
Spark原始碼分析之三:Stage劃分
Stage劃分的大體流程如下圖所示:
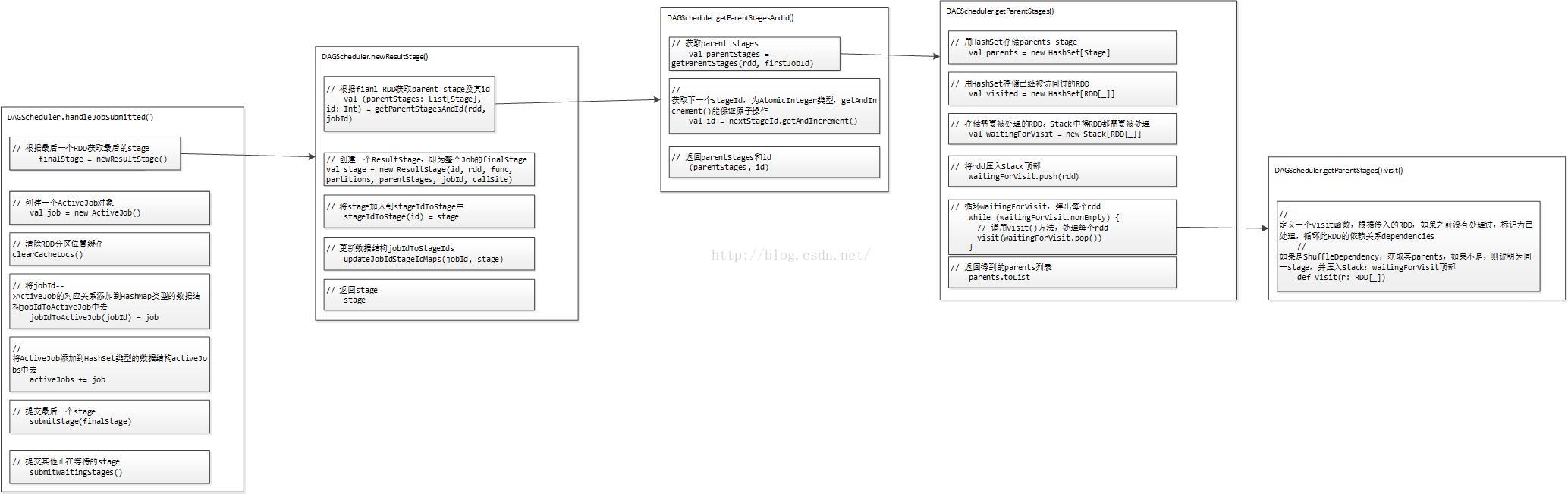
前面提到,對於JobSubmitted事件,我們通過呼叫DAGScheduler的handleJobSubmitted()方法來處理。那麼我們先來看下程式碼:
這個handleJobSubmitted()方法一共做了這麼幾件事:// 處理Job提交的函式 private[scheduler] def handleJobSubmitted(jobId: Int, finalRDD: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], callSite: CallSite, listener: JobListener, properties: Properties) { var finalStage: ResultStage = null // 利用最後一個RDD(finalRDD),建立最後的stage物件:finalStage try { // New stage creation may throw an exception if, for example, jobs are run on a // HadoopRDD whose underlying HDFS files have been deleted. // 根據最後一個RDD獲取最後的stage finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite) } catch { case e: Exception => logWarning("Creating new stage failed due to exception - job: " + jobId, e) listener.jobFailed(e) return } // 建立一個ActiveJob物件 val job = new ActiveJob(jobId, finalStage, callSite, listener, properties) // 清除RDD分割槽位置快取 // private val cacheLocs = new HashMap[Int, IndexedSeq[Seq[TaskLocation]]] clearCacheLocs() // 呼叫logInfo()方法記錄日誌資訊 logInfo("Got job %s (%s) with %d output partitions".format( job.jobId, callSite.shortForm, partitions.length)) logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")") logInfo("Parents of final stage: " + finalStage.parents) logInfo("Missing parents: " + getMissingParentStages(finalStage)) val jobSubmissionTime = clock.getTimeMillis() // 將jobId-->ActiveJob的對應關係新增到HashMap型別的資料結構jobIdToActiveJob中去 jobIdToActiveJob(jobId) = job // 將ActiveJob新增到HashSet型別的資料結構activeJobs中去 activeJobs += job finalStage.setActiveJob(job) //2 獲取stageIds列表 // jobIdToStageIds儲存的是jobId--stageIds的對應關係 // stageIds為HashSet[Int]型別的 // jobIdToStageIds在上面newResultStage過程中已被處理 val stageIds = jobIdToStageIds(jobId).toArray // stageIdToStage儲存的是stageId-->Stage的對應關係 val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo)) listenerBus.post( SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties)) // 提交最後一個stage submitStage(finalStage) // 提交其他正在等待的stage submitWaitingStages() }
第一,呼叫newResultStage()方法,生成Stage,包括最後一個Stage:ResultStage和前面的Parent Stage:ShuffleMapStage;
第二,建立一個ActiveJob物件job;
第三,清除RDD分割槽位置快取;
第四,呼叫logInfo()方法記錄日誌資訊;
第五,維護各種資料對應關係涉及到的資料結構:
(1)將jobId-->ActiveJob的對應關係新增到HashMap型別的資料結構jobIdToActiveJob中去;
(2)將ActiveJob新增到HashSet型別的資料結構activeJobs中去;
第六,提交Stage;
下面,除了提交Stage留在第三階段外,我們挨個分析第二階段的每一步。
首先是呼叫newResultStage()方法,生成Stage,包括最後一個Stage:ResultStage和前面的Parent Stage:ShuffleMapStage。程式碼如下:
首先,根據fianl RDD獲取parent stages及id,這個id為ResultStage的stageId;/** * Create a ResultStage associated with the provided jobId. * 用提供的jobId建立一個ResultStage */ private def newResultStage( rdd: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], jobId: Int, callSite: CallSite): ResultStage = { // 根據fianl RDD獲取parent stage及id,這個id為ResultStage的stageId val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId) // 建立一個ResultStage,即為整個Job的finalStage // 引數:id為stage的id,rdd為stage中最後一個rdd,func為在分割槽上執行的函式操作, // partitions為rdd中可以執行操作的分割槽,parentStages為該stage的父stages,jobId為該stage val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite) // 將stage加入到stageIdToStage中 stageIdToStage(id) = stage // 更新資料結構jobIdToStageIds updateJobIdStageIdMaps(jobId, stage) // 返回stage stage }
其次,建立一個ResultStage,即為整個Job的finalStage;
然後,將stage加入到資料結構stageIdToStage中;
接著,更新資料結構jobIdToStageIds;
最後,返回這個ResultStage。
我們一步步來看。首先呼叫getParentStagesAndId()方法,根據fianl RDD獲取parent stages及id,這個id為ResultStage的stageId。程式碼如下:
/**
* Helper function to eliminate some code re-use when creating new stages.
*/
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
// 獲取parent stages
val parentStages = getParentStages(rdd, firstJobId)
// 獲取下一個stageId,為AtomicInteger型別,getAndIncrement()能保證原子操作
val id = nextStageId.getAndIncrement()
// 返回parentStages和id
(parentStages, id)
}/**
* Get or create the list of parent stages for a given RDD. The new Stages will be created with
* the provided firstJobId.
*/
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// 用HashSet儲存parents stage
val parents = new HashSet[Stage]
// 用HashSet儲存已經被訪問過的RDD
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
// 儲存需要被處理的RDD。Stack中得RDD都需要被處理
val waitingForVisit = new Stack[RDD[_]]
// 定義一個visit函式,根據傳入的RDD,如果之前沒有處理過,標記為已處理,迴圈此RDD的依賴關係dependencies
// 如果是ShuffleDependency,獲取其parents;如果不是,則說明為同一stage,並壓入Stack:waitingForVisit頂部
def visit(r: RDD[_]) {
if (!visited(r)) {// visited中沒有的話
// 將RDD r加入到visited,表示已經處理過了
visited += r
// Kind of ugly: need to register RDDs with the cache here since
// we can't do it in its constructor because # of partitions is unknown
// 迴圈Rdd r的依賴關係
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
// 如果是ShuffleDependency,獲取其parents,新增到parents中去
parents += getShuffleMapStage(shufDep, firstJobId)
case _ =>
// 否則,屬於同一個stage,壓入Stack頂部,後續再遞迴處理
waitingForVisit.push(dep.rdd)
}
}
}
}
// 將rdd壓入Stack頂部
waitingForVisit.push(rdd)
// 迴圈waitingForVisit,彈出每個rdd
while (waitingForVisit.nonEmpty) {
// 呼叫visit()方法,處理每個rdd
visit(waitingForVisit.pop())
}
// 返回得到的parents列表
parents.toList
}getParentStages()方法在其內部定義瞭如下資料結構:
parents:用HashSet儲存parents stages,即finalRDD的所有parent stages,也就是ShuffleMapStage;
visited:用HashSet儲存已經被訪問過的RDD,在RDD被處理前先存入該HashSet,保證儲存在裡面的RDD將不會被重複處理;
waitingForVisit:儲存需要被處理的RDD。Stack中得RDD都需要被處理。
getParentStages()方法在其內部還定義了一個visit()方法,傳入一個RDD,如果之前沒有處理過,標記為已處理,並迴圈此RDD的依賴關係dependencies,如果是ShuffleDependency,呼叫getShuffleMapStage()方法獲取其parent stage;如果不是,則說明為同一stage,並壓入Stack:waitingForVisit頂部,等待後續通過visit()方法處理。所以,getParentStages()方法從finalRDD開始,逐漸往上查詢,如果是窄依賴,證明在同一個Stage中,繼續往上查詢,如果是寬依賴,通過getShuffleMapStage()方法獲取其parent stage,就能得到整個Job中所有的parent stages,也就是ShuffleMapStage。
接下來,我們看下getShuffleMapStage()方法的實現。程式碼如下:
/**
* Get or create a shuffle map stage for the given shuffle dependency's map side.
* 針對給定的shuffle dependency的map端,獲取或者建立一個ShuffleMapStage
*/
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
// 從資料結構shuffleToMapStage中根據shuffleId獲取,如果有直接返回,否則
// 獲取ShuffleDependency中的rdd,呼叫getAncestorShuffleDependencies()方法,
// 迴圈每個parent,呼叫newOrUsedShuffleStage()方法,建立一個新的ShuffleMapStage,
// 並加入到資料結構shuffleToMapStage中去
//
// 它的定義為:private[scheduler] val shuffleToMapStage = new HashMap[Int, ShuffleMapStage]
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage // 有則直接返回
case None => // 沒有
// We are going to register ancestor shuffle dependencies
// 呼叫getAncestorShuffleDependencies()方法,傳入ShuffleDependency中的rdd
// 發現還沒有在shuffleToMapStage中註冊的祖先shuffle dependencies
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
// 並迴圈返回的parents,呼叫newOrUsedShuffleStage()方法,建立一個新的ShuffleMapStage,
// 並加入到資料結構shuffleToMapStage中去
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// Then register current shuffleDep
// 最後註冊當前shuffleDep,並加入到資料結構shuffleToMapStage中,返回stage
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}從getShuffleMapStage()方法的註釋就能看出,這個方法的主要作用就是針對給定的shuffle dependency的map端,獲取或者建立一個ShuffleMapStage。為何是Get or create呢?通過原始碼得知,getShuffleMapStage()方法首先會根據shuffleDep.shuffleId從資料結構shuffleToMapStage中查詢哦是否存在對應的stage,如果存在則直接返回,如果不存在,則呼叫newOrUsedShuffleStage()方法建立一個Stage並新增到資料結構shuffleToMapStage中,方便後續需要使用此Stage者直接使用。在此之前,會根據入參ShuffleDependency的rdd發現還沒有在shuffleToMapStage中註冊的祖先shuffle dependencies,然後遍歷每個ShuffleDependency,呼叫newOrUsedShuffleStage()方法為每個ShuffleDependency產生Stage並新增到資料結構shuffleToMapStage中。
下面,我們看下這個getAncestorShuffleDependencies()方法的實現,程式碼如下:
/** Find ancestor shuffle dependencies that are not registered in shuffleToMapStage yet */
// 根據傳入的RDD,發現還沒有在shuffleToMapStage中未註冊過的祖先shuffle dependencies
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
// 存放parents的棧:Stack
val parents = new Stack[ShuffleDependency[_, _, _]]
// 存放已經處理過的RDD的雜湊表:HashSet
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
// 存放等待呼叫visit的RDD的棧:Stack
val waitingForVisit = new Stack[RDD[_]]
// 定義方法visit()
def visit(r: RDD[_]) {
if (!visited(r)) {// 如果之前沒有處理過
visited += r // 標記為已處理
// 迴圈RDD的所有依賴
for (dep <- r.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] => // 如果是ShuffleDependency
// 如果shuffleToMapStage中沒有,新增到parents中
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
// 將該dependence的rdd壓入waitingForVisit棧頂部
waitingForVisit.push(dep.rdd)
}
}
}
// 將RDD壓入到waitingForVisit頂部
waitingForVisit.push(rdd)
// 迴圈waitingForVisit,針對每個RDD呼叫visit()方法
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
// 返回parents
parents
}parents:存放parents的棧,即Stack,用於存放入參RDD的在shuffleToMapStage中未註冊過的祖先shuffle dependencies;
visited:存放已經處理過的RDD的雜湊表,即HashSet;
waitingForVisit:存放等待被處理的RDD的棧,即Stack;
定義了一個visit()方法,入參為RDD,針對傳入的RDD,如果之前沒有處理過則標記為已處理,並迴圈RDD的所有依賴,如果是如果是ShuffleDependency,並且其依賴的shuffleId在shuffleToMapStage中沒有,新增到parents中,否則直接跳過,最後無論為何種Dependency,都將該dependence的rdd壓入waitingForVisit棧頂部,等待後續處理。
接下來,我們再看下newOrUsedShuffleStage()方法,其程式碼如下:
/**
* Create a shuffle map Stage for the given RDD. The stage will also be associated with the
* provided firstJobId. If a stage for the shuffleId existed previously so that the shuffleId is
* present in the MapOutputTracker, then the number and location of available outputs are
* recovered from the MapOutputTracker
*
* 為給定的RDD建立一個ShuffleStage
*/
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
// 從shuffleDep中獲取RDD
val rdd = shuffleDep.rdd
// 獲取RDD的分割槽個數,即未來的task數目
val numTasks = rdd.partitions.length
// 構造一個ShuffleMapStage例項
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// 如果mapOutputTracker中存在
// 根據shuffleId從mapOutputTracker中獲取序列化的多個MapOutputStatus物件
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
// 反序列化
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
// 迴圈
(0 until locs.length).foreach { i =>
if (locs(i) ne null) {
// locs(i) will be null if missing
// 將
stage.addOutputLoc(i, locs(i))
}
}
} else {
// 如果mapOutputTracker中不存在,註冊一個
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
// 註冊的內容為
// 1、根據shuffleDep獲取的shuffleId;
// 2、rdd中分割槽的個數
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}1、構造一個ShuffleMapStage例項stage;
2、判斷是否在mapOutputTracker中存在:
(1)如果不存在,呼叫mapOutputTracker的registerShuffle()方法註冊一個,註冊的內容為根據shuffleDep獲取的shuffleId和rdd中分割槽的個數;
(2)如果存在,根據shuffleId從mapOutputTracker中獲取序列化的多個MapOutputStatus物件,反序列化後迴圈,逐個新增到stage中。
緊接著,看下newShuffleMapStage()方法,其程式碼如下:
/**
* Create a ShuffleMapStage as part of the (re)-creation of a shuffle map stage in
* newOrUsedShuffleStage. The stage will be associated with the provided firstJobId.
* Production of shuffle map stages should always use newOrUsedShuffleStage, not
* newShuffleMapStage directly.
*/
private def newShuffleMapStage(
rdd: RDD[_],
numTasks: Int,
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int,
callSite: CallSite): ShuffleMapStage = {
// 獲得parentStages和下一個stageId
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, firstJobId)
// 建立一個ShuffleMapStage
val stage: ShuffleMapStage = new ShuffleMapStage(id, rdd, numTasks, parentStages,
firstJobId, callSite, shuffleDep)
// 將stage加入到資料結構stageIdToStage
stageIdToStage(id) = stage
updateJobIdStageIdMaps(firstJobId, stage)
stage
}下面,簡單看下mapOutputTracker註冊的程式碼。
// 註冊shuffle
def registerShuffle(shuffleId: Int, numMaps: Int) {
// 將shuffleId、numMaps大小和MapStatus型別的Array陣列的對映關係,放入mapStatuses中
// mapStatuses為TimeStampedHashMap[Int, Array[MapStatus]]型別的資料結構
if (mapStatuses.put(shuffleId, new Array[MapStatus](numMaps)).isDefined) {
throw new IllegalArgumentException("Shuffle ID " + shuffleId + " registered twice")
}
}經歷了這多又長又大篇幅的敘述,現在返回newResultStage()方法,在通過getParentStagesAndId()方法獲取parent stages及其result stage的id後,緊接著建立一個ResultStage,並將stage加入到stageIdToStage中,最後在呼叫updateJobIdStageIdMaps()更新資料結構jobIdToStageIds後,返回stage。
下面,簡單看下updateJobIdStageIdMaps()方法。程式碼如下:
/**
* Registers the given jobId among the jobs that need the given stage and
* all of that stage's ancestors.
*/
private def updateJobIdStageIdMaps(jobId: Int, stage: Stage): Unit = {
// 定義一個函式updateJobIdStageIdMapsList()
def updateJobIdStageIdMapsList(stages: List[Stage]) {
if (stages.nonEmpty) {
// 獲取列表頭元素
val s = stages.head
// 將jobId新增到Stage的jobIds中
s.jobIds += jobId
// 更新jobIdToStageIds,將jobId與stageIds的對應關係新增進去
jobIdToStageIds.getOrElseUpdate(jobId, new HashSet[Int]()) += s.id
val parents: List[Stage] = getParentStages(s.rdd, jobId)
val parentsWithoutThisJobId = parents.filter { ! _.jobIds.contains(jobId) }
updateJobIdStageIdMapsList(parentsWithoutThisJobId ++ stages.tail)
}
}
// 呼叫函式updateJobIdStageIdMapsList()
updateJobIdStageIdMapsList(List(stage))
}這個方法的實現比較簡單,在其內部定義了一個函式updateJobIdStageIdMapsList(),首選傳入result stage,將jobId新增到stage的jobIds中,更新jobIdToStageIds,將jobId與stageIds的對應關係新增進去,然後根據給定stage的RDD獲取其parent stages,過濾出不包含此JobId的parents stages,再遞迴呼叫updateJobIdStageIdMapsList()方法,直到全部stage都處理完。
至此,第二階段Stage劃分大體流程已分析完畢,有遺漏或不清楚的地方,以後再查缺補漏以及細化及更正錯誤。