
從文字中提取圖片路徑(java 解析富文字處理 img 標籤)
阿新 • • 發佈:2018-12-31
很多專案都需要到富文字來新增內容,就好比新聞啊,旅遊景點之類的,都需要使用富文字去新增資料,然而怎麼我這邊就發現了兩個問題
怎樣將富文字的圖片的 src 獲取出來?
方法一:
利用正則表示式:
public static List<String> getImgStr(String htmlStr) { List<String> list = new ArrayList<>(); String img = ""; Pattern p_image; Matcher m_image;// String regEx_img = "<img.*src=(.*?)[^>]*?>"; //圖片連結地址 String regEx_img = "<img.*src\\s*=\\s*(.*?)[^>]*?>"; p_image = Pattern.compile(regEx_img, Pattern.CASE_INSENSITIVE); m_image = p_image.matcher(htmlStr); while (m_image.find()) { // 得到<img />資料img = m_image.group(); // 匹配<img>中的src資料 Matcher m = Pattern.compile("src\\s*=\\s*\"?(.*?)(\"|>|\\s+)").matcher(img); while (m.find()) { list.add(m.group(1)); } } return list; }
即可獲取到以下結果

方法二:
引入一個叫做 jsoup 的 jar, (下載地址:https://jsoup.org/download)
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
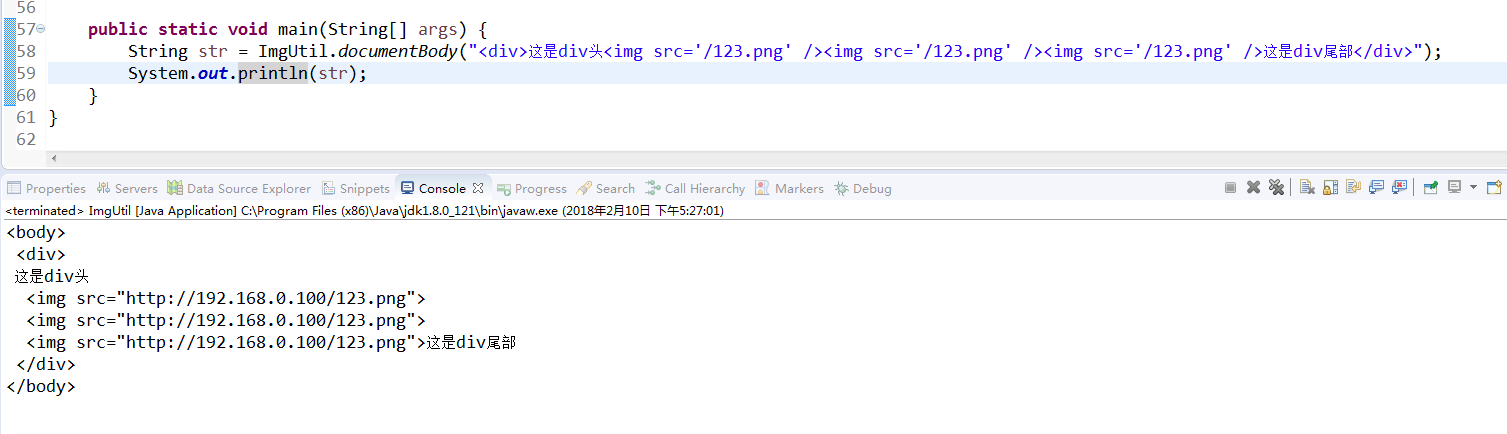
下面是工具類
public static String documentBody (String newsBody) { Element doc = Jsoup.parseBodyFragment(newsBody).body(); Elements pngs = doc.select("img[src]"); String httpHost = "http://192.168.0.100"; for (Element element : pngs) { String imgUrl = element.attr("src"); if (imgUrl.trim().startsWith("/")) { // 會去匹配我們富文字的圖片的 src 的相對路徑的首個字元,請注意一下 imgUrl =httpHost + imgUrl; element.attr("src", imgUrl); } } return newsBody = doc.toString(); }
轉載自:https://www.cnblogs.com/xjbBill/p/8439248.html