
CUDA程式效能分析-矩陣乘法
前言
矩陣乘法非常適合在GPU上並行執行,但是使用GPU並行後能獲得多大的效能提升?本文將通過一些實驗分析CUDA程式的效能。
測試環境
本文使用Dell XPS 8700作為測試機,相關配置如下:
| . | |
|---|---|
| 型號 | Dell XPS 8700 |
| CPU | Intel Core i7-4970 3.6GHz |
| 主存 | 16GB |
| GPU | GeForce GTX 750Ti |
| OS | Windows 10 64bit |
| CUDA | CUDA 8.0 |
頻寬測試
使用CUDA Toolkit提供的示例程式bandwidthTest
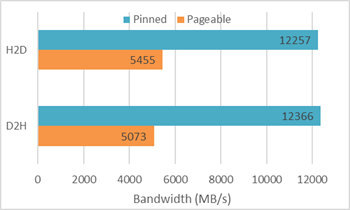
從上圖可以看出,鎖頁記憶體對頻寬的提升是非常大的,所以當一個程式的效能瓶頸是資料傳輸時,就應該考慮是否應該使用鎖頁記憶體。當然,使用鎖頁記憶體是有代價的——該記憶體空間不能換頁,當大量使用時會導致記憶體耗盡而是程式崩潰。
矩陣乘法效能對比
測試了5個不同版本的矩陣乘法的效能:numpy、C++、CUDA無優化(CUDA1)、CUDA使用共享記憶體優化(CUDA2)、cuBLAS,由於原生Python版本的程式實在太慢了,故放棄之。CUDA和cuBLAS版本的矩陣乘法可以從CUDA Toolkit提供的示例程式
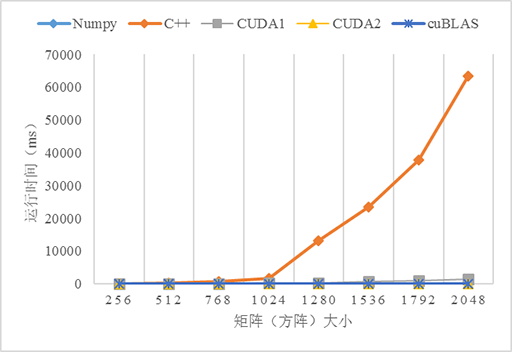
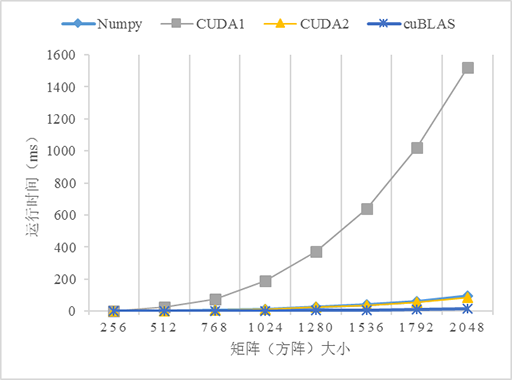
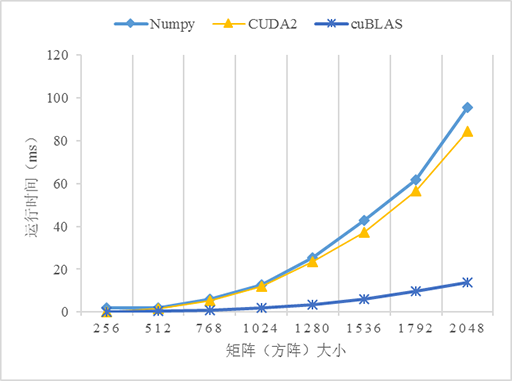
從上圖可以看到,3個GPU版本的效能都比CPU(C++)版本高,尤其是在資料量變大的時候,如當資料量大於1024*1024時,C++版本的執行時間急劇上升。對比不使用共享記憶體和使用共享記憶體優化的版本可以看到,在資料量小的時候兩個版本看不出差異,而當資料量越來越大的時,效能差異就很明顯。使用共享記憶體優化的版本明顯優於不優化的版本,這是因為從全域性記憶體訪問資料是非常慢的,而共享記憶體就相對快多了,當所有的執行緒都重複從全域性記憶體讀取資料勢必導致全域性記憶體匯流排擁堵,而且記憶體訪問也不能合併,導致大量執行緒被掛起,從而降低效能。共享記憶體是程式設計師可以控制的快取記憶體,應該可能地應用它以優化程式的效能。另外,使用cuBLAS似乎比自己實現一個演算法的效能更高,這是因為這些庫都是擁有豐富程式設計和優化經驗的高階程式設計師編寫的,所以當考慮自己實現一個演算法的時候先看看是否有現成的庫可以使用,有時候費力並不一定討好 :D。
比較戲劇性的是Numpy,它的表現完全出乎我的意料,居然戲劇性地接近了比GPU版本的效能,關於原因還有待研究。這也告訴我們,使用Python時遇到數學計算還是儘量使用Numpy而不是python的math。當然如果你的計算機配備GPU或多核CPU(貌似現代GPU都是多核的)也可以考慮Numba加速Python程式,參考使用Python寫CUDA程式。
結語
本文主要記錄了本人測試CUDA程式效能的結果,並對結果進行了分析,從測試結果和分析可以為並行程式和優化效能帶來一些啟示。