
TensorFlow——訓練自己的資料(五)模型評估
模型的評估主要有幾個指標:平均準確率、識別的時間、loss下降變化等。Tensorflow提供了一個log視覺化的工具tensroboard。要看到log就必須在訓練時用summary去記錄想要顯示的東西,包括acc\loss甚至image。
Tensorboard的使用
windows下,在CMD命令列或者shell介面下輸入(在存放log檔案的目錄開啟才有效,不然在chrome瀏覽器無法看見圖):
tensorboard --logdir=D:\Study\Python\Projects\Cats_vs_Dogs\Logs\train然後開啟瀏覽器輸入返回的值:
127.0 進入tensorboard,檢視各種log
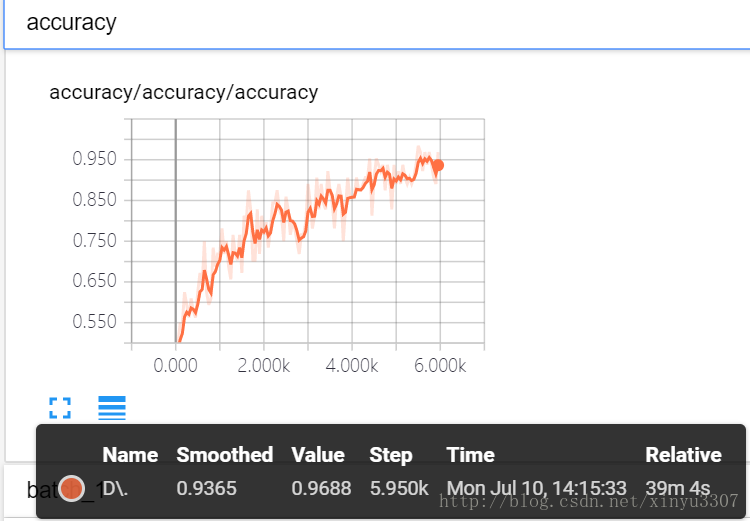
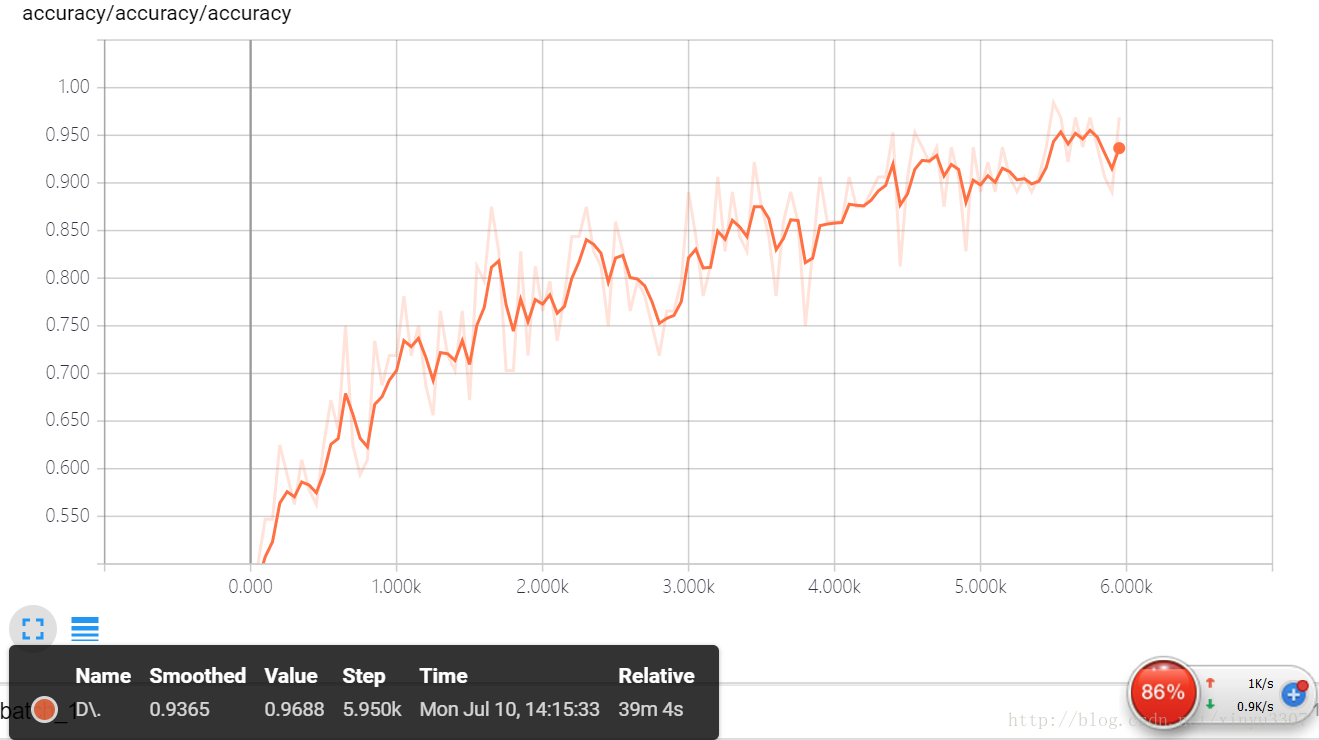
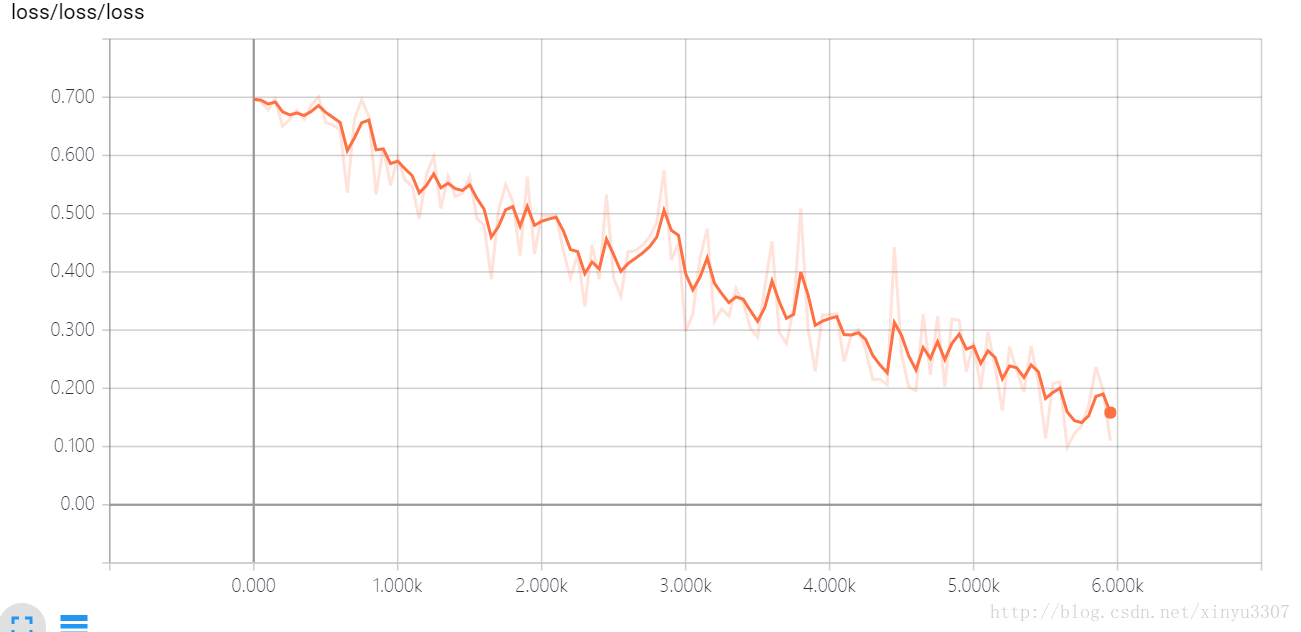
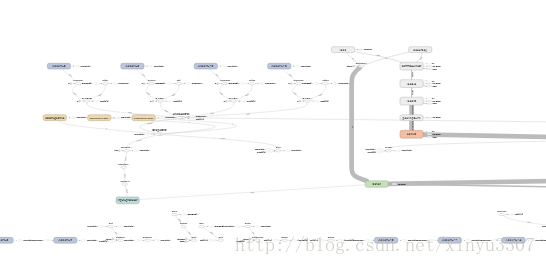
這個不知道幹嘛的
相關推薦
TensorFlow——訓練自己的資料(五)模型評估
模型的評估主要有幾個指標:平均準確率、識別的時間、loss下降變化等。Tensorflow提供了一個log視覺化的工具tensroboard。要看到log就必須在訓練時用summary去記錄想
TensorFlow 訓練 MNIST 資料(二)
上一篇部落格講了一個簡單的基於 SoftMax 迴歸的學習模型,準確率大概在91%左右,這篇構建一個深度卷積神經網路。主要的教程還是來自於極客學院,但是講的很瑣碎,我把自己整理的思路和最後寫的完整的程式碼在這篇博文中呈現出來。 這篇文章大致構建的網路結構如下: 輸入層--&
TensorFlow——訓練自己的資料(三)模型訓練
檔案training.py 匯入檔案 import os import numpy as np import tensorflow as tf import input_data
TensorFlow——訓練自己的資料(四)模型測試
獲取一張圖片 函式:def get_one_image(train): 輸入引數:train,訓練圖片的路徑 返回引數:image,從訓練圖片中隨機抽取一張圖片 n = len(tra
網路程式設計基礎【day09】:socket接收大資料(五)
本節內容 1、概述 2、socket接收大資料 3、中文字元的坑 一、概述 上篇部落格寫到了,就是說當伺服器傳送至客戶端的資料,大於客戶端設定的資料,則就會把資料服務端發過來的資料剩餘資料存在IO緩衝區中,那我們如何解決這個問題呢? 有的同學就說了: 改大客戶端接收的資料的大小=&
多執行緒學習----執行緒範圍內的共享資料(五)
執行緒範圍內的共享變數舉例: 建立三個執行緒,它們都訪問了三個物件,第一個物件設定值,第二三個物件取值,同一個執行緒設定的值,只能被相同的執行緒獲取, public class ThreadScopeShareDataStudy { private static int da
一步兩步,學習大資料(五)——flume的介紹、配置以及使用
大資料的業務處理中,資料採集佔據重要的地位,而在網際網路中大量資料產生的來源之一便是網路日誌。flume是分散式的日誌收集系統,它將各個伺服器中的資料收集起來並送到指定的地方去,可以是檔案、可以是hdfs。有關flume架構更加詳細的介紹大家可以參考 安靜的技術
深度學習框架TensorFlow學習與應用(五)——TensorBoard結構與視覺化
一、TensorBoard網路結構 舉例: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #載入資料集 mnist=input_dat
tensorflow學習筆記——使用TensorFlow操作MNIST資料(2)
tensorflow學習筆記——使用TensorFlow操作MNIST資料(1) 一:神經網路知識點整理 1.1,多層:使用多層權重,例如多層全連線方式 以下定義了三個隱藏層的全連線方式的神經網路
人工智慧(3)- 模型評估和調參
1.pipeline 管道利用 pipeline的概念可以從這裡抽象出來:將一件需要重複做的事情切割成各個不同的階段,每一個階段由獨立的單元負責。所有待執行的物件依次進入作業佇列。 管道機智在機器學習中得以應用的根源
機器學習(西瓜書)學習筆記(一)---------模型評估與選擇
1、經驗誤差與過擬合 經驗誤差:一般的,我們把學習器的實際預測輸出與樣本的真實輸出之間的差異稱為“誤差”,學習器在訓練集上的誤差稱為“訓練誤差”或“經驗誤差”,在新樣本上的誤差稱為“泛化誤差”; 通常我們想要的一個學習器是能夠通過訓練樣本的學習後能較準確的
使用tensorflow訓練自己的資料集(四)——計算模型準確率
使用tensorflow訓練自己的資料集—定義反向傳播 上一篇使用tensorflow訓練自己的資料集(三)中製作已經介紹了定義反向傳播過程來訓練神經網路,訓練完神經網路後應對神經網路進行準確率的計算。 import time import forward import back
Tensorflow + ResNet101 + fasterRcnn 訓練自己的模型 資料(一)
一、資料準備: 1、PASCAL VOC資料集格式 2、資料擴充:做了旋轉【0, 90,180,270】(備註:這裡可以不做那麼多許旋轉,fasterrcnn在訓練的時候要做圖片的映象變換)、降取樣 降取樣: import os import cv2 import nu
利用tensorflow訓練自己的圖片資料(3)——建立網路模型
一. 說明 在上一部落格——利用tensorflow訓練自己的圖片資料(2)中,我們已經獲得了神經網路的訓練輸入資料:image_batch,label_batch。接下就是建立神經網路模型,筆者的網路模型結構如下: 輸入資料:(batch_size,IMG_W,IMG_H
使用Tensorflow來讀取訓練自己的資料(三)
本文詳解training.py是如何編寫的。 import os import numpy as np import tensorflow as tf import input_data import model N_CLASSES = 2 # 二分類問題,只有是還是否,即0,1 IMG_W
使用Tensorflow來讀取訓練自己的資料(二)
接上一篇,繼續分析,model.py,也就是模型的構建。兩個卷積層,兩個池化層,以及後面的全連線層怎麼通過tensorflow定義的。 import tensorflow as tf def inference(images, batch_size, n_classess): # c
使用Tensorflow來讀取訓練自己的資料(一)
本文的程式碼以及思路都是參考別人的,現在只是整理一下思路,做一些解釋,畢竟是小白。 首先本文所使用的圖片資料都是https://www.kaggle.com/下載的,使用的是貓和狗的圖片集,https://www.kaggle.com/c/dogs-vs-cats-redux-ker
使用tensorflow訓練自己的資料集(一)——製作資料集
使用tensorflow訓練自己的資料集—製作資料集 想記錄一下自己製作訓練集並訓練的過、希望踩過的坑能幫助後面入坑的人。 本次使用的訓練集的是kaggle中經典的貓狗大戰資料集(提取碼:ufz5)。因為本人筆記本配置很差還不是N卡所以把train的資料分成了訓練集和測試集並沒有使用
使用tensorflow訓練自己的資料集(一)
使用tensorflow訓練自己的資料集 想記錄一下自己製作訓練集並訓練的過、希望踩過的坑能幫助後面入坑的人。 本次使用的訓練集的是kaggle中經典的貓狗大戰資料集(提取碼:ufz5)。因為本人筆記本配置很差還不是N卡所以把train的資料分成了訓練集和測試集
使用tensorflow訓練自己的資料集(二)
使用tensorflow訓練自己的資料集—定義神經網路 上一篇使用tensorflow訓練自己的資料集(一)中製作已經介紹了製作自己的資料集、接下來就是定義向前傳播過程了也就是定義神經網路。本次使用了兩層卷積兩層最大池化兩層全連線神經網路最後加softmax層的