
資料處理神器Pandas的相關函式
阿新 • • 發佈:2018-12-31
最近參加比賽,需要處理各種各樣的資料。不得不說,pandas給我帶來了很大的方便。困於一直沒整理,每一次用到都要查官方文件。現在打算慢慢把用到的函式記錄下來,積少成多。
(1)df.value_counts():統計具體某一列相同值的個數
for example:有下面一個表,這個表有300萬行,這裡只擷取一部分舉例。我想統計item_id這一列中每一個相同id的個數

程式碼如下:
import pandas as pd df = pd.read_csv('./train.csv') df['item_id'].value_counts() Out[3]: ###以下是部分統計結果,左邊是具體的item_id,右邊是該item_id的個數 543083 9899 549608 9034 542524 8511 540198 8112 550192 7984 543092 7459 542973 7370 542907 7135
如果我想把出現個數最高的前3個item_id統計出來,並儲存為陣列,該怎麼做呢?
程式碼如下:
import numpy as np
np.array(df['item_id'].value_counts()[:3].keys())
Out[6]: array([543083, 549608, 542524], dtype=int64) ###可以看到,結果為上述統計中個數最大的前三個,符合我們的要求(2) 取dataframe的某幾列:df.ix
import pandas as pd df = pd.read_csv('./data.csv',nrows=5) #nrows表示取整個資料集的前5行 dt = df.ix[:,5:15] ##這裡取df的所有行,第5到14列
(3)將資料集的部分列相加,並新增到最後一列中:
import pandas as pd import numpy as np df = pd.read_csv('./data.csv',nrows=5) #nrows表示取整個資料集的前5行 dt = df.iloc[:,:].values ds = np.sum(dt[:,313:],axis=1) #對313列到最後列的所有列求和 ds = pd.DataFrame(ds)ds.columns = ['使用者瀏覽各網站之和'] ##新增列名 df = pd.concat([df,ds],axis=1) #將新列ds新增到原來的資料集df中
(4)查詢含有缺失值的列:df.isnull().any()
import pandas as pd
df = pd.read_csv(filename)
dt = df.isnull().any()
dic = {}
for i in range(len(dt)):
dic[dt.index[i]] = dt[i]
all_nan = []
for key,item in dic.items():
if item == True:
all_nan.append(key)
print (all_nan)(5)缺失值補全:df.fillna。(注意,fillna預設會返回新物件)
import pandas as pd
df = pd.read_csv(filename)
df = df.fillna(0) ##對所有缺失值用零補全
df = df.fillna(df.mean()) ##對每一列用平均值補全
df = df.fillna({'列名':'要補全的值',...}) ##用字典可以對不同的列填充不同的值(6)如何統計兩列元素都相同的樣本個數?
舉個栗子:我要統計100萬個使用者使用的手機品牌和手機型號都相同的個數
import pandas as pd
import numpy as np
df = pd.read_csv(filename)
#1.先建立一個全為1的列
new_col = pd.DataFrame(np.ones(len(df)))
new_col.columns = ['one']
df = pd.concat([df,new_col],axis=1)
#2.統計個數
dt = df.groupby(['手機品牌','手機型號']).one.sum()
#3.排序
d = dt.sort_values() 
PS:這只是我想到的一個方法,讀者如果有更方便的方法,煩請不吝賜教。
(7)對列的每個元素進行處理:map()函式
def crate(x,all_label):
if x == 0:
return all_label[0]
elif x > 0 and x <= 10:
return all_label[1]
elif x > 10 and x <= 20:
return all_label[2]
elif x > 20 and x <= 30:
return all_label[3]
elif x > 30 and x <= 50:
return all_label[4]
elif x > 50:
return all_label[5]
all_label = [1,2,3,4,5,6] ##all_label可以是一個隨for迴圈而變化的陣列,這裡為了簡單起見,用一個簡單陣列代替
df['新列名'] = df['列名'].map(lambda x:crate(x,all_label)) ##關鍵是這一句,lambda後面跟的x是自變數,相當於列中的元素,冒號後面是對每個元素的函式操作。(8)刪除不同的列:
df = df.drop(['a','b'],axis=1) #'a','b'為相應的列名df.drop(df.columns[8:308], axis=1,inplace=True)(9)雙重條件下的平均值
舉個栗子:我現在有三列:使用者年齡段(離散為0-8),使用者大致消費水平(離散為0-8),使用者的刷卡次數(連續值),我要統計不同年齡段不同消費水平下的平均刷卡次數,併成為新的一列加到原資料中,怎麼做呢?
其實原理和求不同年齡段的平均刷卡次數的原理相同,只是在此基礎上新增一列。
import pandas as pd
dt = pd.read_csv(filename)
dd = pd.DataFrame(dt.groupby(['年齡段','大致消費水平']).每月的大致刷卡消費次數.mean()).reset_index()
dd.columns = ['年齡段','大致消費水平', '平均刷卡次數']
dt = dt.merge(dd, on=['年齡段','大致消費水平'], how="left")其他求中位數,求和等只要把.mean()換成.median(),.sum()等相應的函式即可。
(10)對所有行或者列求和:

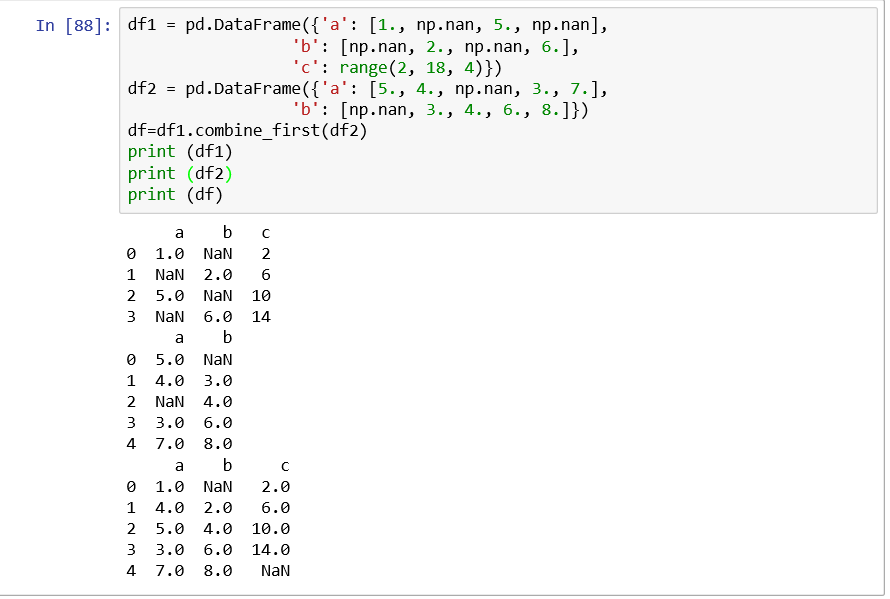 (12)pd.drop_duplicates()去除重複:
(12)pd.drop_duplicates()去除重複:df.drop_duplicates(subset=['name'], keep='first', inplace=True)