
人臉驗證(四)--CenterLoss
有點糾結,實質上本文只是在深度學習框架下人臉識別損失函式的改進。但我還是把它歸類到端到端了。出於個人原因。
轉自:http://blog.csdn.net/yang_502/article/details/72792786
16年ECCV的文章《A Discriminative Feature Learning Approach for Deep Face Recognition》
code:https://github.com/ydwen/caffe-face
Motivation:
和metric learning的想法一致,希望同類樣本之間緊湊,不同類樣本之間分散。現有的CNN最常用的softmax損失函式來訓練網路,得到的深度特徵通常具有比較強的區分性,也就是比較強的類間判別力。關於softmax的類內判別力,作者在文章中給了toy example,很直觀的理解。

上面給的是mnist的最後一層特徵在二維空間的一個分佈情況,可以看到類間是可分的,但類記憶體在的差距還是比較大的。對於像人臉這種複雜分佈的資料,我們通常不僅希望資料在特徵空間不僅是類間可分,更重要的是類內緊湊。因為同一個人的類內變化很可能會大於類間的變化,只有保持類內緊湊,我們才能對那些類內大變化的樣本有一個更加魯棒的判定結果。也就是學習一種discriminative的特徵。
下圖就是我們希望達到的一種效果。

另外一種通俗解釋 :
一句話:通過新增center loss 讓簡單的softmax 能夠訓練出更有內聚性的特徵。
作者意圖,在配合softmax適用的時候,希望使學習到的特徵具有更好的泛化性和辨別能力。通過懲罰每個種類的樣本和該種類樣本中心的偏移,使得同一種類的樣本儘量聚合在一起。
相對於triplet(Google FaceNet: A Unified Embedding for Face Recognition and Clustering
看一張圖:
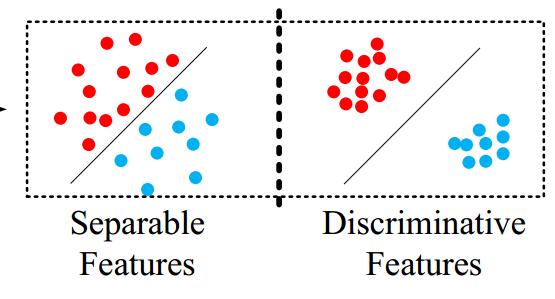
在左圖中,我們發現一個類如果太胖,那麼出現的結果就是類內距離>類間距離。(任意紅點之間的距離應該小於紅藍之間的距離。)
左邊時softmax一般結果,右邊時centerloss結果。我們期望特徵不僅可分,而且時必須差異大。如右邊圖。
Approach:
考慮保持softmax loss的類間判別力,提出center loss,center loss就是為了約束類內緊湊的條件。相比於傳統的CNN,僅改變了原有的損失函式,易於訓練和優化網路。
softmax loss :

center loss:

其中,cyi就是每類人特徵的中心表示。這個就是一個類中心特徵,希望在一類人的所有影象特徵與類中心特徵的距離總和最小。
完整的loss function:

關於center loss 的求導:

最後的loss實現可以參考code的具體實現。
Experiments:
CNN architecture

Weights in three local convolution layers are locally shared in the regions of 4 × 4, 2 × 2 and 1 × 1 respectively.
Implementation Details
Preprocessing.
使用【40】的關鍵點檢測,進行人臉對齊與檢測。人臉影象裁剪成112*96大小,畫素歸一化操作是通過減127.5再除128(??沒搞懂)
Training data.
文章中使用的訓練資料比較多,包括有CASIA-WebFace [39], CACD2000 [4], Celebrity+ [22]。但是作者他們做了影象清理,保證和測試集的人身份不重複,最後保留17,189個人的0.7M的影象。後面的訓練階段,只用了0.49M的資料,並且對影象做了水平翻轉的資料增強。
Detailed settings in CNNs.
文章比較了3中模型:we respectively train three kind of models under the supervision of softmax loss (model A), softmax loss and contrastive loss (model B), softmax loss and center loss (model C)。就是網路使用的損失函式不同。
batchsize=256,在Titan X的兩塊GPU上做訓練。A和C的初始lr=0.1,分別在16K和24K之後縮小至0.01.文章提到A在28K次收斂大致花14h,model B的收斂比較慢,初始lr=.01,咋24K和36K迭代的時候縮小學習率。B總共迭代了42K次,花22h.沒說到C的訓練時間。
Detailed settings in testing.
測試階段,將測試影象通過CNN提取深度特徵,即最後一個FC層的輸出,將原圖以及原圖的水平翻轉圖的特徵圖拼接表示成共同的表示,經過PCA降維後計算COS距離。對於識別或者驗證任務,可以是簡單通過閾值劃分或者是近鄰判定。
Experiments on the LFW and YTF datasets
使用0.7M的訓練資料,在LFW和YTF的pair對上做了人臉驗證。

Experiments on the dataset of MegaFace Challenge
使用MegaFace這個百萬級別的資料庫(干擾影象很多)。這個對於識別任務增大了難度。
資料庫具體包括:
MegaFace datasets include gallery set and probe set. The gallery set consists of more than 1 million images from 690K different individuals, as a subset of Flickr photos [35] from Yahoo. The probe set using in this challenge are two existing databases: Facescrub [24] and FGNet [1]. Facescrub dataset is publicly available dataset, containing 100K photos of 530 unique individuals (55,742 images of males and 52,076 images of females). The possible bias can be reduced by sufficient samples in each identity. FGNet dataset is a face aging dataset, with 1002 images from 82 identities. Each identity has multiple face images at different ages (ranging from 0 to 69).

Reference
【40】 MTCNN
Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint face detection and alignment using multi-task cascaded convolutional networks. arXiv preprint arXiv:1604.02878(2016)