
倒排索引構建演算法BSBI和SPIMI
參考文獻:
http://www.cnblogs.com/fly1988happy/archive/2012/04/01/2429000.html
http://blog.csdn.net/v_july_v/article/details/7109500
演算法介紹
在資訊搜尋領域,構建索引一直是是一種非常有效的方式,但是當搜尋引擎面對的是海量資料的時候,你如果要從茫茫人海的資料中去找出資料,顯然這不是一個很好的辦法。於是倒排索引這個概念就被提了出來。再說倒排索引概念之前,先要理解一下,一般的索引檢索資訊的方式。比如原始的資料來源假設都是以文件的形式被分開,文件1擁有一段內容,文件2也富含一段內容,文件3同樣如此。然後給定一個關鍵詞,要搜尋出與此關鍵詞相關的文件,自然而然我們聯想到的辦法就是一個個文件的內容去比較,判斷是否含有此關鍵詞,如果含有則返回這個文件的索引地址,如果不是接著用後面的文件去比,這就有點類似於字串的匹配類似。很顯然,當資料量非常巨大的時候,這種方式並不適用。原來的這種方式可以理解為是索引-->關鍵詞,而倒排索引的形式則是關鍵詞--->索引位置,也就是說,給出一個關鍵詞資訊,我能立馬根據倒排索引的資訊得出他的位置。當然,這裡說的是倒排索引最後要達到的效果,至於是用什麼方式實現,就不止一種了,本文所述的就是其中比較出名的BSBI和SPIMI演算法。
演算法的原理
這裡首先給出一個具體的例項來了解一般的構造過程,先避開具體的實現方式,給定下面一組詞句。
Doc1:Mike spoken English Frequently at home.And he can write English every day.
Doc2::Mike plays football very well.
首先我們必須知道,我們需要的是一些關鍵的資訊,諸如一些修飾詞等等都需要省略,動詞的時態變化等都需要還原,如果代詞指的是同個人也能夠省略,於是上面的句子可以簡化成
Doc1:Mike spoken English home.write English.
Doc2:Mike play football.
下面進行索引的倒排構建,因為Mike出現在文件1和文件2 中,所以Mike:{1, 2}後面的詞的構造同樣的道理。最後的關係就會構成詞對應於索引位置的對映關係。理解了這個過程之後呢,可以介紹一下本文主要要說的BSBI(基於磁碟的外部排序構建索引)和SPIMI(記憶體單遍掃描構建索引)演算法了,一般來說,後者比前者常用。
BSBI
此演算法的主要步驟如下:
1、將文件中的詞進行id的對映,這裡可以用hash的方法去構造
2、將文件分割成大小相等的部分。
3、將每部分按照詞ID對上文件ID的方式進行排序
4、將每部分排序好後的結果進行合併,最後寫出到磁碟中。
5、然後遞迴的執行,直到文件內容全部完成這一系列操作。
這裡有一張示意圖:
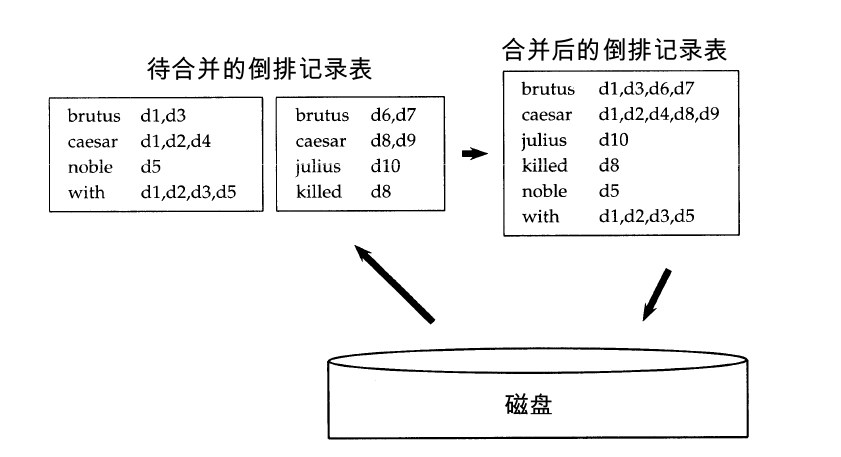
在演算法的過程中會用到讀緩衝區和寫緩衝區,至於期間的大小多少如何配置都是看個人的,我在後面的程式碼實現中也有進行設定。至於其中的排序演算法的選擇,一般建議使用效果比較好的快速排序演算法,但是我在後面為了方便,直接用了自己更熟悉的氣泡排序演算法,這個也看個人。
SPIMI
接下來說說SPIMI演算法,就是記憶體單遍掃描演算法,這個演算法與上面的演算法一上來就有直接不同的特點就是他無須做id的轉換,還是採用了詞對索引的直接關聯。還有1個比較大的特點是他不經過排序,直接按照先後順序構建索引,演算法的主要步驟如下:
1、對每個塊構造一個獨立的倒排索引。
2、最後將所有獨立的倒排索引進行合併就OK了。
本人為了方便就把這個演算法的實現簡潔化了,直接在記憶體中完成所有的構建工作。望讀者稍加註意。SPIMI相對比較的簡單,這裡就不給出截圖了。
演算法的程式碼實現
首先是文件的輸入資料,採用了2個一樣的文件,我也是實在想不出有更好的測試資料了
doc1.txt:
[java] view plaincopyprint?- Mike studyed English hardly yesterday
- He got the 100 at the last exam
- He thinks English is very interesting
doc2.txt:
[java] view plaincopyprint?- Mike studyed English hardly yesterday
- He got the 100 at the last exam
- He thinks English is very interesting
- package InvertedIndex;
- import java.io.BufferedReader;
- import java.io.File;
- import java.io.FileNotFoundException;
- import java.io.FileOutputStream;
- import java.io.FileReader;
- import java.io.IOException;
- import java.io.PrintStream;
- import java.util.ArrayList;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- /**
- * 文件預處理工具類
- *
- * @author lyq
- *
- */
- publicclass PreTreatTool {
- // 一些無具體意義的過濾詞
- publicstatic String[] FILTER_WORDS = new String[] { "at", "At", "The",
- "the", "is", "very" };
- // 批量文件的檔案地址
- private ArrayList<String> docFilePaths;
- // 輸出的有效詞的存放路徑
- private ArrayList<String> effectWordPaths;
- public PreTreatTool(ArrayList<String> docFilePaths) {
- this.docFilePaths = docFilePaths;
- }
- /**
- * 獲取文件有效詞檔案路徑
- *
- * @return
- */
- public ArrayList<String> getEFWPaths() {
- returnthis.effectWordPaths;
- }
- /**
- * 從檔案中讀取資料
- *
- * @param filePath
- * 單個檔案
- */
- private ArrayList<String> readDataFile(String filePath) {
- File file = new File(filePath);
- ArrayList<String[]> dataArray = new ArrayList<String[]>();
- ArrayList<String> words = new ArrayList<>();
- try {
- BufferedReader in = new BufferedReader(new FileReader(file));
- String str;
- String[] tempArray;
- while ((str = in.readLine()) != null) {
- tempArray = str.split(" ");
- dataArray.add(tempArray);
- }
- in.close();
- } catch (IOException e) {
- e.getStackTrace();
- }
- // 將每行詞做拆分加入到總列表容器中
- for (String[] array : dataArray) {
- for (String word : array) {
- words.add(word);
- }
- }
- return words;
- }
- /**
- * 對文件內容詞彙進行預處理
- */
- publicvoid preTreatWords() {
- String baseOutputPath = "";
- int endPos = 0;
- ArrayList<String> tempWords = null;
- effectWordPaths = new ArrayList<>();
- for (String filePath : docFilePaths) {
- tempWords = readDataFile(filePath);
- filterWords(tempWords, true);
- // 重新組裝出新的輸出路徑
- endPos = filePath.lastIndexOf(".");
- baseOutputPath = filePath.substring(0, endPos);
- writeOutOperation(tempWords, baseOutputPath + "-efword.txt");
- effectWordPaths.add(baseOutputPath + "-efword.txt");
- }
- }
-
相關推薦
倒排索引構建演算法BSBI和SPIMI
參考文獻: http://www.cnblogs.com/fly1988happy/archive/2012/04/01/2429000.html http://blog.csdn.net/v_july_v/article/details/710950
倒排索引構建演算法SPIMI(已實現,修訂版)
TA011121600045170###347###A0###2###20111214213127###86b4bc20eb98b1eb21932ebf5dcfcca5###1###蘭州###空氣質量# TA011121600045168###347###A0###2###20111215181000###e
Lucene倒排索引簡述 細說倒排索引構建
在《Lucene倒排索引簡述 之索引表》和《Lucene倒排索引簡述 之倒排表》兩篇文章中介紹了Lucene如何將倒排索引結構寫入索引檔案,如何為實現高效搜尋過程奠定了基礎。 Lucene需要收集每個Term在整個Segment的所有資訊(DocID/Term
Hadoop鏈式MapReduce、多維排序、倒排索引、自連線演算法、二次排序、Join效能優化、處理員工資訊Join實戰、URL流量分析、TopN及其排序、求平均值和最大最小值、資料清洗ETL、分析氣
Hadoop Mapreduce 演算法彙總 第52課:Hadoop鏈式MapReduce程式設計實戰...1 第51課:Hadoop MapReduce多維排序解析與實戰...2 第50課:HadoopMapReduce倒排索引解析與實戰...3 第49課:Hado
倒排索引原理和實現
轉載https://blog.csdn.net/u011239443/article/details/60604017 倒排索引原理和實現 關於倒排索引 場景是:給定幾個關鍵詞,找出包含關鍵詞的文件 倒排索引: 不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置
MapReduce--帶有詞頻統計的倒排索引演算法
倒排索引:根據單詞來查詢文件 實現: 單詞1 文件1:次數,文件2:次數,文件5:次數 單詞1 平均次數 單詞2 文件3:次數,文件6:次數 單詞2 平均次數 Mapper: 輸出: key: term- ->docid value: 1 public static cla
ElasticSearch所使用的倒排索引的思想和使用場景
2)資料操作簡單:搜尋引擎使用的資料操作簡單 ,一般而言 ,只需要增、 刪、 改、 查幾個功能 ,而且資料都有特定的格式 ,可以針對這些應用設計出簡單高效的應用程式。而一般的資料庫系統則支援大而全的功能 ,同時損失了速度和空間。最後 ,搜尋引擎面臨大量的使用者檢索需求 ,這要求搜尋引擎在檢索程式的設計上要分
【索引演算法】倒排索引
1.簡介 倒排索引源於實際應用中需要根據屬性的值來查詢記錄。這種索引表中的每一項都包括一個屬性值和具有該屬性值的各記錄的地址。由於不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置,因而稱為倒排索引(inverted index)。帶有倒排索引的檔案我們稱為倒排索引檔案,簡稱倒排檔案(inverted
lucene倒排索引--fst和SkipList的結合
1. 使用FST儲存詞典,FST可以實現快速的Seek,這種結構在當查詢可以表達成自動機時(PrefixQuery、FuzzyQuery、RegexpQuery等)效率很高。(可以理解成自動機取交集)此種場景主要用在對Query進行rewrite的時候。2. FST可以表達出
一些演算法的MapReduce實現——倒排索引實現
/** * input format * docid<tab>doc content * * output format * (term:docid)<tab>(tf in this doc) * */ public s
搜尋引擎入門 --- 倒排索引演算法
搜尋引擎的索引 1.單詞——文件矩陣 單詞-文件矩陣是表達兩者之間所具有的一種包含關係的概念模型,圖3-1展示了其含義。圖3-1的每列代表一個文件,每行代表一個單詞,打對勾的位置代表包含關係。
檔案倒排索引演算法及其hadoop實現
什麼是檔案的倒排索引? 簡單講就是一種搜尋引擎的演算法。過倒排索引,可以根據單詞快速獲取包含這個單詞的文件列表。倒排索引主要由兩個部分組成:“單詞”和對應出現的“倒排檔案”。 MapReduce的設計思路 整個過程包含map、combiner、reduce三個階段,
mapreduce演算法之倒排索引
package mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.
搜尋引擎中的爬蟲和倒排索引技術
三、抓取策略 在爬蟲系統中,待抓取URL佇列是很重要的一部分。待抓取URL佇列中的URL以什麼樣的順序排列也是一個很重要的問題,因為這涉及到先抓取那個頁面,後抓取哪個頁面。而決定這些URL排列順序的方法,叫做抓取策略。下面重點介紹幾種常見的抓取策略: 1.深度優先遍歷策略 深度優先遍
【大資料】實驗三 文件倒排索引演算法
實驗三 文件倒排索引演算法 151220129 計科 吳政億 [email protected] 151220130 計科 伍昱名 [email protected] 151220135 計科 許麗軍 [email prote
elasticsearch核心知識---52.倒排索引組成結構以及實現TF-IDF演算法
首先實現了採用java 簡易的實現TF-IDF演算法package matrixOnto.Ja_9_10_va; import com.google.common.base.Preconditions; import org.nutz.lang.Strings; impo
lucene和倒排索引
https://www.cnblogs.com/zlslch/p/6440114.html 對倒排索引講的很好正排索引:由document 到單詞例如: “文件1”的ID > 單詞1:出現次數,出現位置列表;單詞2:出現次數,出現位置列表;倒排索引:由單詞到docum
Lucene倒排索引原理與實現:Term Dictionary和Index檔案 (FST詳細解析)
我們來看最複雜的部分,就是Term Dictionary和Term Index檔案,Term Dictionary檔案的字尾名為tim,Term Index檔案的字尾名是tip,格式如圖所示。 Term Dictionary檔案首先是一個Header,接下來是Pos
elasticsearch倒排索引與TF-IDF演算法
elasticsearch專欄:https://www.cnblogs.com/hello-shf/category/1550315.html 一、倒排索引(Inverted Index)簡介 在關係資料庫系統裡,索引是檢索資料最有效率的方式。但對於搜尋引擎,它並不能滿足其特殊要求,比如海量資料下比如百度
【漫畫】ES原理 必知必會的倒排索引和分詞
 # 倒排索引的初衷 ![es2_1](https://yqfile.alicdn.com/1c23ad58c7183fce376abf40042