
[work] shell中的多程序併發
根據我個人的理解, 所謂的多程序 只不過是將多個任務放到後臺執行而已,很多人都用到過,所以現在講的主要是控制,而不是實現。
先看一個小shell: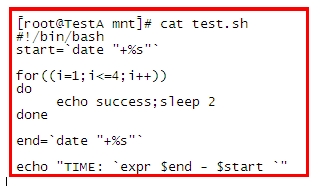
看執行結果:
很明顯是8s
=============================
這種不佔處理器卻有很耗時的程序,我們可以通過一種後臺執行的方式
來達到節約時間的目的。看如下改進: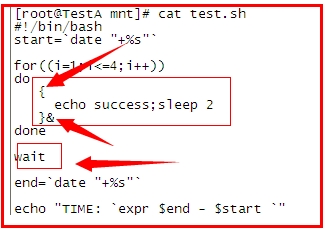
用“{}”將主執行程式變為一個塊,用&放入後臺,四次執行全部放入後臺後,我們
需要用一個wait指令,等待所有後臺程序執行結束,
不然 系統是不會等待的,直接繼續執行後續指令,知道整個程式結束。
看結果: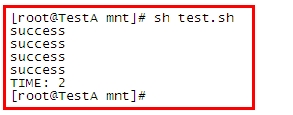
可以看到,時間已經大大縮短了!
============================
以上實驗雖然達到了多執行緒併發的目的,但有一個缺陷,不能控制
執行在後臺的程序數。
為了控制程序,我們引入了管道 和檔案操作符。
無名管道: 就是我們經常使用的 例如: cat text | grep "abc"
那個“|”就是管道,只不過是無名的,可以直接作為兩個程序的資料通道
有名管道: mkfilo 可以建立一個管道檔案 ,例如: mkfifo fifo_file
管道有一個特點,如果管道中沒有資料,那麼取管道資料的操作就會停滯,直到
管道內進入資料,然後讀出後才會終止這一操作,同理,寫入管道的操作
如果沒有讀取操作,這一個動作也會停滯。

當我們試圖用echo想管道檔案中寫入資料時,由於沒有任何程序在對它做讀取操作,所以
它會一直停留在那裡等待讀取操作,此時我們在另一終端上用cat指令做讀取操作

你會發現讀取操作一旦執行,寫入操作就可以順利完成了,同理,先做讀取操作也是一樣的:

由於沒有管道內沒有資料,所以讀取操作一直滯留在那裡等待寫入的資料

一旦有了寫入的資料,讀取操作立刻順利完成
以上實驗,看以看到,僅僅一個管道檔案似乎很難實現 我們的目的(控制後臺執行緒數),
所以 接下來介紹 檔案操作符,這裡只做簡單的介紹,如果不熟悉的可以自行查閱資料。
系統執行起始,就相應裝置自動繫結到了 三個檔案操作符 分別為 0 1 2 對應 stdin ,stdout, stderr 。
在 /proc/self/fd 中 可以看到 這三個三個對應檔案
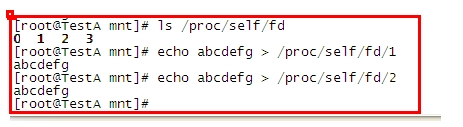
輸出到這三個檔案的內容都會顯示出來。只是因為顯示器作為最常用的輸出裝置而被繫結。
我們可以exec 指令自行定義、繫結檔案操作符
檔案操作符一般從3-(n-1)都可以隨便使用
此處的n 為 ulimit -n 的定義值得
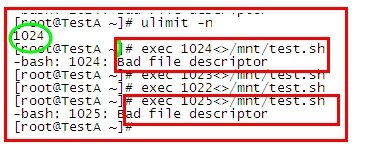
可以看到 我的 n值為1024 ,所以檔案操作符只能使用 0-1023,可自行定義的 就只能是 3-1023 了。
直接上程式碼,然後根據程式碼分析每行程式碼的含義:
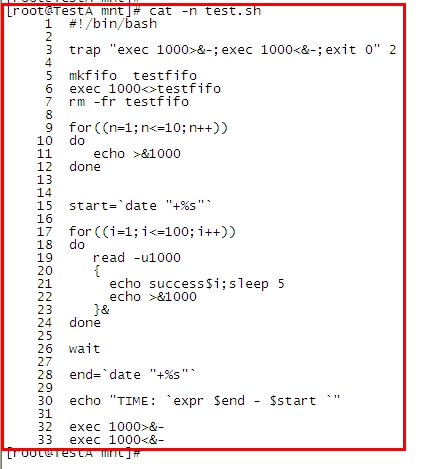
第3行: 接受訊號 2 (ctrl +C)做的操作
exec 1000>&-和exec 1000<&- 是關閉fd1000的意思
我們生成做繫結時 可以用 exec 1000<>testfifo 來實現,但關閉時必須分開來寫
> 讀的繫結,< 標識寫的繫結 <> 則標識 對檔案描述符 1000的所有操作等同於對管道檔案
testfifo的操作。
第5-7行: 分別為 建立管道檔案,檔案操作符繫結,刪除管道檔案
可能會有疑問,為什麼不能直接使用管道檔案呢?
事實上,這並非多此一舉,剛才已經說明了管道檔案的一個重要特性了,那就是讀寫必須同時存在
缺少某一種操作,另一種操作就是滯留,而繫結檔案操作符 正好解決了這個問題。
(至於為什麼,我還沒研究明白,有知道的 還請告知,謝謝)
第9-12 行: 對檔案操作符進行寫入操作。 通過一個for迴圈寫入10個空行,這個10就是我們要定義的後臺執行緒數量。
為什麼寫入空行而不是10個字元呢 ?
這是因為,管道檔案的讀取 是以行為單位的。

當我們試圖用 read 讀取管道中的一個字元時,結果是不成功的,而剛才我們已經證實使用cat是可以讀取的。
第17-24行: 這裡假定我們有100個任務,我們要實現的時 ,保證後臺只有10個程序在同步執行 。
read -u1000 的作用是:讀取一次管道中的一行,在這兒就是讀取一個空行。
減少操作附中的一個空行之後,執行一次任務(當然是放到後臺執行),需要注意的是,這個任務在後臺執行結束以後
會向檔案操作符中寫入一個空行,這就是重點所在,如果我們不在某種情況某種時刻向操作符中寫入空行,那麼結果就是:
在後臺放入10個任務之後,由於操作符中沒有可讀取的空行,導致 read -u1000 這兒 始終停頓。
後邊的 就不用解釋了,貼下執行結果:

每次的停頓中都能看到 只有10個程序在執行
一共耗時50s
一共100個任務,每次10個 ,每個5s 正好50s
上邊的結果圖之所以這麼有規律,這是因為我們所執行的100個任務耗時都是相同的,
比如,系統將第一批10個任務放入後臺的過程所消耗的時間 幾乎可以忽略不計,也就是說
這10個任務幾乎可以任務是同時執行,當然也就可以認為是同時結束了,而按照剛才的分析,
一個任務結束時就會向檔案描述符寫入空行,既然是同時結束的,那麼肯定是同時寫入的空行,
所以下一批任務又幾乎同時執行,如此迴圈下去的。
實際應用時,肯定不是這個樣子的,比如,第一個放到後臺執行的任務,是最耗時間的,
那他肯定就會是最後一個執行完畢。
所以,實際上來說,只要有一個任務完成,那麼下一個任務就可以被放到後臺併發執行了。
哥,read -n 1 fifofile 不是讀管道檔案中的一行吧?
原始碼:
[[email protected] shelltest]# more mulpro.sh
#!/bin/bash
trap "exec 1000>&-; exec 1000<&-;exit 0" 2
mkfifo mulfifo
exec 1000<>mulfifo
rm -rf mulfifo
for ((n=1;n<=10;n++))
do
echo >&1000
done
start=`date +%s`
for ((i=1;i<=100;i++))
do
read -u1000
{
echo success$i;sleep 3
echo >&1000
}&
done
wait
end=`date +%s`
echo "Time :`expr $end - $start`"
exec 1000>&-
exec 1000<&-
[[email protected] shelltest]#
轉自:http://bbs.51cto.com/viewthread.php?tid=1104907&pid=5756676&page=1&extra=#pid5756676
--多程序的另一種實現
這兩天,因為工作地需要做一些的多程序的工作,看了網上的一些例子,多是通過管道檔案的方式來實現的,後來想想也不用這麼麻煩...
下面是一個多程序後臺掛起的一個簡單的例子,原理大概如下,先在後臺掛起一定數量的程序,當正在執行的程序數超過一定數值後,暫停任務分配,睡眠一定時間,若後臺程序數小於你設定的數值後,繼續任務分配。
其實是不是也很簡單...
################ change the var bill to fix #########################################
################ change the pro to multi process ####################################
################ yijy 2009.4.26 modified ############################################
InDir="/in"
OutDir="/out"
CurCmd="varfixf"
du ${OutDir}
rm ${OutDir}/*
du ${OutDir}
totalInDir=`find ${InDir} -type f | wc -l`
curDir=`pwd`
if [ ! ${totalInDir} ]
then
echo "APP:MSG:There is no file in the in dir ... "
exit
else
echo "APP:MSG:Start to convert ... "
currentBinNum=0
find ${InDir} -type f | while read file
do
currentBinNum=`ps -ef | grep ${FEDX_HOME} | grep ${CurCmd} | grep ${curDir} |wc -l` /*統計後臺掛起的數目*/
echo "APP:MSG:Backgroud num : "${currentBinNum}
while [ ${currentBinNum} -gt 30 ] /*如果掛起數目大於30,這個掛起數值可以自定義,程式暫停,睡眠,睡眠之後繼續檢測後臺掛起的數目*/
do
sleep 1
echo 'sleeping ...'
currentBinNum=`ps -ef | grep ${FEDX_HOME} | grep ${CurCmd} | grep ${curDir} |wc -l`
done
filename=`basename $file`
varfixf ${curDir}/${InDir}/${filename} ${curDir}/${OutDir}/${filename} > /dev/null &
done
echo "APP:MSG:Convert over ... "
fi
------核心程式碼如下
while read line
do
currentBinNum=`ps -ef | grep command |wc -l`
while [ ${currentBinNum} -gt 30 ]
do
sleep 1
echo 'sleeping ...'
currentBinNum=`ps -ef | command |wc -l`
done
commamd &
done<infile
ps -ef|grep for|grep -v grep