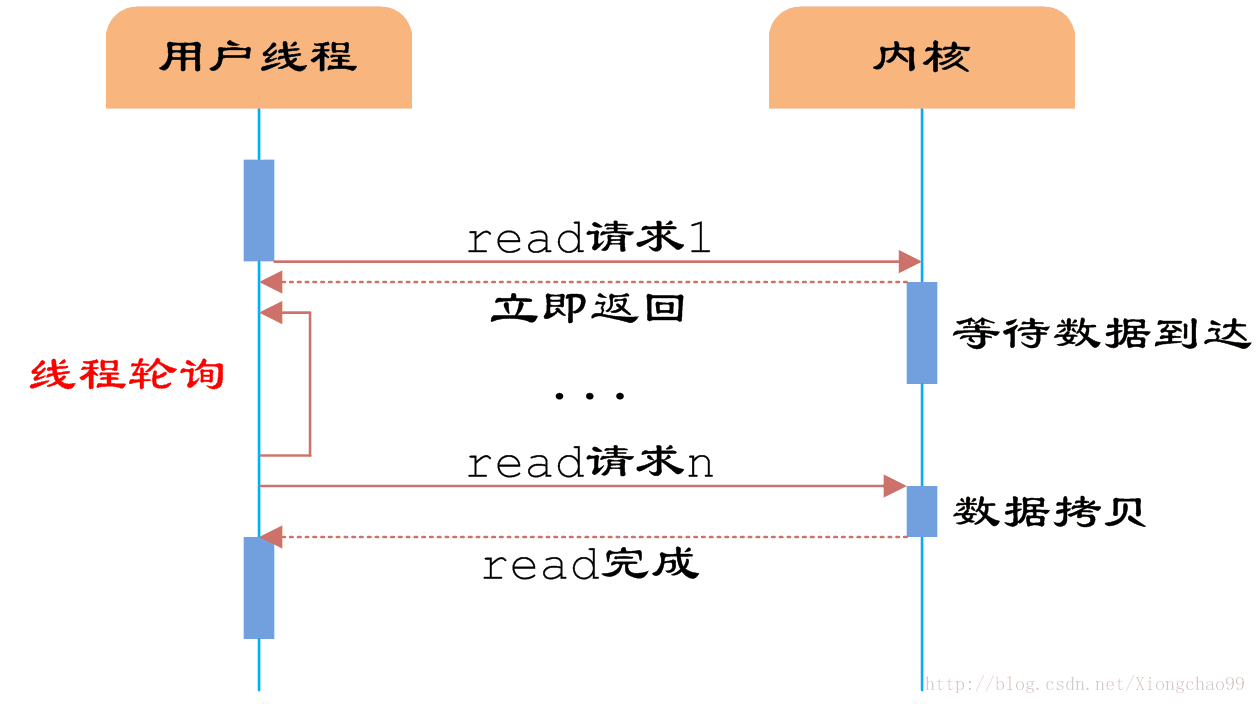
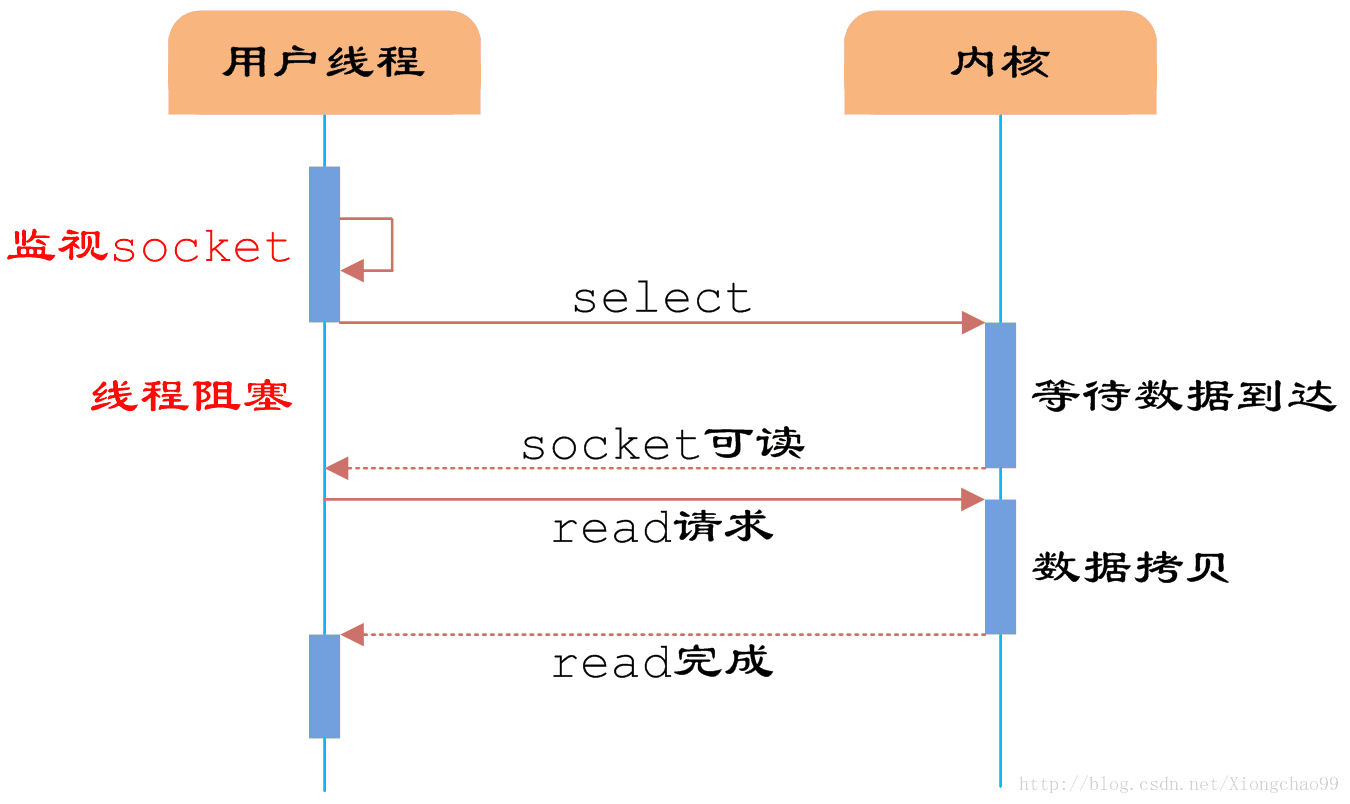
如上:同步非同步是表示服務端的,阻塞非阻塞是表示使用者端,所以可解釋為什麼IO多路複用(非同步阻塞)常用於伺服器端的原因;
檔案描述符(FD,又叫檔案控制代碼):描述符就是一個數字,它指向核心中的一個結構體(檔案路徑,資料區等屬性)。具體來源:Linux核心將所有外部裝置都看作一個檔案來操作,對檔案的操作都會呼叫核心提供的系統命令,返回一個fd(檔案描述符)。
下面開始介紹IO多路複用:
(1)I/O多路複用技術通過把多個I/O的阻塞複用到同一個select、poll或epoll的阻塞上,從而使得系統在單執行緒的情況下可以同時處理多個客戶端請求。與傳統的多執行緒/多程序模型比,I/O多路複用的最大優勢是系統開銷小,系統不需要建立新的額外程序或者執行緒。
(2)select,poll,epoll本質上都是同步I/O,因為他們都需要在讀寫事件就緒後自己負責進行讀寫,也就是說這個讀寫過程是阻塞的,而非同步I/O則無需自己負責進行讀寫,非同步I/O的實現會負責把資料從核心拷貝到使用者空間。
(3)I/O多路複用的主要應用場景如下:
伺服器需要同時處理多個處於監聽狀態或者多個連線狀態的套接字;
伺服器需要同時處理多種網路協議的套接字;
(4)目前支援I/O多路複用的系統呼叫有 select,poll,epoll,epoll與select的原理比較類似,但epoll作了很多重大改進,現總結如下:
①支援一個程序開啟的檔案控制代碼FD個數不受限制(為什麼select的控制代碼數量受限制:select使用位域的方式來傳遞關心的檔案描述符,因為位域就有最大長度,在linux下是1024,所以有數量限制);
②I/O效率不會隨著FD數目的增加而線性下降;
③epoll的API更加簡單;
(5)三種介面呼叫介紹:
①select函式呼叫格式:
[cpp] view plain copy print?- #include <sys/select.h>
- #include <sys/time.h>
- int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,conststruct timeval *timeout)
- //返回值:就緒描述符的數目,超時返回0,出錯返回-1
#include <sys/select.h>
- # include <poll.h>
- int poll ( struct pollfd * fds, unsigned int nfds, int timeout);
# include <poll.h>
int poll ( struct pollfd * fds, unsigned int nfds, int timeout);- #include <sys/epoll.h>
- int epoll_create(int size);
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
#include <sys/epoll.h>
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);更多細節待續……
6、常用的Linux命令
答:(1)檢視CPU利用率:top
(2)檢視當前目錄:pwd和ls(ls -a可以檢視隱藏目錄)
(3)切換目錄:cd
(4)檢視檔案佔用磁碟大小:du和df
(5)建立資料夾:mkdir
(6)新建檔案:touch
(7)檢視檔案:cat
(8)拷貝:cp 移動:mv 刪除:rm
(9)檢視程序:ps,如ps aux
(10)刪除程序:kill -9 PID,注-9是引數
(11)程式執行時間:time,使用時在命令前新增time即可,如:time ./test,可得到三個時間:real 0m0.020s,user 0m0.000s,sys 0m0.018s
grep命令(重要的常用命令之一):常用於開啟文字修改儲存,類似打windows開開TXT文字並修改;
sed命令(常用重要命令之一):主要用於對檔案的增刪改查;
awk命令(重要常用命令之一):取列是其擅長的;
find 命令(常與xargs命令配合):查詢 -type 檔案型別-name 按名稱查詢-exec執行命令;
xargs命令:配合find/ls查詢,將查詢結果一條條的交給後續命令處理;
gdb除錯工具:
要除錯C/C++的程式,一般有如下幾個步驟:
①首先在編譯時,我們必須要把除錯資訊加到可執行檔案中,編譯生成可執行檔案——-> g++ -g hello.cpp -o hello;
②啟動GDB編譯hello程式———-> gdb hello;
③顯示原始碼————> l;
④開始除錯:break 16——設定斷點在16行,break func——設定斷點在函式func()入口處,info break——檢視斷點資訊,n——單步執行,c——繼續執行程式,r——執行程式;p i——列印i的值,finish——退出程式,q——退出gdb。
7、C中變數的儲存型別有哪些?
答:C語言中的儲存型別有auto, extern, register, static 四種;
8、動態規劃的本質
答:動歸,本質上是一種劃分子問題的演算法,站在任何一個子問題的處理上看,當前子問題的提出都要依據現有的類似結論,而當前問題的結論是後面問題求解的鋪墊。任何DP都是基於儲存的演算法,核心是狀態轉移方程。
9、實踐中如何優化MySQL
答:四條從效果上第一條影響最大,後面越來越小。
① SQL語句及索引的優化
② 資料庫表結構的優化
③ 系統配置的優化
④ 硬體的優化
10、 什麼情況下設定了索引但無法使用
答:① LIKE語句,模糊匹配
② OR語句
③ 資料型別出現隱式轉化(如varchar不加單引號的話可能會自動轉換為int型)
11、 SQL語句的優化
答:alter儘量將多次合併為一次;
insert和delete也需要合併;
儘量使用union而不是or;
12.、資料庫索引的底層實現原理和優化
答:B樹,經過優化的B+樹。主要是在所有的葉子結點中增加了指向下一個葉子節點的指標,因此InnoDB建議為大部分表使用預設自增的主鍵作為主索引。
13、HTTP和HTTPS的主要區別
14、 如何設計一個高併發的系統
答:① 資料庫的優化,包括合理的事務隔離級別、SQL語句優化、索引的優化;
② 使用快取,儘量減少資料庫 IO;
③ 分散式資料庫、分散式快取;
④ 伺服器的負載均衡;
15. 兩條相交的單向連結串列,如何求他們的第一個公共節點
答:思想:
①如果兩個連結串列相交,則從相交點開始,後面的節點都相同,即最後一個節點肯定相同;
②從頭到尾遍歷兩個連結串列,並記錄連結串列長度,當二者的尾節點不同,則二者肯定不相交;
③尾節點相同,如果A長為LA,B為LB,如果LA>LB,則A前LA-LB個先跳過;
——更多如連結串列相關經典問題:求單向區域性迴圈連結串列的入、將兩個有序連結串列合併合成一個有序連結串列、連結串列逆序、求倒數第K個節點,判斷是否有環等。
16、求單向區域性迴圈連結串列的環入口
答:思路:
假如有快慢指標判斷一個連結串列有區域性環,連結串列起點是A,環的入口是B,快慢指標在環中的相遇點是C。那麼按照原來的運動方向,有AB=CB,這是可以證明的結論。具體如下圖說明:

17、IP地址如何在資料庫中儲存
答:常有以下幾種儲存方式:

說明一下:int型別的num儲存在解碼時是這樣做的:
65=num%256;num=num/256;
120=num%256;num=num/256;
……
18、new/delete和malloc/free的底層實現
答:malloc和new的區別:
1)malloc與free是C++/c語言的標準庫函式,new/delete是C++的運算子。它們都可用於申請動態記憶體和釋放記憶體;
2)new 返回指定型別的指標,並且可以自動計算所需要大小。而 malloc 則必須要由程式設計師計算位元組數,並且在返回後強行轉換為實際型別的指標;
3)new/delete在物件建立的同時可以自動執行建構函式初始化,在物件在消亡之前會自動執行解構函式。而malloc 只管分配記憶體,並不能對所得的記憶體進行初始化,所以得到的一片新記憶體中,其值將是隨機的;
既然new/delete的功能覆蓋了malloc/free,為什麼C++還要保留malloc/free?因為C++程式經常要呼叫C函式,而C程式只能用malloc/free管理動態記憶體。
new/delete、malloc/free底層實現原理:
概述:new/delete的底層實現是呼叫malloc/free函式實現的,而malloc/free的底層實現也不是直接操作記憶體而是呼叫系統API實現的。
new/delete的兩種分配方式原理圖如下:

注意,針對上圖最末尾所述的“new[]/delete[]時會多開闢4位元組用於儲存物件個數”,作如下說明:
①對於內建型別:
new []不會在首地址前4個位元組定義陣列長度。
delete 和 delete[]是一樣的執行效果,都會刪除整個陣列,要刪除的長度從new時即可知道。
②對於自定義型別:
new []會在首地址前4個位元組定義陣列長度。
當delete[]時,會根據前4個位元組所定義的長度來執行解構函式刪除整個陣列。
如果只是delete陣列首地址,只會刪除第一個物件的值。
19、overload、override、overwrite的介紹
答:(1)overload(過載),即函式過載:
①在同一個類中;
②函式名字相同;
③函式引數不同(型別不同、數量不同,兩者滿足其一即可);
④不以返回值型別不同作為函式過載的條件。
(2)override(覆蓋,子類改寫父類的虛擬函式),用於實現C++中多型:
①分別位於父類和子類中;
②子類改寫父類中的virtual方法;
③與父類中的函式原型相同。
(3)overwrite(重寫或叫隱藏,子類改寫父類的非虛擬函式,從而遮蔽父類函式):
①與overload類似,但是範圍不同,是子類改寫父類;
②與override類似,但是父類中的方法不是虛擬函式。
20、小端/大端機器
答:小端/大端的區別是指低位資料儲存在記憶體低位還是高位的區別。其中小端機器指:資料低位儲存在記憶體地址低位,高位資料則在記憶體地址高位;大端機器正好相反。
當前絕大部分機器都是小端機器,就是比較符合人們邏輯思維的資料儲存方式,比如intel的機器基本就都是小端機器。
21、守護程序
答:(1)什麼是守護程序?
守護程序(Daemon Process),也就是通常說的 Daemon 程序(精靈程序),是 Linux 中的後臺服務程序。它是一個生存期較長的程序,通常獨立於
控制終端並且週期性地執行某種任務或等待處理某些發生的事件。
守護程序是個特殊的孤兒程序,這種程序脫離終端,為什麼要脫離終端呢?之所以脫離於終端是為了避免程序被任何終端所產生的資訊所打斷,其在執
行過程中的資訊也不在任何終端上顯示。
(2)如何檢視守護程序?
在終端敲:ps axj

從上圖可以看出守護進行的一些特點:
守護程序基本上都是以超級使用者啟動( UID 為 0 )
沒有控制終端( TTY 為 ?)
終端程序組 ID 為 -1 ( TPGID 表示終端程序組 ID)
22、多執行緒
答:Java提供了3中多執行緒實現:Thread類、runable介面、使用ExecutorService、Callable、Future實現有返回結果的多執行緒。
Linux寫的C++多執行緒可以用標頭檔案pthread.h,常用到其中兩個函式pthread_create和pthread_join。下面是一個Linux下的簡單C++多執行緒程式:
[cpp] view plain copy print?- //Threads.cpp
- #include <iostream>
- #include <unistd.h>
- #include <pthread.h>
- usingnamespace std;
- void *thread(void *ptr)
- {
- for(int i = 0;i < 3;i++) {
- sleep(1);
- cout << ”This is a pthread.” << endl;
- }
- return 0;
- }
- int main() {
- pthread_t id;
- int ret = pthread_create(&id, NULL, thread, NULL);//建立執行緒
- if(ret) {
- cout << ”Create pthread error!” << endl;
- return 1;
- }
- for(int i = 0;i < 3;i++) {
- cout << ”This is the main process.” << endl;
- sleep(1);
- }
- pthread_join(id, NULL);//等待執行緒結束
- return 0;
- }
//Threads.cpp
多執行緒的主要優點包括:
(1)多執行緒技術使程式的響應速度更快 ,因為使用者介面可以在進行其它工作的同時一直處於活動狀態;
(2)佔用大量處理時間的任務使用多執行緒可以提高CPU利用率,即佔用大量處理時間的任務可以定期將處理器時間讓給其它任務;
(3)多執行緒可以分別設定優先順序以優化效能。
以下是最適合採用多執行緒處理:
(1)耗時或大量佔用處理器的任務阻塞使用者介面操作;
(2)各個任務必須等待外部資源 (如遠端檔案或 Internet連線)。
多執行緒的主要缺點包括:
(1)等候使用共享資源時造成程式的執行速度變慢。這些共享資源主要是獨佔性的資源 ,如印表機等。
(2)對執行緒進行管理要求額外的 CPU開銷,執行緒的使用會給系統帶來上下文切換的額外負擔。
(3)執行緒的死鎖。即對共享資源加鎖實現同步的過程中可能會死鎖。
(4)對公有變數的同時讀或寫,可能對造成髒讀等;
23、長連線與短連線
答:(1)就是TCP長連線和TCP短連線:
①TCP長連線:TCP長連線指建立連線後保持連線而不斷開。若一段時間內沒有資料傳輸,伺服器會發送心跳包給客戶端,判斷客戶端是否還線上,叫做TCP長連線中的keep alive。一般步驟:連線→資料傳輸→保持連線(心跳)→資料傳輸→保持連線(心跳)→……→關閉連線;
②TCP短連線:指連線建立並傳輸資料完成後,就斷開連線。一般步驟:連線→資料傳輸→關閉連線;
③使用場景:長連線適合單對單通訊且連線數不太多的情況;短連線適合連線數多且經常更換連線物件的;
(2)HTTP是什麼連線:
①在HTTP/1.0中,預設使用的是短連線。但從 HTTP/1.1起,預設使用長連線,用以保持連線特性。使用長連線的HTTP協議,會在響應頭有加入這行程式碼:
[html] view plain copy print?- Connection:keep-alive
Connection:keep-alive②http長連線並不是一直保持連線
http的長連線也不會是永久保持連線,它有一個保持時間如20s(從上一次資料傳輸完成開始計時),可以在不同的伺服器軟體(如Apache)中設定這個時間,若超過該時間限制仍然無資料通訊傳輸,伺服器就主動關閉該連線。注:實現長連線要客戶端和服務端都支援長連線。
③http連線實質:http的長連線/短連線實質上就是TCP的長/短連線。
24、二分圖應用於最佳匹配問題(遊客對房間的滿意度之和最大問題)
答:題目:有n個遊客和n個客房,每個遊客對每間房有一個滿意度,現要求做出一個入住安排,使得所有遊客的滿意度最大。
思路:用二分圖解決,遊客作為一邊的頂點,客房作為另一邊的頂點,取出所有最大匹配中滿意度之和最大的方案。
實現:涉及匈牙利演算法;
第二篇
1、class與struct的區別
答:C++中的struct對C中的struct進行了擴充,它已經不再只是一個包含不同資料型別的資料結構了,它已經獲取了太多的功能:
①struct能包含成員函式嗎? 能!
②struct能繼承嗎? 能!!
③struct能實現多型嗎? 能!!!
既然這些它都能實現,那它和class還能有什麼區別?
最本質的一個區別就是成員預設屬性和預設繼承許可權的不同:
①若不指明,struct成員的預設屬性是public的,class成員的預設屬性是private的;
②若不指明,struct成員的預設繼承許可權是public的,class成員的預設繼承許可權是private的;