
linux ubuntu系統下基於eclipse的hadoop開發環境搭建
hadoop是基於linux作業系統的。
本文在linux ubuntu系統下,在eclipse下配置hadoop的開發環境。
這個開發環境對linux下的hadoop偽分散式配置有效,其他配置情況不明。
如果是完全分散式環境,需要重新設定core-site.xml,hdfs-site.xml,mapred-site.xml(如果啟動了yarn,還是需要設定yarn-site.xml)
主要是從這幾個檔案中,獲得相應port值(設定外掛的general),和其他引數(用於設定hadoop的eclipse外掛advanced parameters)
需要用到hadoop的eclipse外掛。
需要用的檔案有:
core-site.xml
hdfs-site.xml
mapred-site.xml(偽分散式下為mapred-site.xml.template)
基本步驟:
1、下載hadoop eclipse外掛。注意與hadoop對應,我的是hadoop2.7.2.
2、tar解壓,並放入eclipse的plugins目錄下。
3、重啟eclipse,就能看到preferences下的mapreduce選項。
4、開啟mapreduce,將它與hadoop安裝目錄相連線。
5、eclipse下開啟mapreduce locations的view。
6、新建一個hadoop location,設定如下:
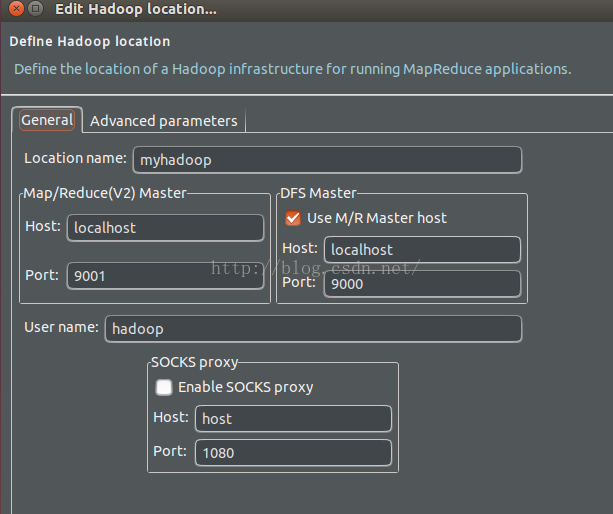
注意:DFS Master的host,port與core-site.xml的ip,埠號保持一致。
Map/Reduce的host,port與mapred-site.xml的ip,埠號保持一致。(我這裡是偽分散式,MapReduce的port設定成9001,執行是沒問題的),但mapred-site.xml中沒有設定埠號。以後可能會出問題。
location name隨便起,是為了eclipse的標示用。
user name實踐看,也可以隨便起。不過我這裡還是用了ubuntu當初配置hadoop的使用者名稱,即hadoop.
7、以上就完成了eclipse與hadoop叢集的連線。
接著就可以通過這個外掛,DFS locations檢視HDFS上的資料夾和檔案,上載/下載,刪除,更新,連線/斷開,新建資料夾等。
8、在linux終端啟動hadoop.
格式化hdfs:/bin/hdfs namenode -format
啟動namenode,datanode:/sbin/start-dfs.sh
檢視是否啟動成功:jps
在瀏覽器檢視namenode狀態:http://localhost:50070/
新建input檔案:/bin/hdfs dfs -mkdir /user/hadoop/input
執行jar包程式:/bin/hadoop jar ****-examples.jar grep input ourput 'dfs[z-a.]+'(統計以dfs開頭的行)
得到執行結果:可以在瀏覽器上看,也可以通過hadoop eclipse外掛看。
注意:hadoop程式的輸出檔案output一定不能存在。下次執行時,一定要修改輸出檔名output2,否則會出錯。
9、接下來,就是mapreduce程式的編寫工作了。下篇文章再講。
參考文章
1、http://www.linuxidc.com/Linux/2014-04/100256.htm
2、http://www.cnblogs.com/linjiqin/archive/2013/06/21/3147902.html
3、http://www.51itong.net/eclipse-hadoop2-7-0-12448.html
4、http://hadoop.apache.org/docs/current/(配置文件官方說明)