
MYSQL索引最佳實踐
你做了一個明智的選擇
-
理解索引對開發和dba來說都是極其重要
-
差勁的索引對產品問題負相當大的一部分責任
-
索引不是多麼高深的問題
MySQL 索引一覽表
-
理解索引
-
為你的應用建立最佳索引
-
擁抱MySQL的限制
簡述索引
索引有什麼用
-
為從資料庫讀取資料加速
-
強制約束 (唯一索引 UNIQUE, 外來鍵 FOREIGN KEY)
-
沒有任何索引的情況下查詢頁能正常執行
-
但是那可能需要執行很長的時間
你可能聽說過的索引型別
-
BTREE索引 – mysql中主要的索引型別
-
RTREE索引 – 只有MyISAM支援, 用於GIS
-
HASH 索引 – MEMORY, NDB 支援
-
BITMAP 索引 – MySQL 不支援
-
FULLTEXT 索引 – MyISAM, Innodb(MySQL 5.6以上支援)
類BTREE索引家族
-
有很多不同的實現
-
在可加速的操作中共享相同的屬性
-
記憶體相比硬碟使生活變得美好
-
-
B+樹通常用於硬碟儲存
-
資料儲存於葉子節點
-
B+Tree 示例
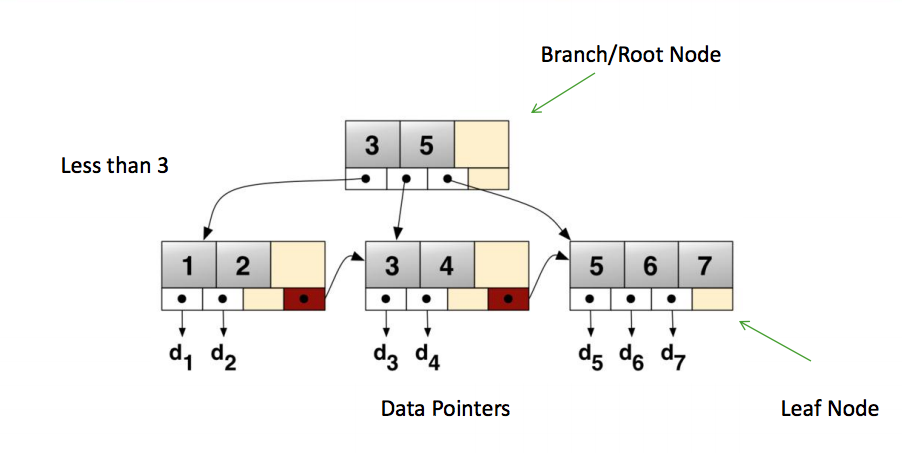
MyISAM、Innodb索引對比
-
MyISAM
-
資料指標指向資料檔案中的物理位置
-
所有索引都是一樣的(指向物理位置))
-
-
Innodb
-
主鍵索引 (顯式或隱式) - 直接將資料儲存於索引的葉子節點,而不是指標
-
二級索引 – 儲存主鍵索引的值作為資料指標
-
BTREE索引能用於什麼操作 ?
-
查詢所有 KEY=5 的記錄 (點查詢)
-
查詢所有 KEY>5 的記錄 (開合間)
-
查詢所有 5<KEY<10 的記錄 (閉合間)
-
不適用於:查詢KEY最後一個數字等於0的所有記錄
-
因為這不能定義為範圍查詢操作
-
字元索引
-
這(和數值)沒什麼區別… 真的
-
collation是為字串定義的排序規則
-
如: “AAAA” < “AAAB”
-
-
字首LIKE 查詢是一種特殊的範圍查詢
-
LIKE “ABC%” 的意思是:
-
“ABC[最小值]”<KEY<“ABC[最大值]”
-
LIKE “%ABC” 無法使用索引查詢
-
聯合索引
-
是這樣進行排序的, 比較首列,然後第二列,第三列以此類推,如:
-
KEY(col1,col2,col3)
-
(1,2,3) < (1,3,1)
-
-
使用一個BTREE索引,而不是每個層級一個單獨的BTREE索引
索引的開銷
-
索引是昂貴的,不要新增多餘的索引
-
多數情況下,擴充套件索引比新增一個新的索引要好
-
-
寫 - 更新索引常常是資料庫寫操作的主要開銷
-
讀 - 需要再硬碟和記憶體開銷空間; 查詢優化中需要額外的開銷
索引成本的影響
-
長主鍵索引(Innodb) – 使所有相應的二級索引 變得更長、更慢
-
“隨機”主鍵索引(Innodb) – 插入導致大量的頁面分割
-
越長的索引通常越慢
-
Index with insertion in random order – SHA1(‘password’)
-
低區分度的索引是低劣的 – 在性別欄位建的索引
-
相關索引是不太昂貴的– insert_time與自增id是相關的
Innodb表的索引
-
資料按主鍵聚集
-
選擇最佳的欄位作為主鍵
-
比如評論表 – (POST_ID,COMMENT_ID) 是作為主鍵的不錯選擇,使得單個post的評論聚在一起
-
-
或者 “打包” 單個 BIGINT(欄位)
-
主鍵隱式地附加到所有索引中
-
KEY (A) 實質上是 KEY (A,ID)
-
-
覆蓋索引,有利於排序
MySQL是如何使用索引的
-
查詢
-
排序
-
避免讀取資料(只讀取索引)
-
其他專門的優化
使用索引進行查詢
-
SELECT * FROM EMPLOYEES WHERELAST_NAME=“Smith”
-
這是典型的索引 KEY(LAST_NAME)
-
-
可以使用複合索引
-
SELECT * FROM EMPLOYEES WHERELAST_NAME=“Smith” AND DEPT=“Accounting”
-
將會使用索引 KEY(DEPT,LAST_NAME)
-
複合索引比較複雜
-
Index (A,B,C) - 欄位順序問題
-
下列情形將會使用索引進行查詢(全條件)
-
A>5
-
A=5 AND B>6
-
A=5 AND B=6 AND C=7
-
A=5 AND B IN (2,3) AND C>5
-
-
下列條件將不會使用索引
-
B>5 – 條件沒有B欄位前的A
-
B=6 AND C=7 - 條件沒有B、C欄位前的A
-
-
以下情形使用索引的一部分
-
A>5 AND B=2 - 第一個欄位A的範圍查詢,導致只用上了索引中A欄位的部分
-
A=5 AND B>6 AND C=2 - B欄位的範圍範圍查詢,導致只使用了索引中A和B兩個欄位的部分
-
MySQL優化器的第一法則
-
在複合索引中,MySQL在遇到返回查詢(<,>,BETWEEN)時,將停止中止剩餘部分(索引)的使用;但是使用IN(…)的"範圍查詢"則可以繼續往右使用索引(的更多部分)
所用索引進行排序
-
SELECT * FROM PLAYERS ORDER BY SCOREDESC LIMIT 10
-
將使用索引 KEY(SCORE)
-
不使用索引將進行非常昂貴的“filesort”操作(externalsort)
-
-
常常使用組合索引進行查詢
-
SELECT * FROM PLAYERS WHERE COUNTRY=“US”ORDER BY SCORE DESC LIMIT 10
-
最佳選擇是 KEY(COUNTRY,SCORE)
-
高效排序的聯合索引
-
變得更加受限!
-
KEY(A,B)
-
以下情形將會使用索引進行排序
-
ORDER BY A - 對索引首欄位進行排序
-
A=5 ORDER BY B - 對第一個欄位進行點查詢,對第二個欄位進行排序
-
ORDER BY A DESC, B DESC - 對兩個欄位進行相同的順序進行排序
-
A>5 ORDER BY A - 對首欄位進行範圍查詢,並對首欄位進行排序
-
-
以下情形將不使用索引進行排序
-
ORDER BY B - 對第二個欄位進行排序(未使用首欄位)
-
A>5 ORDER BY B – 對首欄位進行範圍查詢,對第二個欄位進行排序
-
A IN(1,2) ORDER BY B - 對首欄位進行IN查詢,對第二個欄位進行排序
-
ORDER BY A ASC, B DESC - 對兩個欄位進行不同順序的排序
-
MySQL使用索引排序的規則
-
不能對兩個欄位進行不同順序的排序
-
對非ORDER BY部分的欄位只能使用點查詢(=)– 在這種情形下,IN()也不行
避免讀取資料(只讀取索引)
-
“覆蓋索引”– 這裡指 適用於特定查詢的索引,而不是一種索引的型別
-
只讀取索引,而不去讀取資料
-
SELECT STATUS FROM ORDERS WHERECUSTOMER_ID=123
-
KEY(CUSTOMER_ID,STATUS)
-
-
索引通常比資料本身要小
-
(索引)讀取起來更有次序– 讀取資料指標通常是隨機的
Min/Max的優化
-
索引可以幫助優化 MIN()/MAX() 這類的統計函式– 但只包含以下這些:
-
SELECT MAX(ID) FROM TBL;
-
SELECT MAX(SALARY) FROM EMPLOYEEGROUP BY DEPT_ID
-
將受益於 KEY(DEPT_ID,SALARY)
-
“Using index for group-by”
-
聯表查詢中索引的使用
-
MySQL 使用 “巢狀迴圈(Nested Loops)”進行聯表查詢
-
SELECT * FROM POSTS,COMMENTS WHEREAUTHOR=“Peter” AND COMMENTS.POST_ID=POSTS.ID
-
掃描表POSTS查詢所有複合條件的 posts
-
迴圈posts 在表COMMENTS 中查詢 每個post的所有comments
-
-
使每個關聯的表(關聯欄位)都使用上索引顯得非常的重要
-
索引只有在被查詢的欄位上是必要的– POSTS.ID欄位的索引再本次查詢中是用不上的
-
重新設計不能很好的所有索引的聯合查詢吧
使用多索引
-
MySQL可以使用超過1個索引
-
“索引合併”
-
-
SELECT * FROM TBL WHERE A=5 AND B=6– 可以分別使用索引 KEY(A)和 KEY(B)
-
索引 KEY(A,B) 是更好的選擇
-
-
SELECT * FROM TBL WHERE A=5 OR B=6– 兩個索引同時分別被使用
-
索引 KEY(A,B) 在這個查詢中無法使用
-
字首索引
-
你可以在欄位最左字首建立索引
-
ALTER TABLE TITLE ADD KEY(TITLE(20));
-
需要對BLOB/TEXT型別的欄位建立索引
-
能顯著的減少空間使用
-
不能用於覆蓋索引
-
選擇字首長度成為一個問題
-
選擇字首長度
-
字首應該有足夠的區分度
-
比較distinct字首、distinct整個欄位的值
-
mysql> select count(distinct(title)) total,count(distinct(left(title,10))) p10,count(distinct(left(title,20))) p20 from title;
| total | p10 | p20 |
|---|---|---|
| 998335 | 624949 | 960894 |
1 row in set (44.19 sec)
-
檢查異常值
-
確保不會有很多記錄使用相同的字首
-
使用最多的Titlemysql> select count(*) cnt, title tl from title group by tl order by cnt desc limit 3;
| cnt | tl |
|---|---|
| 136 | The Wedding |
| 129 | Lost and Found |
| 112 | Horror Marathon |
3 rows in set (27.49 sec)
使用最多的Title 字首 mysql> select count(*) cnt, left(title,20) tl from title group by tl order by cnt desc limit 3;
| cnt | tl |
|---|---|
| 184 | Wetten, dass..? aus |
| 136 | The Wedding |
| 129 | Lost and Found |
3 rows in set (33.23 sec)
MySQL如何選擇使用哪個索引的?
-
每次查詢動態選擇– 查詢文字中常量很重要
-
評估需要查詢的行數 對給定的索引,在表中進行"dive"
-
如果(dive)不可行時,使用 “Cardinality” 進行統計– 這是進行 ANALYZE TABLE時 更新的
更多關於索引的選擇
-
並不只是最小化掃描行數
-
很多其他的heuristics(嘗試) and hacks– 對Innodb來說主鍵是很重要的
-
覆蓋索引效益
-
Full table scan is faster, all being equal(這句不是太明白)
-
我們也可以使用索引進行排序
-
-
須知
-
驗證MYSQL實際使用的執行計劃
-
注意是可以根據常量和資料動態改變的
-
使用EXPLAIN
-
EXPLAIN 是一個很好的工具,可以看到MYSQL將如何進行查詢
mysql> explain select max(season_nr) from title group by production_year;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | title | range | NULL | production_year | 5 | NULL | 201 | Using index for group-by |
1 row in set (0.01 sec)
MySQL Explain 101
-
“type” 從好到差排序如下:– system,const,eq_ref,ref,range,index,ALL
-
注意 “rows” – 更大的數值意味著更慢的查詢
-
檢查 “key_len” – 顯示索引的哪些部分真實使用到了
-
留意"Extra"
-
Using Index - 好
-
Using Filesort, Using Temporary - 差
-
索引策略
-
為你的關鍵效能查詢集建立索引– 整體取審視他們,而不是一個個看
-
最好所有的查詢條件和聯表條件都使用索引– 起碼區分度最高的部分是
-
一般來說,可以的話,擴充套件索引,而不是建立新的索引
-
修改時記得驗證對效能的影響
索引策略示例
-
按能支援更多查詢的順序建立索引
-
SELECT * FROM TBL WHERE A=5 AND B=6
-
SELECT * FROM TBL WHERE A>5 AND B=6– 對兩個查詢來說 KEY(B,A) 是更好的選擇
-
-
把所有都是點查詢的欄位放到索引的首位
-
不要新增非效能關鍵查詢的索引– 太多的索引會使MYSQL慢下來
Trick #1: 列舉範圍
-
KEY (A,B)
-
SELECT * FROM TBL WHERE A BETWEEN 2AND 4 AND B=5
-
將只使用索引的第一個欄位部分
-
-
SELECT * FROM TBL WHERE A IN (2,3,4) ANDB=5
-
索引的兩個欄位部分都使用
-
Trick #2: 新增一個假的條件
-
KEY (GENDER,CITY)
-
SELECT * FROM PEOPLE WHERE CITY=“NEWYORK”
-
完全用不上索引
-
-
SELECT * FROM PEOPLE WHERE GENDER IN(“M”,”F”) AND CITY=“NEW YORK”
-
將用上索引
-
這個Trick在低區別度的欄位上可以很好的使用
-
Gender, Status, Boolean Types etc
-
Trick #3: 虛實Filesort
-
KEY(A,B)
-
SELECT * FROM TBL WHERE A IN (1,2) ORDER BYB LIMIT 5;
-
無法使用索引進行排序
-
-
(SELECT FROM TBL WHERE A=1 ORDER BY B LIMIT 5) UNION ALL (SELECT FROM TBL WHERE A=2 ORDER BY B LIMIT 5) ORDER BY B LIMIT 5;
-
將會用上索引,而“filesort”只用於對不超過10行記錄
-
作者的ppt發出來後,很多人向他諮詢相關問題,另外專門做了回覆,oschina已經有對回覆進行了翻譯:
http://www.oschina.net/transl...