
從wordcount瞭解storm的所有基礎用法
不一樣的wordcount
workcount例子如同初學Java時的HelloWord一樣,下面通過一個workcount瞭解storm的所有基礎用法。
整個工程的結構圖如下:
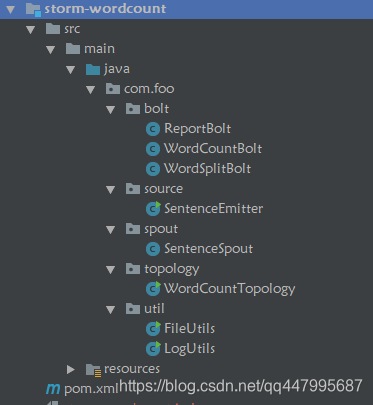
由5部分組成,其中topology,spout,bolt是wordcount的主要計算程式碼,而source是一個自定義的sentence發射器,util裡面包含了日誌解析的工具類。
1. 自定義可計數的sentence發射器
wordcount的主要作用是統計單詞的個數,我們通過一SentenceEmitter記錄發射出的單詞總個數,然後對比storm統計的單詞個數,對比二者的計數是否一致。
SentenceEmitter的程式碼如下:
/** * @author JasonLin * @version V1.0 */ public class SentenceEmitter { private AtomicLong atomicLong = new AtomicLong(0); private final AtomicLongMap<String> CONUTS = AtomicLongMap.create(); private final String[] SENTENCES = {"The logic for a realtime application is packaged into a Storm topology", " A Storm topology is analogous to a MapReduce job ", "One key difference is that a MapReduce job eventually finishes ", "whereas a topology runs forever or until you kill it of course ", "A topology is a graph of spouts and bolts that are connected with stream groupings"}; /** * 隨機發射sentence,並記錄單詞數量,該統計結果用於驗證與storm的統計結果是否相同。 * 當發射總數<1000時,停止發射,以便程式在停止時,其它bolt能將發射的資料統計完畢 * * @return */ public String emit() { if (atomicLong.incrementAndGet() >= 1000) { try { Thread.sleep(10000 * 1000); } catch (InterruptedException e) { return null; } } int randomIndex = (int) (Math.random() * SENTENCES.length); String sentence = SENTENCES[randomIndex]; for (String s : sentence.split(" ")) { CONUTS.incrementAndGet(s); } return sentence; } public void printCount() { System.out.println("--- Emitter COUNTS ---"); List<String> keys = new ArrayList<String>(); keys.addAll(CONUTS.asMap().keySet()); Collections.sort(keys); for (String key : keys) { System.out.println(key + " : " + this.CONUTS.get(key)); } System.out.println("--------------"); } public AtomicLongMap<String> getCount() { return CONUTS; } public static void main(String[] args) { SentenceEmitter sentenceEmitter = new SentenceEmitter(); for (int i = 0; i < 20; i++) { System.out.println(sentenceEmitter.emit()); } sentenceEmitter.printCount(); } }
該類定義了一個emit()方法用於隨機發射一個sentence,printCount() 用於列印emitter記錄的發射的單詞個數。
2. Spout元件
Spout元件是topology的資料來源,SentenceSpout通過SentenceEmitter的emit()方法來獲取一個隨機的sentence,然後發射出去。
/** * @author JasonLin * @version V1.0 */ public class SentenceSpout extends BaseRichSpout { private static final long serialVersionUID = -5335326175089829338L; private SpoutOutputCollector collector; private SentenceEmitter sentenceEmitter; @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; this.sentenceEmitter = new SentenceEmitter(); } @Override public void nextTuple() { String word = sentenceEmitter.emit(); collector.emit(new Values(word)); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("sentence")); } @Override public void close() { super.close(); sentenceEmitter.printCount(); } }
open()方法用與初始化,nextTuple() 是spout的核心方法,通過該方法向整個 tuple 樹發射資料(s實則是通過SpoutOutputCollector的emit(List tuple)方法發射資料)。declareOutputFields()方法宣告此拓撲的所有流的輸出模式,這裡將發射出的單詞宣告為"sentence"。close()方法在spout關閉的時候做一些清理工作,這裡將列印sentenceEmitter最終發射的單詞計數。
3. WordSplitBolt單詞分隔bolt
WordSplitBolt接收SentenceSpout發射出的sentence,然後通過空格符進行分隔單詞,然後繼續向後發射分隔的單詞。
/**
* @author JasonLin
* @version V1.0
*/
public class WordSplitBolt extends BaseRichBolt {
private static final long serialVersionUID = 2932049413480818649L;
private static final Logger LOGGER = Logger.getLogger(WordSplitBolt.class);
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(" ");
for (String word : words) {
collector.emit(new Values(word));
}
LOGGER.info("--sentence--" + sentence);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
prepare()方法類似spout的open()方式,初始化bolt。execute()方法是bolt的核心方法,資料將在這裡進行處理,然後決定是否繼續將處理的資料向後發射。程式碼邏輯也很簡單spout發射的資料與“sentence”對應,在此bolt裡面通過input.getStringByField(“sentence”)獲取到對應的spout發射的Tuple,有點類似於key-value資料庫一樣,spout將資料儲存在某個key裡面,bolt獲取指定key的值,只不過storm裡面使用Tuple來定義key-value。
4. WordCountBolt單詞計數bolt
終於到了WordCount最核心的程式碼了,WordCountBolt將WordSplitBolt 發射的tuple進行統計其中word出現的次數。
/**
* @author JasonLin
* @version V1.0
*/
public class WordCountBolt extends BaseRichBolt {
private static final long serialVersionUID = -7753338296650445257L;
private static final Logger LOGGER = Logger.getLogger(WordCountBolt.class);
private OutputCollector collector;
private HashMap<String, Long> counts = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.counts = new HashMap<String, Long>();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = this.counts.get(word);
if (count == null) {
count = 0L;
}
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
LOGGER.info("--word--" + word);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
程式碼也非常簡單,通過counts快取該bolt接收到的word,然後累加出現的次數。declarer.declare(new Fields(“word”, “count”))最後將word和計數發射到下游bolt。
5. ReportBolt 輸出最終的計算結果
ReportBolt通過map將WordCountBolt計算的最後的結果進行統一。在WordCountBolt中會多次傳送一個word的計數結果,每次發射的結果是上次的結果+1,所以ReportBolt 通過map保留最後的計數結果。
public class ReportBolt extends BaseRichBolt {
private static final Logger LOGGER = Logger.getLogger(ReportBolt.class);
private static final long serialVersionUID = -3973016696731250995L;
private HashMap<String, Long> counts = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
counts = new HashMap<>();
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = input.getLongByField("count");
this.counts.put(word, count);
LOGGER.info("--globalreport--" + word);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
System.out.println("--- FINAL COUNTS ---");
List<String> keys = new ArrayList<String>();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for (String key : keys) {
System.out.println(key + " : " + this.counts.get(key));
}
System.out.println("--------------");
}
}
由於沒有後續的bolt了,所以declareOutputFields方法不在做任何操作。同樣cleanup()方法用於在關閉該bolt時做一些後續操作,此處是列印該最終的統計結果。
6.WordCountTopology提交本地Topology
終於到了最後的操作,提交一個Topology
public class WordCountTopology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws Exception {
SentenceSpout spout = new SentenceSpout();
WordSplitBolt splitBolt = new WordSplitBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID, spout);
//將生成的sentence隨機分組,然後發射出去
builder.setBolt(SPLIT_BOLT_ID, splitBolt,3) .shuffleGrouping(SENTENCE_SPOUT_ID);
//splitBolt按照空格後分隔sentence為word,然後發射給countBolt
builder.setBolt(COUNT_BOLT_ID, countBolt, 3).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word")).setNumTasks(6);
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
Config config = new Config();
config.setNumWorkers(1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
Thread.sleep(15*1000);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}
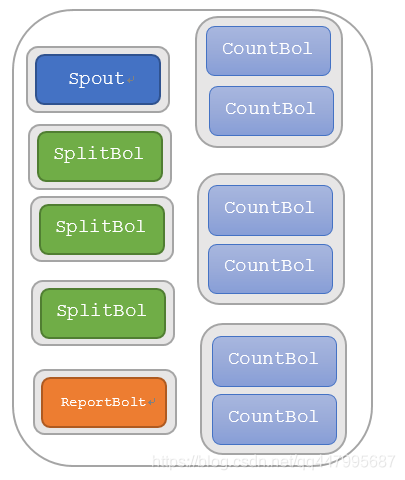
在Topology中通過TopologyBuilder來建立一個Topology,然後通過LocalCluster來提交一個本地Topology。在上面的程式碼中我們設定了spout並行度為1,splitBolt的並行度為3,即3個executor;countBolt的並行度為3,reportBolt的並行度為1;work為1。因此,這個拓撲的總並行度就是 1+3 + 3 + 1 = 8。此topology的並行圖如下:
7. 本地執行
本地執行後,檢視日誌,topology輸出的統計結果為:
--- FINAL COUNTS ---
: 203
A : 412
MapReduce : 393
One : 190
Storm : 400
The : 197
a : 1196
analogous : 203
and : 209
application : 197
are : 209
bolts : 209
connected : 209
course : 200
difference : 190
eventually : 190
finishes : 190
for : 197
forever : 200
graph : 209
groupings : 209
into : 197
is : 799
it : 200
job : 393
key : 190
kill : 200
logic : 197
of : 409
or : 200
packaged : 197
realtime : 197
runs : 200
spouts : 209
stream : 209
that : 399
to : 203
topology : 809
until : 200
whereas : 200
with : 209
you : 200
--------------
emitter統計的結果為:
--- Emitter COUNTS ---
: 203
A : 412
MapReduce : 393
One : 190
Storm : 400
The : 197
a : 1196
analogous : 203
and : 209
application : 197
are : 209
bolts : 209
connected : 209
course : 200
difference : 190
eventually : 190
finishes : 190
for : 197
forever : 200
graph : 209
groupings : 209
into : 197
is : 799
it : 200
job : 393
key : 190
kill : 200
logic : 197
of : 409
or : 200
packaged : 197
realtime : 197
runs : 200
spouts : 209
stream : 209
that : 399
to : 203
topology : 809
until : 200
whereas : 200
with : 209
you : 200
--------------
兩者統計結果一致,說明我們的wordcount計算結果完全正確。
8.storm分組再理解
storm共有八種分組,具體的可以看這裡資料流分組,我們繼續分析wordcount的資料時怎麼分組的,wordcount將storm的常用的分組都包含在內了。
builder.setBolt(SPLIT_BOLT_ID, splitBolt,3) .shuffleGrouping(SENTENCE_SPOUT_ID);
在這裡我們設定splitBolt的分組為shuffleGrouping,即隨機分組,表示spout發射的tuple將隨機的發射給所有的splitBolt。
builder.setBolt(COUNT_BOLT_ID, countBolt, 3).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word")).setNumTasks(6);
然後splitBolt將發射的資料按照fieldsGrouping分組的方式發射給countBolt,簡單的說就是相同的單詞會被髮射到同一個countBolt,這樣一個單詞的最終計數才是正確的。
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
最後globalGrouping表示會將上游countBolt的資料全部彙總到reportBolt。
在上面的程式碼中我們在每個bolt元件裡面都輸出了當前執行緒所處理的資料,接下來我們通過uilt裡面的工具類分析執行日誌,幫助加深理解這幾個分鐘方式。
log解析的程式碼如下
**
* @author JasonLin
* @version V1.0
*/
public class LogUtils {
public static void sysoWordByWhatThread(String fileName, String prefix, String splitPointStr) throws IOException {
List<String> strings = FileUtils.readFromFileToList(fileName);
List<String> need = Lists.newArrayList();
for (String s : strings) {
if (!s.contains(prefix)) {
continue;
}
need.add(s);
}
HashMultimap<String, String> result = HashMultimap.create();
for (String n : need) {
String[] strs = n.split(splitPointStr);
if (strs.length > 1) {
result.put(strs[0], strs[1]);
} else {
result.put(strs[0], "");
}
}
for (String key : result.keySet()) {
System.out.println(key + " : " + result.get(key));
}
}
public static void main(String[] args) throws IOException {
sysoWordByWhatThread("C:\\Users\\LinYu\\Desktop\\new 1.txt", "--word--", "--word--");
sysoWordByWhatThread("C:\\Users\\LinYu\\Desktop\\new 1.txt", "--sentence--", "--sentence--");
}
}
在WordSplitBolt中列印了當前執行緒名稱,處理的sentence和"–sentence–“關鍵字;WordCountBolt中列印了當前執行緒名稱,處理的word和”–word–"關鍵字,日誌工具將統計每個執行緒處理了哪些word和sentence。
日誌的解析結果如下:
[Thread-24-count-bolt-executor[6 7]] : [realtime, or, topology, for, is, eventually, MapReduce, into, of, spouts, until, logic, whereas, job]
[Thread-34-count-bolt-executor[4 5]] : [a, bolts, One, kill, graph, The, that, application, groupings, and, difference, finishes, forever, you, analogous]
[Thread-22-count-bolt-executor[2 3]] : [, A, Storm, it, connected, with, are, stream, course, to, runs, key, packaged]
[Thread-30-split-bolt-executor[11 11]] : [A topology is a graph of spouts and bolts that are connected with stream groupings, whereas a topology runs forever or until you kill it of course , The logic for a realtime application is packaged into a Storm topology, A Storm topology is analogous to a MapReduce job , One key difference is that a MapReduce job eventually finishes ]
[Thread-20-split-bolt-executor[12 12]] : [A topology is a graph of spouts and bolts that are connected with stream groupings, whereas a topology runs forever or until you kill it of course , The logic for a realtime application is packaged into a Storm topology, A Storm topology is analogous to a MapReduce job , One key difference is that a MapReduce job eventually finishes ]
[Thread-36-split-bolt-executor[10 10]] : [whereas a topology runs forever or until you kill it of course , A topology is a graph of spouts and bolts that are connected with stream groupings, The logic for a realtime application is packaged into a Storm topology, A Storm topology is analogous to a MapReduce job , One key difference is that a MapReduce job eventually finishes ]
[Thread-18-report-bolt-executor[8 8]] : [, A, Storm, One, for, eventually, MapReduce, The, that, into, are, stream, and, of, spouts, finishes, course, whereas, you, key, analogous, packaged, a, realtime, or, topology, bolts, is, it, kill, graph, connected, with, application, groupings, difference, until, logic, to, job, forever, runs]
我們看到c總共有6個執行緒,即6個executor,其中3個count-bolt-executor,3個split-bolt-executor,也驗證了前面的並行度設定,和task的數量並不參與的並行度計算!
接著看我們給splitBolt設定的分組為shuffleGrouping,隨機分組是將所有的tuple隨機發送,該日誌統計結果也表明這幾個sentence處於不同的split-bolt-executor執行緒,同時多次執行會發現每個執行緒的sentence會有所不同。
再看WordCountBolt的分組為fieldsGrouping,fieldsGrouping表示相同的Fields會被分配到同一個任務中,從日誌中發現3個count-bolt-executor裡面的單詞全部都沒有重複也驗證了這一點。
report-bolt-executor由於是globalGrouping,所以只有一個執行緒,並且包含之前所有發射出來的word,即使將builder.setBolt(REPORT_BOLT_ID, reportBolt,2).globalGrouping(COUNT_BOLT_ID);的併發度設定為2,其最終還是隻有一個執行緒在執行。所以對於globalGrouping調高併發度沒有任何意義。
**finally:**完整的程式碼在:https://github.com/Json-Lin/storm-practice.git
ps:
- 在執行的時候如果檢視FINAL COUNTS和Emitter COUNTS日誌,建議先把其它的元件日誌註釋,因為FINAL COUNTS和Emitter COUNTS日誌是控制檯輸出,如果日誌過多,控制檯會展示不完全。
- LOGGER日誌的目錄在工程同級目錄log資料夾下,可以在logback.xml裡面設定日誌路徑
<!-- 日誌檔案路徑 -->
<fileNamePattern>../logs/${log.context.name}-%d{yyyy-MM-dd}.%i.log</fileNamePattern>