Mysql索引結構的實現
什麼是索引
索引(Index)是幫助資料庫高效獲取資料的資料結構。索引是在基於資料庫表建立的,它包含一個表中某些列的值以及記錄對應的地址,並且把這些值儲存在一個數據結構中。最常見的就是使用雜湊表、B+樹作為索引。
Mysql索引的資料結構:B+Tree
一般來說,索引本身也很大,不可能全部儲存在記憶體中,因此索引往往以索引檔案的形式儲存在磁碟上。這樣的話,索引查詢過程中就要產生磁碟I/O的消耗,所以評價一個索引的優劣的重要指標就是I/O的操作次數。
由於儲存介質的特性,磁碟本身存取就比主存慢很多,再加上機械運動耗費,磁碟的存取速度往往是主存的幾百分分之一,因此為了提高效率,要儘量減少磁碟I/O。為了達到這個目的,磁碟往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個位元組,磁碟也會從這個位置開始,順序向後讀取一定長度的資料放入記憶體。這樣做的理論依據是電腦科學中著名的區域性性原理:當一個數據被用到時,其附近的資料也通常會馬上被使用。
程式執行期間所需要的資料通常比較集中。
由於磁碟順序讀取的效率很高(不需要尋道時間,只需很少的旋轉時間),因此對於具有區域性性的程式來說,預讀可以提高I/O效率。
預讀的長度一般為頁(page)的整倍數。頁是計算機管理儲存器的邏輯塊,硬體及作業系統往往將主存和磁碟儲存區分割為連續的大小相等的塊,每個儲存塊稱為一頁(在許多作業系統中,頁的大小通常為4k),主存和磁碟以頁為單位交換資料。當程式要讀取的資料不在主存中時,會觸發一個缺頁異常,此時系統會向磁碟發出讀盤訊號,磁碟會找到資料的起始位置並向後連續讀取一頁或幾頁載入記憶體中,然後異常返回,程式繼續執行。
資料庫系統巧妙利用了磁碟預讀原理,將一個節點的大小設為等於一個頁,這樣每個節點只需要一次I/O就可以完全載入。在實現B- Tree為了達到這個目的,實際中還需要使用如下技巧:
每次新建節點時,直接申請一個頁的空間,這樣就保證一個節點物理上也儲存在一個頁裡,加之計算機儲存分配都是按頁對齊的,就實現了一個node只需一次I/O。
B-Tree中一次檢索最多需要h-1次I/O(根節點常駐記憶體),漸進複雜度為O(h)=O(logmN)。一般實際應用中,m是非常大的數字,通常超過100,因此h非常小(通常不超過3)。Mysql索引的資料結構之所以選擇B+樹而不是B樹,是因為它內節點不儲存data,這樣一個節點就可以儲存更多的key。
Mysql兩個儲存引擎MyISAM和InnoDB的索引區別:
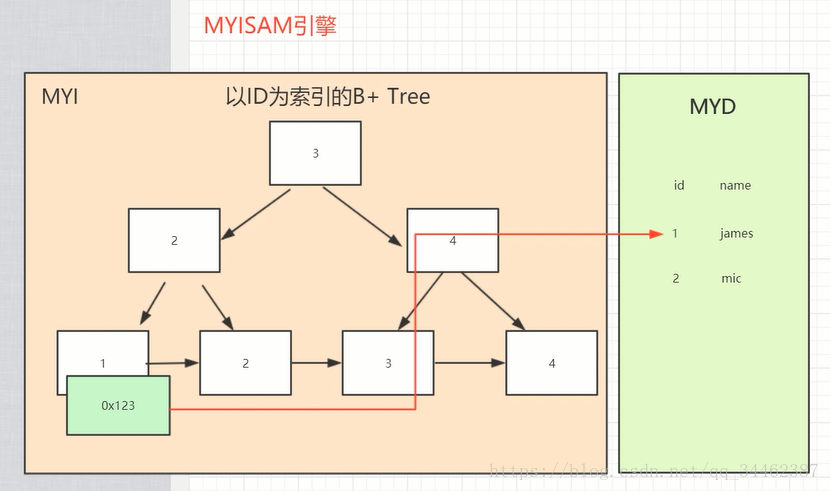
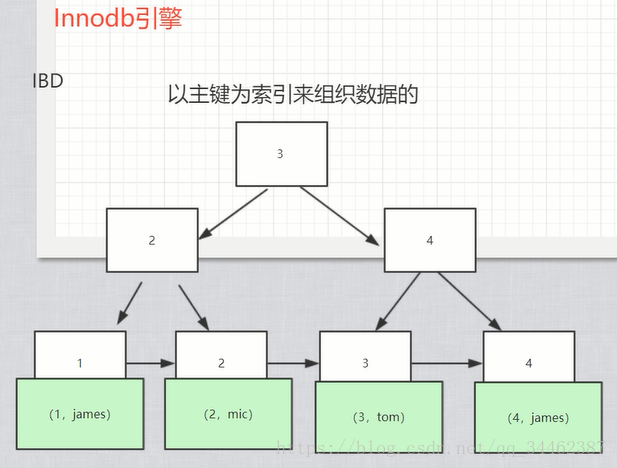
一是主索引的區別,InnoDB的資料檔案本身就是索引檔案。而MyISAM的索引和資料是分開的。
二是輔助索引的區別:InnoDB的輔助索引data域儲存相應記錄主鍵的值而不是地址。而MyISAM的輔助索引和主索引沒有多大區別。
MySQL中MyISAM與InnoDB區別及選擇
| InnoDB | MyISAM |
| 支援事務處理 | 不支援事務,回滾將造成不完全回滾,不具有原子性 |
| 支援外來鍵 | 不支援外來鍵 |
| 支援行鎖 | 支援全文搜尋 |
| 不儲存表的具體行數,掃描表來計算有多少行 | 儲存表的具體行數,不帶where時,直接返回儲存的行數 |
| DELETE 表時,是一行一行的刪除 | DELETE 表時,先drop表,然後重建表 |
| InnoDB中必須包含AUTO_INCREMENT型別欄位的索引 | MyISAM中可以使AUTO_INCREMENT型別欄位建立聯合索引 |
| 表格很難被壓縮 | 表格可以被壓縮 |
| 跨平臺可直接拷貝使用 | 跨平臺不可直接拷貝使用 |
總結:
在大資料量,高併發量的網際網路業務場景下,對於MyISAM和InnoDB
-
有where條件,count(*)兩個儲存引擎效能差不多
-
不要使用全文索引,應當使用《索引外接》的設計方案
-
事務影響效能,強一致性要求才使用事務
-
不用外來鍵,由應用程式來保證完整性
-
不命中索引,InnoDB也不能用行鎖
InnoDB是非常適合網際網路業務的儲存引擎,其多版本併發控制(Multi Version Concurrency Control, MVCC),快照讀(Snapshot Read)機制,能夠通過讀取回滾段(rollback segment)中資料的歷史版本,在事務讀取記錄的時候不用加鎖,以支援超高的併發。MyISAM相對簡單所以在效率上要優於InnoDB。如果系統讀多,寫少,對原子性要求低的情況下,MyISAM是最好的選擇。且MyISAM恢復速度快。可直接用備份覆蓋恢復。如果系統讀少,寫多的時候,尤其是併發寫入高的時候,InnoDB就是首選了。
兩種型別都有自己優缺點,選擇那個完全要看自己的實際選擇。
InnoDB 四種事務隔離級別
InnoDB預設是可重複讀的(REPEATABLE READ)
修改全域性預設的事務級別,在my.inf檔案的[mysqld]節裡類似如下設定該選項(不推薦)
transaction-isolation = {READ-UNCOMMITTED | READ-COMMITTED | REPEATABLE-READ | SERIALIZABLE}四種隔離級別說明
| 隔離級別 | 髒讀(Dirty Read) | 不可重複讀(NonRepeatable Read) | 幻讀(Phantom Read) |
|---|---|---|---|
| 未提交讀(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交讀(Read committed) | 不可能 | 可能 | 可能 |
| 可重複讀(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可序列化(SERIALIZABLE) | 不可能 | 不可能 | 不可能 |
髒讀 :一個事務讀取到另一事務未提交的更新資料
不可重複讀 : 在同一事務中,多次讀取同一資料返回的結果有所不同
幻讀 :一個事務讀到另一個事務已提交的insert資料
1.髒讀
A事務讀取B事務尚未提交的更改資料,並在這個資料的基礎上進行操作,這時候如果事務B回滾,那麼A事務讀到的資料是不被承認的。例如常見的取款事務和轉賬事務:

不可重複讀是指A事務讀取了B事務已經提交的更改資料。假如A在取款事務的過程中,B往該賬戶轉賬100,A兩次讀取的餘額發生不一致。
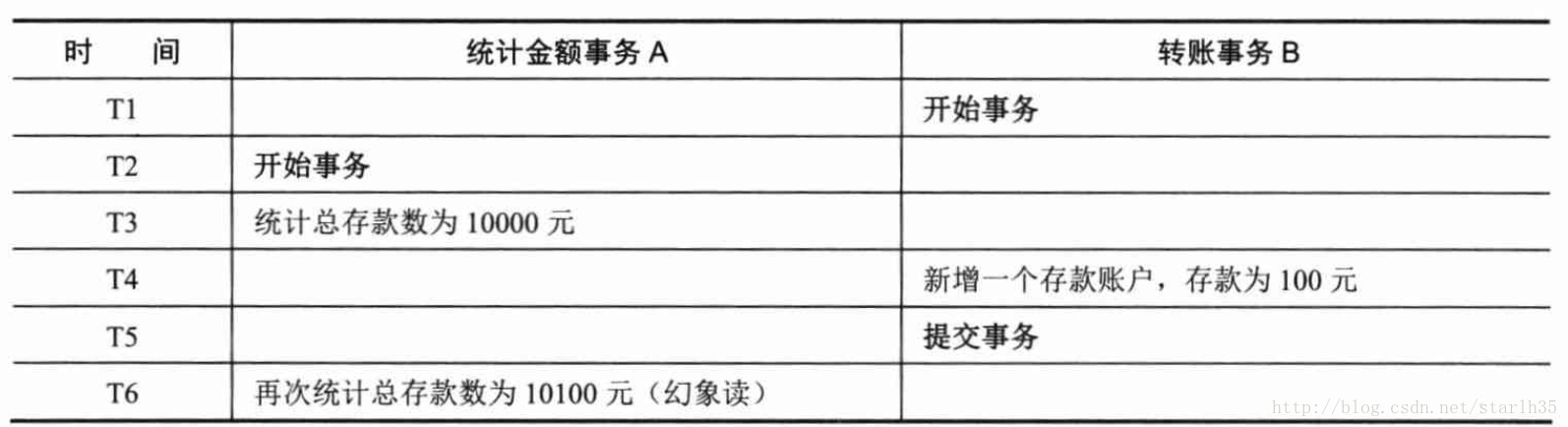
A事務讀取B事務提交的新增資料,會引發幻讀問題。幻讀一般發生在計算統計資料的事務中,例如銀行系統在同一個事務中兩次統計存款賬戶的總金額,在兩次統計中,剛好新增了一個存款賬戶,存入了100,這時候兩次統計的總金額不一致。
注意:不可重複讀和幻讀的區別是:前者是指讀到了已經提交的事務的更改資料(修改或刪除),後者是指讀到了其他已經提交事務的新增資料。對於這兩種問題解決採用不同的辦法,防止讀到更改資料,只需對操作的資料新增行級鎖,防止操作中的資料發生變化;二防止讀到新增資料,往往需要新增表級鎖,將整張表鎖定,防止新增資料(oracle採用多版本資料的方式實現)。