
python爬取小說(三)資料儲存
阿新 • • 發佈:2019-01-01
由於時間關係,我們先把每章的內容儲存到資料庫。
需要用到sqlite,
接著上一篇,在原基礎上修改程式碼如下:
# -*- coding: utf-8 -*-
import urllib.request
import bs4
import re
import sqlite3
import time
print ('連線資料庫……')
cx = sqlite3.connect('PaChong.db')
# #在該資料庫下建立表
# 建立書籍基本資訊表
cx.execute('''CREATE TABLE book_info(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title verchar(128) not null,
img verchar(512) null,
auther verchar(64) null,
type verchar(128) null,
status verchar(64) null,
num int null,
updatatime datetime null,
newchapter verchar(512) null,
authsummery verchar(1024) null,
summery verchar(1024) null,
notipurl verchar(512) null);
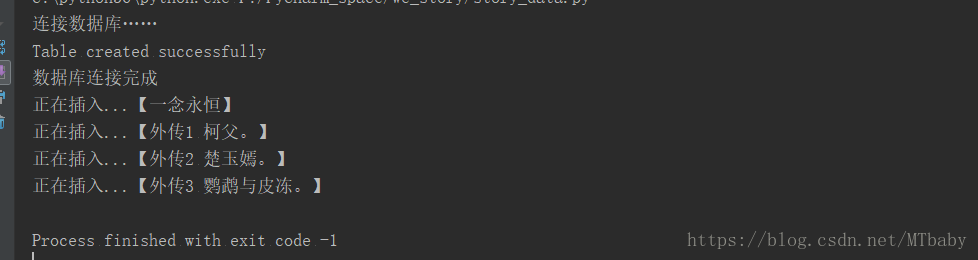
''' 結果展示:
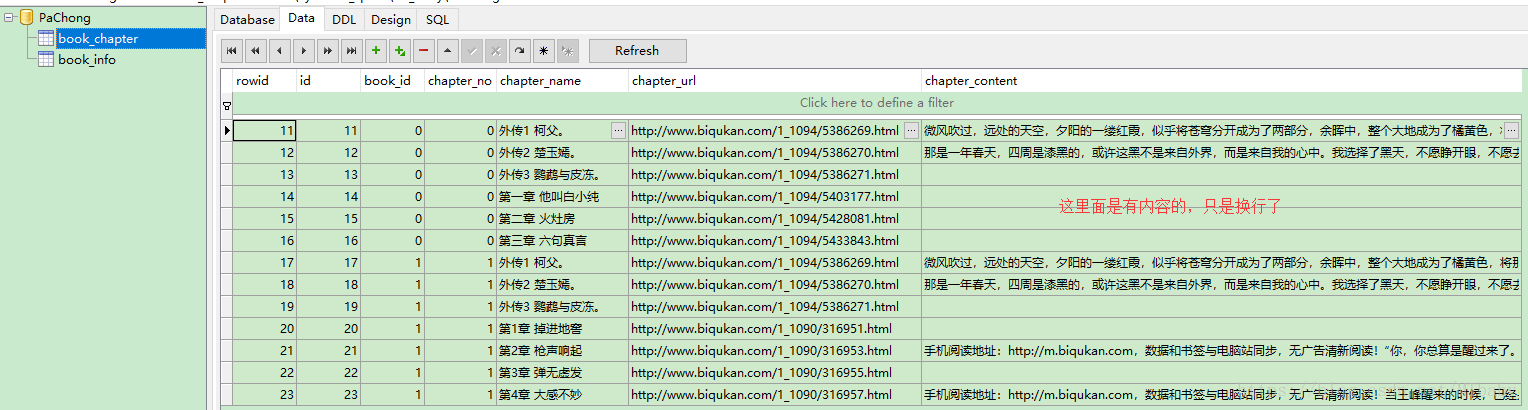
資料庫展示:

如果你想爬去多本書的資訊和內容,那就組裝一下url
if __name__ == '__main__':
for i in range(1090,1100):
url = 'http://www.biqukan.com/1_' + str(i) + '/'
insert_baseinfo(url)
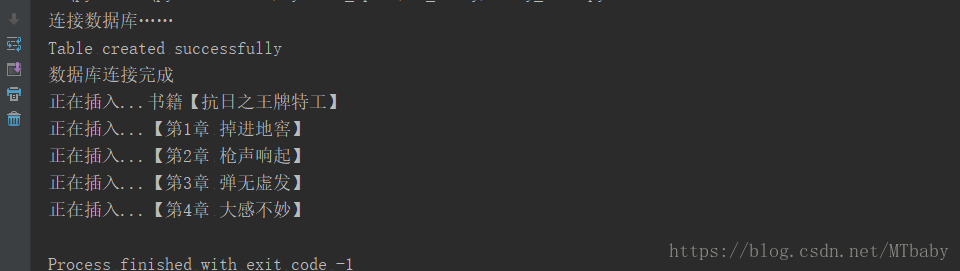
get_book(url)結果如下:
下一篇會將資料在前端展示。