
深度學習(二十八)基於多尺度深度網路的單幅影象深度估計
基於多尺度深度網路的單幅影象深度估計
作者:hjimce
一、相關理論
本篇博文主要講解來自2014年NIPS上的一篇paper:《Depth Map Prediction from a Single Image using a Multi-Scale Deep Network》,屬於CNN應用類別的文章,主要是利用卷積神經網路進行單幅影象的深度估計。我們拍照的時候,把三維的圖形,投影到二維的平面上,形成了二維影象。而深度估計的目的就是要通過二維的圖片,估計出三維的資訊,是一個逆過程,這個在三維重建領域相當重要。
這個如果是利用多張不同視角的圖片進行三維重建,會比較簡單,研究的也比較多,比如:立體視覺。然而僅僅從一張圖片進行三維深度估計,確實是一個很艱難的事。
然而本篇paper,通過深度學習的方法,從大量的訓練資料中,進行學習,一口氣提高了35%的相對精度,超出了傳統方法十幾條街。這個就像我們人一樣,我們看一張照片中的物體的時候,雖然深度資訊缺失,但是我們依舊可以估計它的形狀,這是因為我們的腦海中,儲存了無數的物體,有豐富的先驗知識,可以結合這些先驗,對一張圖片中的物體做出形狀估計。利用深度學習進行一張圖片的深度估計,也是差不多一樣的道理,通過在大量的訓練資料上,學習先驗知識,最後就可以把精度提高上去。
有點囉嗦了,迴歸正題吧,估計都等得不耐煩了,我們下面開始講解文獻:《Depth Map Prediction from a Single Image using a Multi-Scale Deep Network》的演算法原理,及其實現。
二、網路總體架構
先貼一下,網路架構圖:
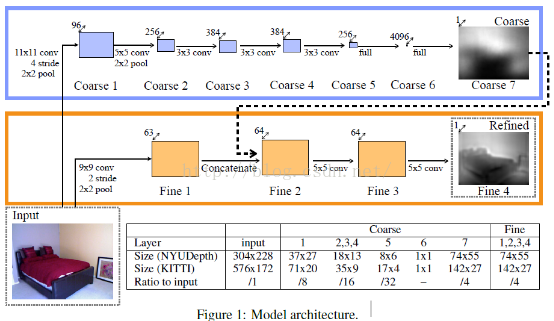
網路分為全域性粗估計和區域性精估計,這個跟人臉特徵點的DCNN網路有點類似,都屬於deep network。全域性粗估計CNN:這個網路包含了五個特徵提取層(每層包好了卷積、最大池化操作),在這五個卷積層後面,有連結了兩個全連線層,我們最後的輸出圖片的寬高變為原來的1/4。
不管是粗還是精網路,兩個網路的輸入圖片是一樣的,輸出圖片的大小也是一樣的。對於粗網路和精網路的訓練方法,paper採用的方法是,先訓練粗網路,訓練完畢後,固定粗網路的引數,然後在訓練精網路,這個與另外一篇paper:《Predicting Depth, Surface Normals and Semantic Labels》的訓練方法不同,這篇paper前面兩個scale的訓練是一起訓練的,引數一起更新。
三、coarse的網路結構
網路結構方面,基本上是模仿Alexnet的,具體可以看一下,上面的表格。我們以NYU資料集上,為例,進行下面網路結構講解。
1、輸入圖片:圖片大小為304*228
2、網路第一層:卷積核大小為11*11,卷積跨步大小為4,卷積後圖片大小為[(304-11)/4+1,(228-11)/4+1]=[74,55],特徵圖個數為96,即filter_shape = (96, 3, 11, 11)。池化採用最大重疊池化size=(3,3),跨步為2。因此網路輸出圖片的大小為:[74/2,55/2]=[37,27]。為了簡單起見,我們結合文獻作者給的原始碼進行講解,paper主頁:http://www.cs.nyu.edu/~deigen/depth/,作者提供了訓練好的模型,demo供我們測試,訓練部分的原始碼沒有提供,後面博文中貼出的原始碼均來自於paper的主頁。本層網路的相關引數如下:
[imnet_conv1]
type = conv
load_key = imagenet
filter_shape = (96, 3, 11, 11)
stride = 4
conv_mode = valid
init_w = lambda shp: 0.01*np.random.randn(*shp)
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001
weight_decay_w = 0.0005
[imnet_pool1]
type = maxpool
load_key = imagenet
poolsize = (3,3)
poolstride = (2,2)3、網路第二層:卷積核大小為5*5,卷積跨步為1,接著進行最大重疊池化,得到圖片大小為[18,13](需要加入pad)。網路結構設計方面可以參考Alexnet網路。原始碼如下:
[imnet_conv2]
type = conv
load_key = imagenet
filter_shape = (256, 96, 5, 5)
conv_mode = same
stride = 1
init_w = lambda shp: 0.01*np.random.randn(*shp)
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001
weight_decay_w = 0.0005
[imnet_pool2]
type = maxpool
load_key = imagenet
poolsize = (3,3)
poolstride = (2,2)4、細節方面:除了網路的最後一層輸出層之外,其它的啟用函式都是採用Relu函式。因為最後一層是線性迴歸問題,因此最後一層的啟用函式應該是線性函式。在全連線層layer6,採用Dropout。
5、引數初始化:引數初始化,採用遷移學習的思想,直接把Alexnet的網路訓練好的引數的前面幾層拿過來,進行fine-tuning。文章提到,採用fine-tuning的方法,效果會比較好。通過閱讀原始碼可以判斷,paper除了全連線層之外,粗網路卷積層的引數都是利用Alexnet進行fine-tuning。
四、精細化網路結構-Fine scale Network
精網路的結構,採用的是全連線卷積神經網路,也就是不存在全連線層,這個如果搞過FCN語義分割的,應該會比較明白。這個網路包含了三個卷積層。
通過上面粗網路的深度值預測,我們得到的深度圖是比較模糊的,基本上沒有什麼邊緣資訊,接著接著我們需要精細化,使得我們的深度預測圖與影象的邊緣等資訊相吻合,因為一個物體的邊緣,也就是相當於深度值發生突變的地方,因此我們預測出來的深度值影象也應該是有邊緣的。從粗到精的思想就像文獻《Deep Convolutional Network Cascade for Facial Point Detection》,從粗估計到精預測的過程一樣,如果你之前已經搞過coarse to refine 相關的網路的話,那麼學習這篇文獻會比較容易。為了簡單起見,我這邊把本層網路稱之為:精網路。精網路的結構如下:
1、輸入層:304*228 大小的彩色圖片
2、第一層:輸入原始圖片,第一層包含卷積、RELU、池化。卷積核大小為9*9,卷積跨步選擇2,特徵圖個數選擇64個(這個文獻是不是中的圖片是不是錯了,好像標的是63),即:filter_shape = (64,3,9,9)。最大池化採用重疊池化取樣size=(3,3),跨步選擇2,即poolsize = (3,3),poolstride = (2,2)。這一層主要用於提取邊緣特徵。因為我們通過粗網路的輸出可以看出,基本上沒有了邊緣資訊,因此我們需要利用精網路,重構這些邊緣資訊。本層網路的相關引數:
[conv_s2_1]
type = conv
load_key = fine_stack
filter_shape = (64,3,9,9)
stride = 2
init_w = lambda shp: 0.001*np.random.randn(*shp)
init_b = 0.0
conv_mode = valid
weight_decay_w = 0.0001
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001
[pool_s2_1]
type = maxpool
poolsize = (3,3)
poolstride = (2,2)經過卷積層,我們可以得到大小為(110*148)的圖片,然後在進行pooling,就可以得到55*74的圖片了。這樣經過這一層,我們就得到了與粗網路的輸出大小相同的圖片了。
3、第二層:這一層的輸入,除了第一層得到的特徵圖外,同時還額外添加了粗網路的輸出圖(作為特徵圖,加入網路輸入)。
網路細節基本和粗網路相同,這裡需要注意的是,我們訓練網路的時候,是先把粗網路訓練好了,然後在進行訓練精網路,精網路訓練過程中,粗網路的引數是不用迭代更新的。DCNN的思想都是這樣的,如果你有看了我的另外一篇關於特徵點定位的博文DCNN,就知道怎麼訓練了。
還有我們這一層的輸入圖片的大小,已經和輸出層所要求的大小一樣了,因此後面卷積的時候,卷積要保證圖片大小還是一樣的。
[conv_s2_2]
type = conv
load_key = fine_stack
filter_shape = (64,64,5,5)
init_w = lambda shp: 0.01*np.random.randn(*shp)
init_b = 0.0
conv_mode = same
weight_decay_w = 0.0001
learning_rate_scale_w = 0.01
learning_rate_scale_b = 0.014、第三層:也就是連線到輸出層去
[conv_s2_3]
type = conv
load_key = fine_stack
filter_shape = (64,1,5,5)
transpose = True
init_w = lambda shp: 0.01*np.random.randn(*shp)
init_b = 0.0
conv_mode = same
weight_decay_w = 0.0001
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001五、尺度不變損失函式
這個是文獻的主要創新點之一,主要是提出了尺度不變的均方誤差函式:
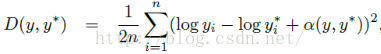
其中y和y*就是我們的圖片標註資料和預測資料了,本文指的是每個畫素點的實際的深度值和預測的深度值。α的計算公式如下:
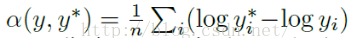
根據上面定義的損失函式,paper訓練過程中採用如下的損失函式:

其中引數λ取值為0.5。具體的原始碼如下:
#定義損失函式 縮放不變損失函式,pred預測值,y0標準值、m0為mask(為0表示無效點,為1表示有效點)
def define_cost(self, pred, y0, m0):
bsize = self.bsize
npix = int(np.prod(test_shape(y0)[1:]))
y0_target = y0.reshape((self.bsize, npix))
y0_mask = m0.reshape((self.bsize, npix))
pred = pred.reshape((self.bsize, npix))
#因為在mask中,所有的無效的畫素點的值都為0,所以p、t中對應的畫素點的值也為0,這樣我們的損失函式,這些畫素點的值也為0,對引數不起更新作用
p = pred * y0_mask
t = y0_target * y0_mask
d = (p - t)
nvalid_pix = T.sum(y0_mask, axis=1)#這個表示深度值有效的畫素點
#文獻中公式4 ,引數λ取值為0.5.公式採用的是簡化為(n×sum(d^2)-λ*(sum(d))^2)/(n^2)
depth_cost = (T.sum(nvalid_pix * T.sum(d**2, axis=1))
- 0.5*T.sum(T.sum(d, axis=1)**2)) \
/ T.maximum(T.sum(nvalid_pix**2), 1)
return depth_cost六、資料擴充
1、縮放:縮放比例s取(1,1.5),因為縮放深度值並不是不變的,所以文獻採用把深度值對應的也除以比例s。(這一點我有點不明白,難道一張圖片拍好了,我們把它放大s倍,那麼會相當於攝像頭往物體靠近了s倍進行拍照嗎?這樣解釋的,讓我有點想不通)。
2、旋轉資料擴充,這個比較容易
3、資料加噪擴充:主要是把圖片的每個畫素點的值,乘以一個(0.8,1.2)之間的隨機數。
4、映象資料擴充,用0.5的概率,對資料進行翻轉。
5、隨機裁剪擴充,跟Alexnet一樣。
在測試階段,採用中心裁剪的方式,和Alexnet的各個角落裁剪後平均有所不同。
七、訓練相關細節
這邊我只講解NYU資料集上的訓練。NYU訓練資料可以自己網上下載,NYU原始的資料中,每張圖片的每個畫素點label、depth值,其中label是物體標籤,主要用於影象分割,後面paper的作者也發表了一篇關於語意分割、法矢估計的文獻:《Predicting Depth, Surface Normals and Semantic Labels》。
NYU原始的訓練資料有個特點,就是圖片並不是每個畫素點都有depth值,這個可能是因為裝置採集深度值的時候,會有缺失的畫素點。首先NYU資料是640*480的圖片,depth也是640*480,因為每個畫素點,對應一個深度值嘛,可是這些深度值,有的畫素點是無效的,有效和無效的畫素點我們可以用一個mask表示。那麼我們如何進行訓練呢?
我們知道網路採用的是對320*240的圖片,進行random crop的,因此首先我們需要把image、depth、mask都由640*480縮小到320*240。這邊需要注意的是這裡的縮小,是採用直接下采樣的方法,而不是採用線性插值等方法。因為我們需要保證圖片每個畫素點和depth、mask都是對應的,而不是採用插值的方法,如果採用插值,那麼我們的mask就不再是mask了,這個小細節一開始困擾了我好久。還有需要再提醒一下,320*240不是網路的輸入大小,我們還要採用random crop,把它裁剪成304*228,這個才是網路的輸入。
另一方面就是depth的問題,我們知道我們輸出的depth的大小是74*55。而網路輸入資料image、depth、mask的大小是304*228,因此我們在構造損失函式,需要把標註資料depth、mask又採用直接下采樣的方法縮小到74*55(下采樣比例為4),這樣才能與網路的輸出大小相同,構造損失函式。相關原始碼如下:
y0 = depths#深度值
m0 = masks#mask
#圖片採用的是直接下采樣,而不是用雙線性插值進行插值得到訓練的depths,下采樣的比例是4
m0 = m0[:,1::4,1::4]
y0 = y0[:,1::4,1::4]個人總結:這篇文獻的深度估計,文獻上面可以說是深度學習領域崛起的一個牛逼應用,相比於傳統的方法精度提高了很多。不過即便如此,精度離我們要商用的地步還是有一段的距離要走。從這篇文獻我們主要學習到了兩個知識點:1、多尺度CNN模型 。2、標註資料部分缺失的情況下,網路的訓練,這個文獻給了最大的啟發就是:在kaggle競賽上面有個人臉特徵點定位,但是有的圖片的標註資料,是部分缺失的,這個時候我們就可以借用這篇文獻的訓練思路,採用mask的方法。3、文獻提出了Scale-Invariant損失函式,也是文獻的一大創新點。
參考文獻:
1、《Depth Map Prediction from a Single Image using a Multi-Scale Deep Network》
2、《Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture》
4、《Make3d: Learning 3-d scene structure from a single still image》
**********************作者:hjimce 時間:2016.1.23 聯絡QQ:1393852684 地址:http://blog.csdn.net/hjimce 原創文章,轉載請保留本行資訊************