
JDK 原始碼解析 —— AtomicInteger
阿新 • • 發佈:2019-01-01
零. 前言
JDK 裡面提供的以 Atomic* 開頭的類基本原理都是一致的, 都是藉助了底層硬體級別的 Lock 來實現原子操作的。 本文以 AtomicInteger 為例進行講述, 其他的類似。閱讀本文前建議先閱讀基礎篇:Java
記憶體模型
一. 處理器原子操作: 3種加鎖方式
二. AtomicInteger 原始碼如何實現原子性 類宣告:
關於 CPU 的鎖有如下 3 種:
1. 處理器自動保證基本記憶體操作的原子性 首先處理器會自動保證基本的記憶體操作的原子性。 處理器保證從系統記憶體當中讀取或者寫入一個位元組是原子的, 意思是當一個處理器讀取一個位元組時, 其他處理器不能訪問這個位元組的記憶體地址。 奔騰 6 和最新的處理器能自動保證單處理器對同一個快取行裡進行 16/32/64 位的操作是原子的, 但是複雜的記憶體操作處理器不能自動保證其原子性, 比如跨匯流排寬度, 跨多個快取行, 跨頁表的訪問。 但是處理器提供匯流排鎖定和快取鎖定兩個機制來保證複雜記憶體操作的原子性。如果多個處理器同時對共享變數進行讀改寫(i++ 就是經典的讀改寫操作)操作, 那麼共享變數就會被多個處理器同時進行操作, 這樣讀改寫操作就不是原子的, 操作完之後共享變數的值會和期望的不一致, 舉個例子:如果 i=1,我們進行兩次 i++ 操作,我們期望的結果是 3,但是有可能結果是 2 。如下圖
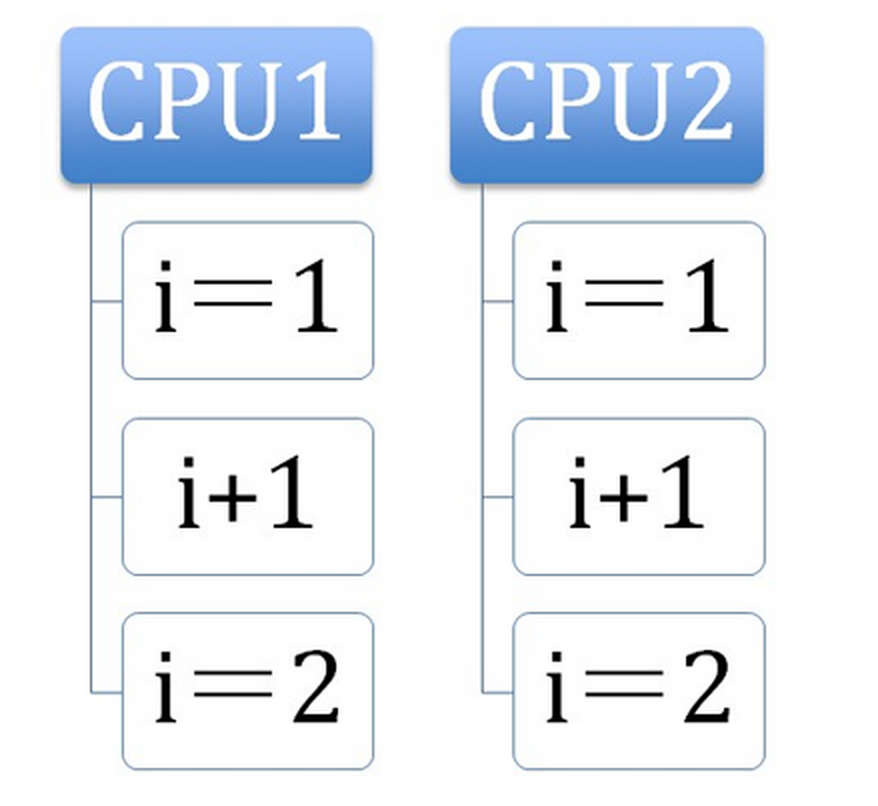
原因是有可能多個處理器同時從各自的快取中讀取變數i, 分別進行加一操作, 然後分別寫入系統記憶體當中。 那麼想要保證讀改寫共享變數的操作是原子的, 就必須保證 CPU1 讀改寫共享變數的時候,CPU2 不能操作快取了該共享變數記憶體地址的快取。
處理器使用匯流排鎖就是來解決這個問題的。 所謂匯流排鎖就是使用處理器提供的一個 LOCK# 訊號,當一個處理器在總線上輸出此訊號時, 其他處理器的請求將被阻塞住, 那麼該處理器可以獨佔使用共享記憶體。二. AtomicInteger 原始碼如何實現原子性 類宣告:
public class AtomicInteger extends Number implements java.io.Serializableprivate volatile int value;public final int get() {
return value;
}/**
* Atomically decrements by one the current value.
*
* @return the previous value
*/
public final int getAndDecrement() {
for (;;) {
int current = get();
int next = current - 1;
if (compareAndSet(current, next))
return current;
}
}public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}