
Docker學習總結(29)——Docker核心技術與實現原理
提到虛擬化技術,我們首先想到的一定是 Docker,經過四年的快速發展 Docker 已經成為了很多公司的標配,也不再是一個只能在開發階段使用的玩具了。作為在生產環境中廣泛應用的產品,Docker 有著非常成熟的社群以及大量的使用者,程式碼庫中的內容也變得非常龐大。
![]()
同樣,由於專案的發展、功能的拆分以及各種奇怪的改名 PR,讓我們再次理解 Docker 的的整體架構變得更加困難。
雖然 Docker 目前的元件較多,並且實現也非常複雜,但是本文不想過多的介紹 Docker 具體的實現細節,我們更想談一談 Docker 這種虛擬化技術的出現有哪些核心技術的支撐。

首先,Docker 的出現一定是因為目前的後端在開發和運維階段確實需要一種虛擬化技術解決開發環境和生產環境環境一致的問題,通過 Docker 我們可以將程式執行的環境也納入到版本控制中,排除因為環境造成不同執行結果的可能。但是上述需求雖然推動了虛擬化技術的產生,但是如果沒有合適的底層技術支撐,那麼我們仍然得不到一個完美的產品。本文剩下的內容會介紹幾種 Docker 使用的核心技術,如果我們瞭解它們的使用方法和原理,就能清楚 Docker 的實現原理。
Namespaces
名稱空間 (namespaces) 是 Linux 為我們提供的用於分離程序樹、網路介面、掛載點以及程序間通訊等資源的方法。在日常使用 Linux 或者 macOS 時,我們並沒有執行多個完全分離的伺服器的需要,但是如果我們在伺服器上啟動了多個服務,這些服務其實會相互影響的,每一個服務都能看到其他服務的程序,也可以訪問宿主機器上的任意檔案,這是很多時候我們都不願意看到的,我們更希望執行在同一臺機器上的不同服務能做到完全隔離,就像執行在多臺不同的機器上一樣。
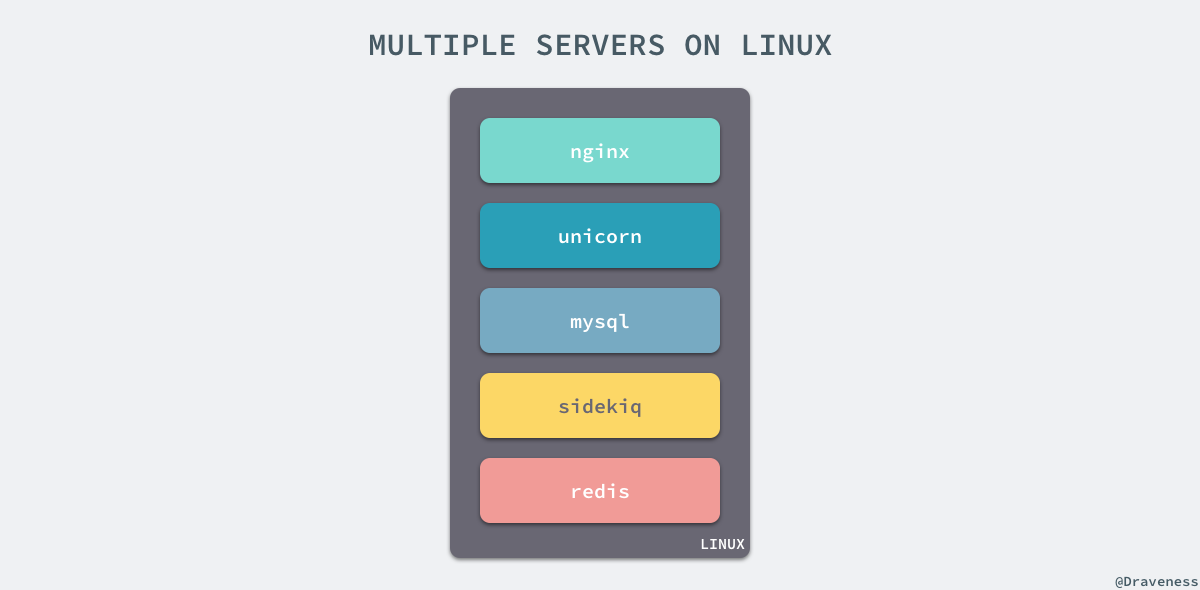
在這種情況下,一旦伺服器上的某一個服務被入侵,那麼入侵者就能夠訪問當前機器上的所有服務和檔案,這也是我們不想看到的,而 Docker 其實就通過 Linux 的 Namespaces 對不同的容器實現了隔離。
Linux 的名稱空間機制提供了以下七種不同的名稱空間,包括 CLONE_NEWCGROUP、CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS,通過這七個選項我們能在建立新的程序時設定新程序應該在哪些資源上與宿主機器進行隔離。
程序
程序是 Linux 以及現在作業系統中非常重要的概念,它表示一個正在執行的程式,也是在現代分時系統中的一個任務單元。在每一個 *nix 的作業系統上,我們都能夠通過 ps 命令打印出當前作業系統中正在執行的程序,比如在 Ubuntu 上,使用該命令就能得到以下的結果:
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Apr08 ? 00:00:09 /sbin/init
root 2 0 0 Apr08 ? 00:00:00 [kthreadd]
root 3 2 0 Apr08 ? 00:00:05 [ksoftirqd/0]
root 5 2 0 Apr08 ? 00:00:00 [kworker/0:0H]
root 7 2 0 Apr08 ? 00:07:10 [rcu_sched]
root 39 2 0 Apr08 ? 00:00:00 [migration/0]
root 40 2 0 Apr08 ? 00:01:54 [watchdog/0]
...
當前機器上有很多的程序正在執行,在上述程序中有兩個非常特殊,一個是 pid 為 1 的 /sbin/init 程序,另一個是 pid 為 2 的 kthreadd 程序,這兩個程序都是被 Linux 中的上帝程序 idle 創建出來的,其中前者負責執行核心的一部分初始化工作和系統配置,也會建立一些類似 getty 的註冊程序,而後者負責管理和排程其他的核心程序。
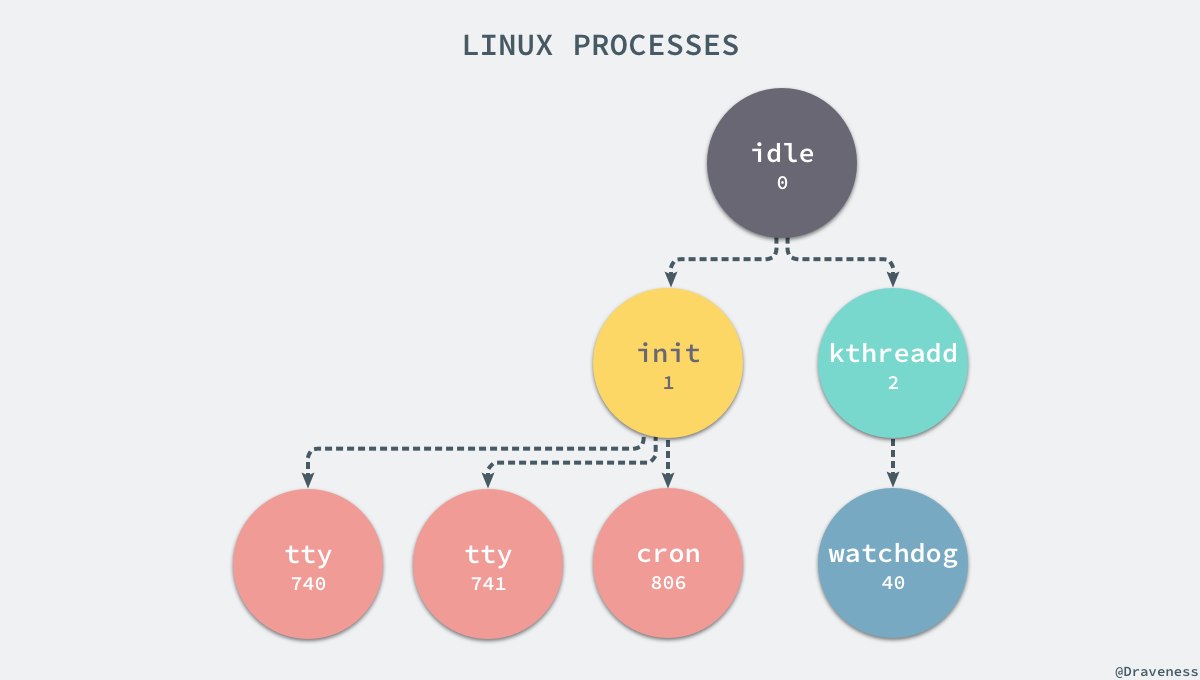
如果我們在當前的 Linux 作業系統下執行一個新的 Docker 容器,並通過 exec 進入其內部的 bash 並列印其中的全部程序,我們會得到以下的結果:
[email protected]:~# docker run -it -d ubuntu
b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79
[email protected]:~# docker exec -it b809a2eb3630 /bin/bash
[email protected]:/# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 15:42 pts/0 00:00:00 /bin/bash
root 9 0 0 15:42 pts/1 00:00:00 /bin/bash
root 17 9 0 15:43 pts/1 00:00:00 ps -ef
在新的容器內部執行 ps 命令打印出了非常乾淨的程序列表,只有包含當前 ps -ef 在內的三個程序,在宿主機器上的幾十個程序都已經消失不見了。
當前的 Docker 容器成功將容器內的程序與宿主機器中的程序隔離,如果我們在宿主機器上列印當前的全部程序時,會得到下面三條與 Docker 相關的結果:
UID PID PPID C STIME TTY TIME CMD
root 29407 1 0 Nov16 ? 00:08:38 /usr/bin/dockerd --raw-logs
root 1554 29407 0 Nov19 ? 00:03:28 docker-containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runc
root 5006 1554 0 08:38 ? 00:00:00 docker-containerd-shim b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 /var/run/docker/libcontainerd/b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 docker-runc
在當前的宿主機器上,可能就存在由上述的不同程序構成的程序樹:
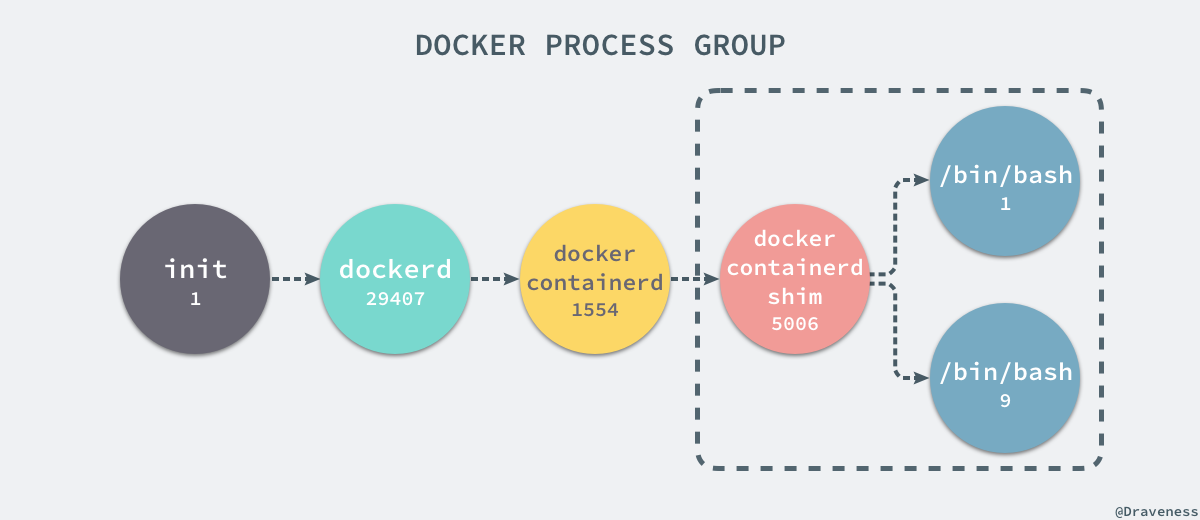
這就是在使用 clone(2) 建立新程序時傳入 CLONE_NEWPID 實現的,也就是使用 Linux 的名稱空間實現程序的隔離,Docker 容器內部的任意程序都對宿主機器的程序一無所知。
containerRouter.postContainersStart
└── daemon.ContainerStart
└── daemon.createSpec
└── setNamespaces
└── setNamespace
Docker 的容器就是使用上述技術實現與宿主機器的程序隔離,當我們每次執行 docker run 或者 docker start時,都會在下面的方法中建立一個用於設定程序間隔離的 Spec:
func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) {
s := oci.DefaultSpec()
// ...
if err := setNamespaces(daemon, &s, c); err != nil {
return nil, fmt.Errorf("linux spec namespaces: %v", err)
}
return &s, nil
}
在 setNamespaces 方法中不僅會設定程序相關的名稱空間,還會設定與使用者、網路、IPC 以及 UTS 相關的名稱空間:
func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error {
// user
// network
// ipc
// uts
// pid
if c.HostConfig.PidMode.IsContainer() {
ns := specs.LinuxNamespace{Type: "pid"}
pc, err := daemon.getPidContainer(c)
if err != nil {
return err
}
ns.Path = fmt.Sprintf("/proc/%d/ns/pid", pc.State.GetPID())
setNamespace(s, ns)
} else if c.HostConfig.PidMode.IsHost() {
oci.RemoveNamespace(s, specs.LinuxNamespaceType("pid"))
} else {
ns := specs.LinuxNamespace{Type: "pid"}
setNamespace(s, ns)
}
return nil
}
所有名稱空間相關的設定 Spec 最後都會作為 Create 函式的入參在建立新的容器時進行設定:
daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)
所有與名稱空間的相關的設定都是在上述的兩個函式中完成的,Docker 通過名稱空間成功完成了與宿主機程序和網路的隔離。
網路
如果 Docker 的容器通過 Linux 的名稱空間完成了與宿主機程序的網路隔離,但是卻有沒有辦法通過宿主機的網路與整個網際網路相連,就會產生很多限制,所以 Docker 雖然可以通過名稱空間建立一個隔離的網路環境,但是 Docker 中的服務仍然需要與外界相連才能發揮作用。
每一個使用 docker run 啟動的容器其實都具有單獨的網路名稱空間,Docker 為我們提供了四種不同的網路模式,Host、Container、None 和 Bridge 模式。
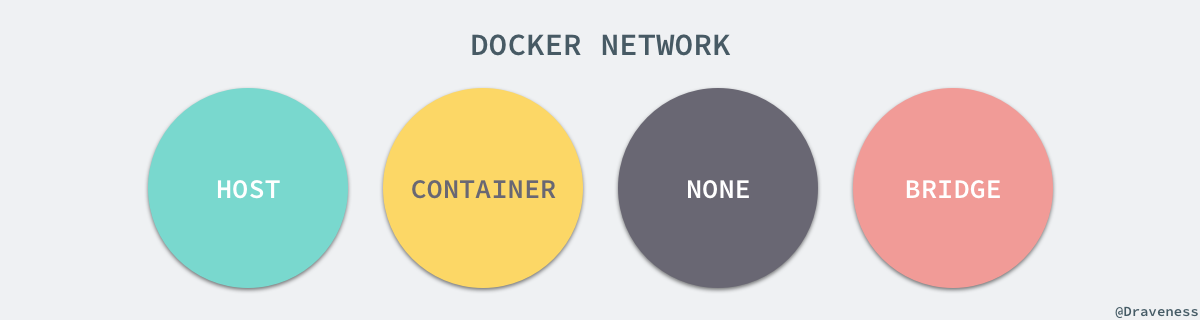
在這一部分,我們將介紹 Docker 預設的網路設定模式:網橋模式。在這種模式下,除了分配隔離的網路名稱空間之外,Docker 還會為所有的容器設定 IP 地址。當 Docker 伺服器在主機上啟動之後會建立新的虛擬網橋 docker0,隨後在該主機上啟動的全部服務在預設情況下都與該網橋相連。
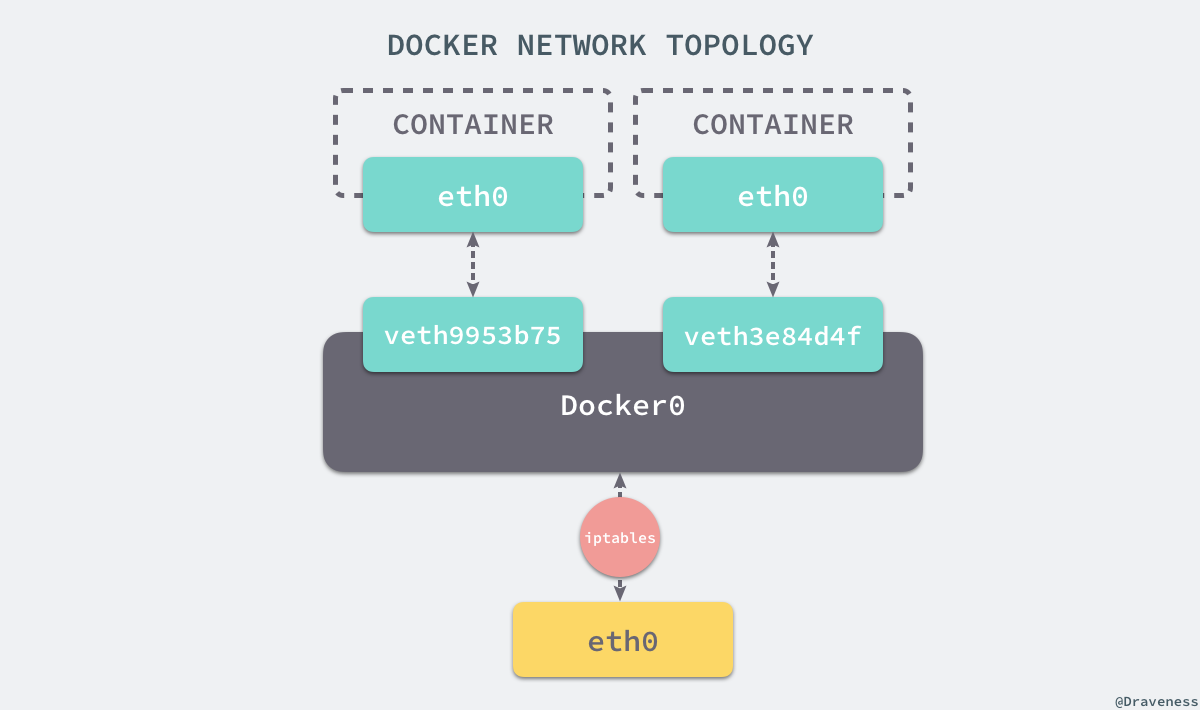
在預設情況下,每一個容器在建立時都會建立一對虛擬網絡卡,兩個虛擬網絡卡組成了資料的通道,其中一個會放在建立的容器中,會加入到名為 docker0 網橋中。我們可以使用如下的命令來檢視當前網橋的介面:
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242a6654980 no veth3e84d4f
veth9953b75
docker0 會為每一個容器分配一個新的 IP 地址並將 docker0 的 IP 地址設定為預設的閘道器。網橋 docker0 通過 iptables 中的配置與宿主機器上的網絡卡相連,所有符合條件的請求都會通過 iptables 轉發到 docker0 並由網橋分發給對應的機器。
$ iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- anywhere anywhere
我們在當前的機器上使用 docker run -d -p 6379:6379 redis 命令啟動了一個新的 Redis 容器,在這之後我們再檢視當前 iptables 的 NAT 配置就會看到在 DOCKER 的鏈中出現了一條新的規則:
DNAT tcp -- anywhere anywhere tcp dpt:6379 to:192.168.0.4:6379
上述規則會將從任意源傳送到當前機器 6379 埠的 TCP 包轉發到 192.168.0.4:6379 所在的地址上。
這個地址其實也是 Docker 為 Redis 服務分配的 IP 地址,如果我們在當前機器上直接 ping 這個 IP 地址就會發現它是可以訪問到的:
$ ping 192.168.0.4
PING 192.168.0.4 (192.168.0.4) 56(84) bytes of data.
64 bytes from 192.168.0.4: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 192.168.0.4: icmp_seq=2 ttl=64 time=0.043 ms
^C
--- 192.168.0.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.043/0.056/0.069/0.013 ms
從上述的一系列現象,我們就可以推測出 Docker 是如何將容器的內部的埠暴露出來並對資料包進行轉發的了;當有 Docker 的容器需要將服務暴露給宿主機器,就會為容器分配一個 IP 地址,同時向 iptables 中追加一條新的規則。
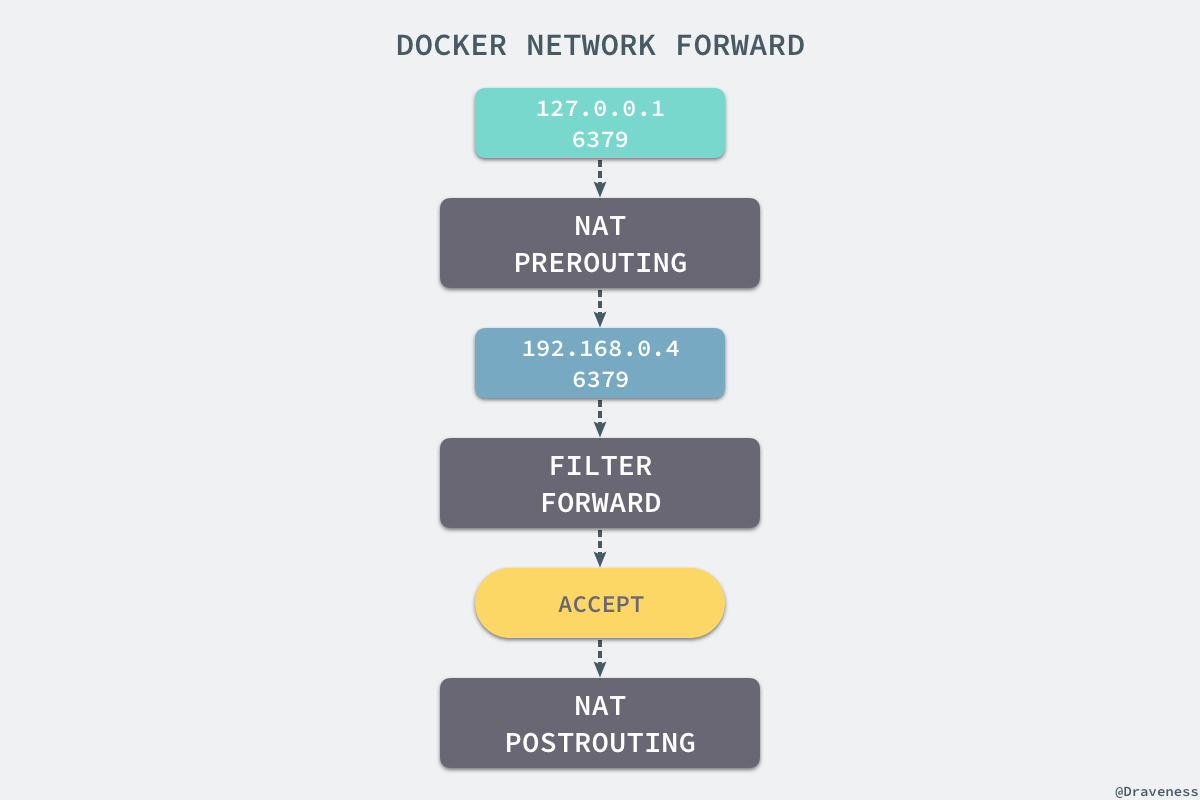
當我們使用 redis-cli 在宿主機器的命令列中訪問 127.0.0.1:6379 的地址時,經過 iptables 的 NAT PREROUTING 將 ip 地址定向到了 192.168.0.4,重定向過的資料包就可以通過 iptables 中的 FILTER 配置,最終在 NAT POSTROUTING 階段將 ip 地址偽裝成 127.0.0.1,到這裡雖然從外面看起來我們請求的是 127.0.0.1:6379,但是實際上請求的已經是 Docker 容器暴露出的埠了。
$ redis-cli -h 127.0.0.1 -p 6379 ping
PONG
Docker 通過 Linux 的名稱空間實現了網路的隔離,又通過 iptables 進行資料包轉發,讓 Docker 容器能夠優雅地為宿主機器或者其他容器提供服務。
libnetwork
整個網路部分的功能都是通過 Docker 拆分出來的 libnetwork 實現的,它提供了一個連線不同容器的實現,同時也能夠為應用給出一個能夠提供一致的程式設計介面和網路層抽象的容器網路模型。
The goal of libnetwork is to deliver a robust Container Network Model that provides a consistent programming interface and the required network abstractions for applications.
libnetwork 中最重要的概念,容器網路模型由以下的幾個主要元件組成,分別是 Sandbox、Endpoint 和 Network:
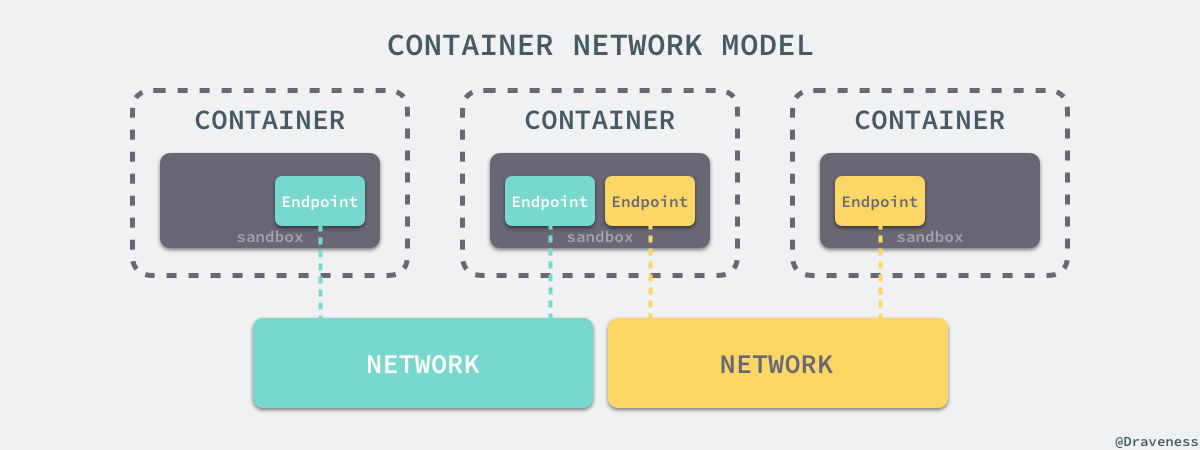
在容器網路模型中,每一個容器內部都包含一個 Sandbox,其中儲存著當前容器的網路棧配置,包括容器的介面、路由表和 DNS 設定,Linux 使用網路名稱空間實現這個 Sandbox,每一個 Sandbox 中都可能會有一個或多個 Endpoint,在 Linux 上就是一個虛擬的網絡卡 veth,Sandbox 通過 Endpoint 加入到對應的網路中,這裡的網路可能就是我們在上面提到的 Linux 網橋或者 VLAN。
想要獲得更多與 libnetwork 或者容器網路模型相關的資訊,可以閱讀 Design · libnetwork 瞭解更多資訊,當然也可以閱讀原始碼瞭解不同 OS 對容器網路模型的不同實現。
掛載點
雖然我們已經通過 Linux 的名稱空間解決了程序和網路隔離的問題,在 Docker 程序中我們已經沒有辦法訪問宿主機器上的其他程序並且限制了網路的訪問,但是 Docker 容器中的程序仍然能夠訪問或者修改宿主機器上的其他目錄,這是我們不希望看到的。
在新的程序中建立隔離的掛載點名稱空間需要在 clone 函式中傳入 CLONE_NEWNS,這樣子程序就能得到父程序掛載點的拷貝,如果不傳入這個引數子程序對檔案系統的讀寫都會同步回父程序以及整個主機的檔案系統。
如果一個容器需要啟動,那麼它一定需要提供一個根檔案系統(rootfs),容器需要使用這個檔案系統來建立一個新的程序,所有二進位制的執行都必須在這個根檔案系統中。
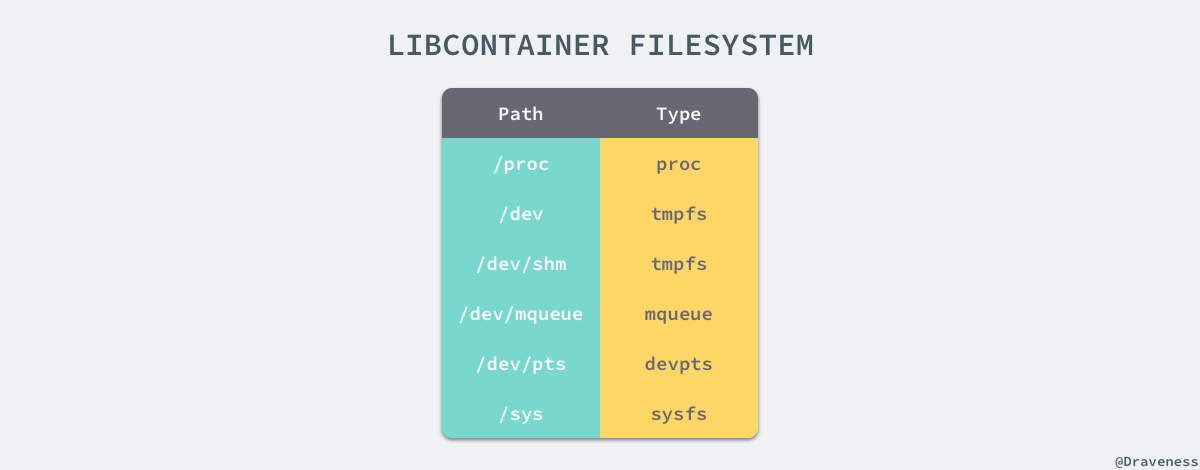
想要正常啟動一個容器就需要在 rootfs 中掛載以上的幾個特定的目錄,除了上述的幾個目錄需要掛載之外我們還需要建立一些符號連結保證系統 IO 不會出現問題。
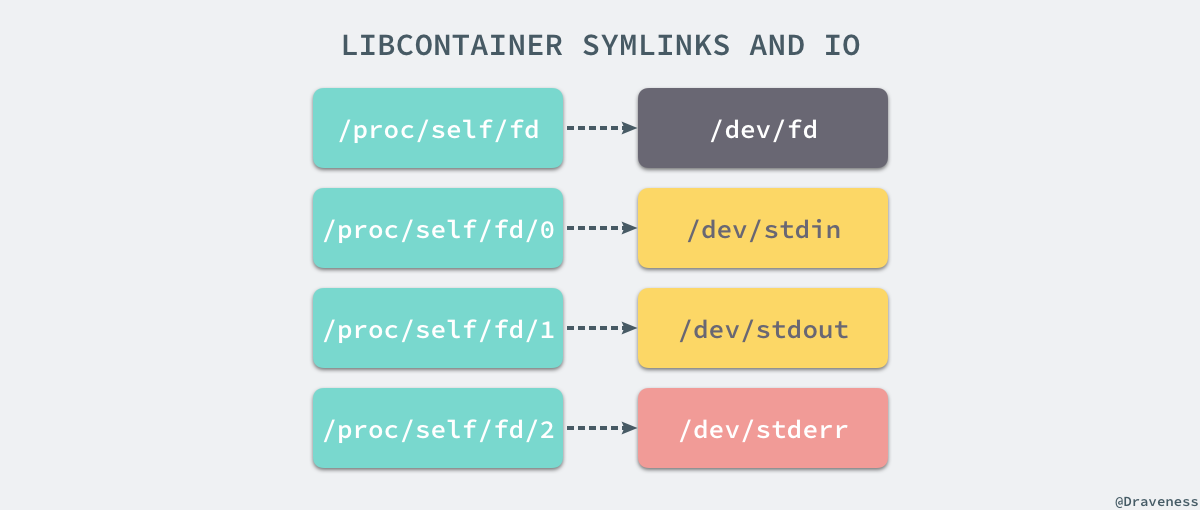
為了保證當前的容器程序沒有辦法訪問宿主機器上其他目錄,我們在這裡還需要通過 libcotainer 提供的 pivor_root 或者 chroot 函式改變程序能夠訪問個檔案目錄的根節點。
// pivor_root
put_old = mkdir(...);
pivot_root(rootfs, put_old);
chdir("/");
unmount(put_old, MS_DETACH);
rmdir(put_old);
// chroot
mount(rootfs, "/", NULL, MS_MOVE, NULL);
chroot(".");
chdir("/");
到這裡我們就將容器需要的目錄掛載到了容器中,同時也禁止當前的容器程序訪問宿主機器上的其他目錄,保證了不同檔案系統的隔離。
這一部分的內容是作者在 libcontainer 中的 SPEC.md 檔案中找到的,其中包含了 Docker 使用的檔案系統的說明,對於 Docker 是否真的使用
chroot來確保當前的程序無法訪問宿主機器的目錄,作者其實也沒有確切的答案,一是 Docker 專案的程式碼太多龐大,不知道該從何入手,作者嘗試通過 Google 查詢相關的結果,但是既找到了無人回答的 問題,也得到了與 SPEC 中的描述有衝突的 答案 ,如果各位讀者有明確的答案可以在部落格下面留言,非常感謝。
chroot
在這裡不得不簡單介紹一下 chroot(change root),在 Linux 系統中,系統預設的目錄就都是以 / 也就是根目錄開頭的,chroot 的使用能夠改變當前的系統根目錄結構,通過改變當前系統的根目錄,我們能夠限制使用者的權利,在新的根目錄下並不能夠訪問舊系統根目錄的結構個檔案,也就建立了一個與原系統完全隔離的目錄結構。
與 chroot 的相關內容部分來自 理解 chroot 一文,各位讀者可以閱讀這篇文章獲得更詳細的資訊。
CGroups
我們通過 Linux 的名稱空間為新建立的程序隔離了檔案系統、網路並與宿主機器之間的程序相互隔離,但是名稱空間並不能夠為我們提供物理資源上的隔離,比如 CPU 或者記憶體,如果在同一臺機器上運行了多個對彼此以及宿主機器一無所知的『容器』,這些容器卻共同佔用了宿主機器的物理資源。
如果其中的某一個容器正在執行 CPU 密集型的任務,那麼就會影響其他容器中任務的效能與執行效率,導致多個容器相互影響並且搶佔資源。如何對多個容器的資源使用進行限制就成了解決程序虛擬資源隔離之後的主要問題,而 Control Groups(簡稱 CGroups)就是能夠隔離宿主機器上的物理資源,例如 CPU、記憶體、磁碟 I/O 和網路頻寬。
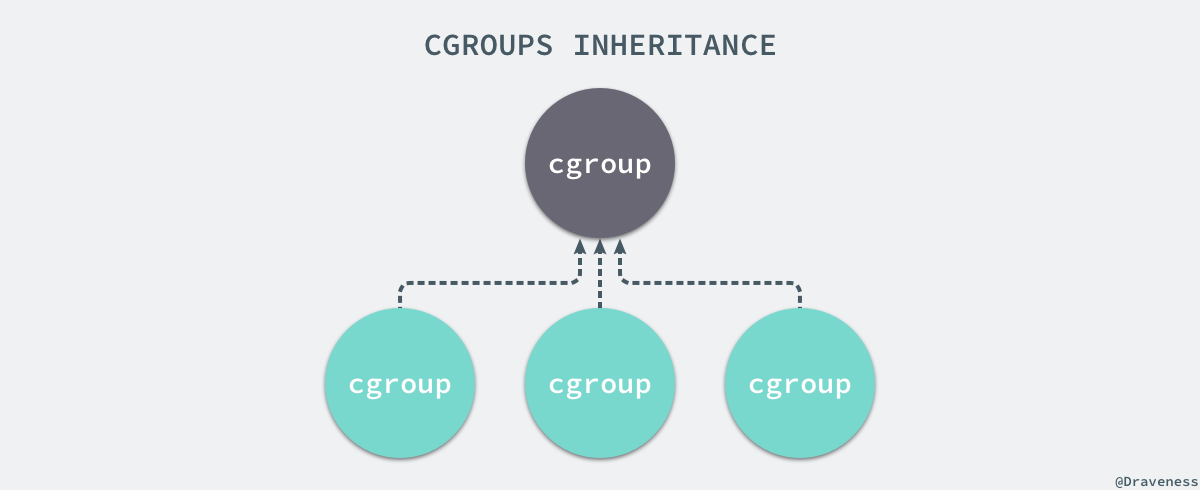
每一個 CGroup 都是一組被相同的標準和引數限制的程序,不同的 CGroup 之間是有層級關係的,也就是說它們之間可以從父類繼承一些用於限制資源使用的標準和引數。
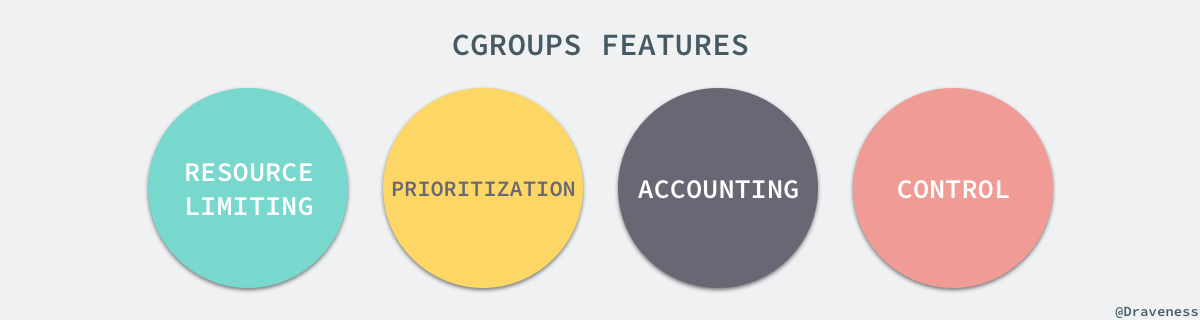
Linux 的 CGroup 能夠為一組程序分配資源,也就是我們在上面提到的 CPU、記憶體、網路頻寬等資源,通過對資源的分配,CGroup 能夠提供以下的幾種功能:
在 CGroup 中,所有的任務就是一個系統的一個程序,而 CGroup 就是一組按照某種標準劃分的程序,在 CGroup 這種機制中,所有的資源控制都是以 CGroup 作為單位實現的,每一個程序都可以隨時加入一個 CGroup 也可以隨時退出一個 CGroup。
Linux 使用檔案系統來實現 CGroup,我們可以直接使用下面的命令檢視當前的 CGroup 中有哪些子系統:
$ lssubsys -m
cpuset /sys/fs/cgroup/cpuset
cpu /sys/fs/cgroup/cpu
cpuacct /sys/fs/cgroup/cpuacct
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
blkio /sys/fs/cgroup/blkio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb
大多數 Linux 的發行版都有著非常相似的子系統,而之所以將上面的 cpuset、cpu 等東西稱作子系統,是因為它們能夠為對應的控制組分配資源並限制資源的使用。
如果我們想要建立一個新的 cgroup 只需要在想要分配或者限制資源的子系統下面建立一個新的資料夾,然後這個資料夾下就會自動出現很多的內容,如果你在 Linux 上安裝了 Docker,你就會發現所有子系統的目錄下都有一個名為 docker 的資料夾:
$ ls cpu
cgroup.clone_children
...
cpu.stat
docker
notify_on_release
release_agent
tasks
$ ls cpu/docker/
9c3057f1291b53fd54a3d12023d2644efe6a7db6ddf330436ae73ac92d401cf1
cgroup.clone_children
...
cpu.stat
notify_on_release
release_agent
tasks
9c3057xxx 其實就是我們執行的一個 Docker 容器,啟動這個容器時,Docker 會為這個容器建立一個與容器識別符號相同的 CGroup,在當前的主機上 CGroup 就會有以下的層級關係:
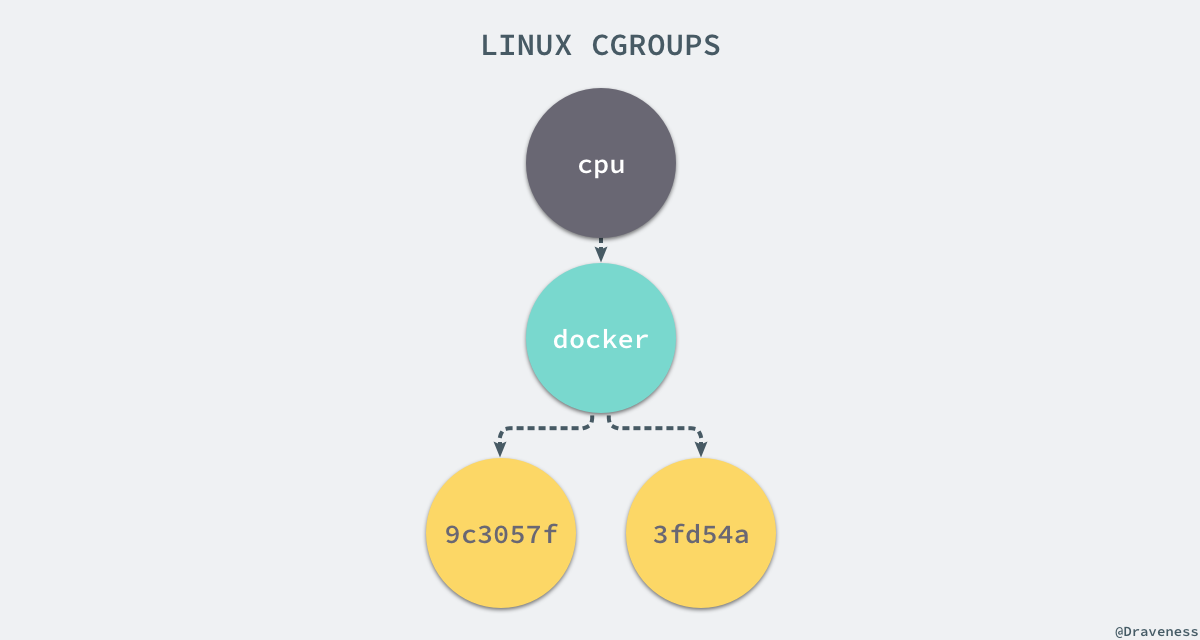
每一個 CGroup 下面都有一個 tasks 檔案,其中儲存著屬於當前控制組的所有程序的 pid,作為負責 cpu 的子系統,cpu.cfs_quota_us 檔案中的內容能夠對 CPU 的使用作出限制,如果當前檔案的內容為 50000,那麼當前控制組中的全部程序的 CPU 佔用率不能超過 50%。
如果系統管理員想要控制 Docker 某個容器的資源使用率就可以在 docker 這個父控制組下面找到對應的子控制組並且改變它們對應檔案的內容,當然我們也可以直接在程式執行時就使用引數,讓 Docker 程序去改變相應檔案中的內容。
$ docker run -it -d --cpu-quota=50000 busybox
53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274
$ cd 53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274/
$ ls
cgroup.clone_children cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat notify_on_release