
工作中的一些sql小結(postgresql)
工作中的遇到的一些postgresql總結。
一、子查詢
子查詢中,使用到的子查詢關鍵字 exists 最多。基本格式如下:
SELECT...
FROM tablename
WHERE ... and exists (
SELECT id FROM tablename where ...)
1.1 應用場景
在CRM系統中,批量刪除排班,但要求這些排班沒有被使用。
-- 先將符合條件的排班都查詢出來。
SELECT aw.id
FROM pmm_arrangework aw
WHERE date >= CURRENT_DATE
AND 一般不推薦使用NOT IN 。NOT IN 遇到 NULL 可能不安全。
二、批量表操作
企業中,常常需要做資料抽取工作,然後定時進行排程。這個時候,批量插入表,批量更新表就十分常見。
- truncate table 表名
如果刪除整個表,使用truncate比delete更好。(序列重置、速度、事務等角度對比)
truncate table pmm_
但,如果只刪除部分,則必須使用delete
DELETE FROM pmm_statistic WHERE reportmonth = '2018-11'
- 批量插入資料
--INSERT INTO TABLENAME(...) SELECT ...
INSERT INTO pmm_statistic (userid,reportmonth,saleareaid,plandatenum,actualdatenum,planworkhours,actualhours,latenum,
latehours,leaveearlynum,leaveearlyhours,notsignnum,nianjia,tiaoxiujia, - 批量更新
-- 業務場景:安人員id分組統計這個月這個月的應出勤工時。然後進行批量更新。
UPDATE pmm_statistic SET planworkhours = v.planworkhours
FROM (
SELECT userinfoid, sum(planworkhours) AS planworkhours
FROM pmm_signresult s
WHERE s.workdate >= thismonthbegin and s.workdate < nextmonthbegin
AND s.platstatus = 1
GROUP BY s.userinfoid
)v
WHERE v.userinfoid = pmm_statistic.userid AND pmm_statistic.reportmonth = thismonth;
三、case when 應用
- case when
-- 大致格式
case when …… THEN …… when …… THEN …… ELSE …… END AS 欄位名稱
case when 常常用於判斷型別,通過不同的型別輸出不同的值。例如:通過case when 判斷上班的打卡型別。是簽到還是簽退;訂單的型別等等。
SELECT s.collectdate,sd.productname,
CASE WHEN sd.approvalstatus = 1 THEN '待確認' ELSE '已確認' END AS statusname
FROM pmm_salesreport s
- 和其他聚合函式一起使用
業務場景:按照人進行分組;彙總每個人各種請假型別的總時間,然後批量更新統計表中
案例一:
UPDATE bi_pmm_kq_statistic SET nianjia = v.nianjia,tiaoxiujia=v.tiaoxiujia,bingjia=v.bingjia,
shijia=v.shijia,hunjia=v.hunjia,chanjia=v.chanjia,peichanjia=v.peichanjia
FROM(SELECT
SUM (CASE WHEN leavetype = '1' THEN timespan ELSE 0 END ) AS nianjia,
SUM (CASE WHEN leavetype = '2' THEN timespan ELSE 0 END ) AS tiaoxiujia,
SUM (CASE WHEN leavetype = '3' THEN timespan ELSE 0 END ) AS bingjia,
SUM (CASE WHEN leavetype = '4' THEN timespan ELSE 0 END ) AS shijia,
SUM (CASE WHEN leavetype = '5' THEN timespan ELSE 0 END ) AS hunjia,
SUM (CASE WHEN leavetype = '6' THEN timespan ELSE 0 END ) AS chanjia,
SUM (CASE WHEN leavetype = '7' THEN timespan ELSE 0 END ) AS peichanjia,
userinfoid
FROM pmm_leave l
WHERE starttime >= thismonthbegin AND endtime < nextmonthbegin
AND l.approvalstatus = '2'
GROUP BY userinfoid
)v
WHERE v.userinfoid = pmm_statistic.userid AND pmm_statistic.reportmonth = thismonth;
案例二:
-- 多個條件判斷
SELECT
CASE WHEN (cc.status = 1 AND cp.type = 1) THEN 0
WHEN (cc.status IS NULL AND cp.type = 1) THEN NULL
ELSE 1 END AS flag
FROM plan AS cp
LEFT JOIN customer AS cc ON cp.id = cc.coid
case when在很多情景下都是比較好用的。
案例三:
在案例一中,其實思想就是行轉列的操作。在sqlserver 中有透視函式(PIVOT); 在pg中有crosstab ;
案例描述:
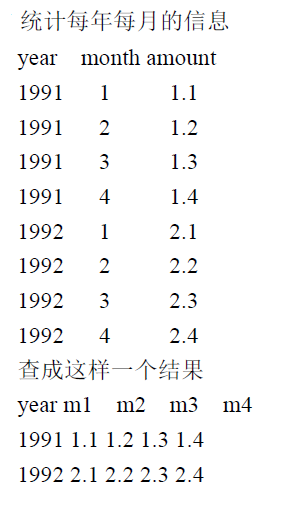
CREATE TABLE sales
(
year integer, -- 年
month integer, -- 月
counts integer -- 銷量
)
WITH (
OIDS=FALSE
);
ALTER TABLE sales
OWNER TO postgres;
COMMENT ON TABLE sales
IS '銷售報表';
COMMENT ON COLUMN sales.year IS '年';
COMMENT ON COLUMN sales.month IS '月';
COMMENT ON COLUMN sales.counts IS '銷量';
insert into sales values(1991,1,11),(1991,2,12),(1991,3,13),(1991,4,14),(1992,1,21),(1992,2,22),(1992,3,23),(1992,4,24);
-- 方式一:
select year AS 年,
sum(case when month = 1 THEN counts ELSE 0 END) AS 一月,
sum(case when month = 2 THEN counts ELSE 0 END) AS 二月,
sum(case when month = 3 THEN counts ELSE 0 END) AS 三月,
sum(case when month = 4 THEN counts ELSE 0 END) AS 四月
from sales
GROUP BY year
order by year ASC;
---方式二:
SELECT s.year AS 年,
(SELECT sum(t.counts) FROM sales AS t WHERE t.month = '1' AND s.year = t.year) AS 一月,
(SELECT sum(t.counts) FROM sales AS t WHERE t.month = '2' AND s.year = t.year) AS 二月,
(SELECT sum(t.counts) FROM sales AS t WHERE t.month = '3' AND s.year = t.year) AS 三月,
(SELECT sum(t.counts) FROM sales AS t WHERE t.month = '4' AND s.year = t.year) AS 四月
FROM sales AS s GROUP BY s.year ORDER BY s.year;
四、rank() over(partition by … order by …)
分組排序。取前多少條記錄。
業務場景: 一天有多個排班,每個排班都需要打簽到簽退卡;每次進入打卡頁面(多個排班,頁籤切換),每個排班,需要顯示簽到的第一次打卡,簽退的最後一次打卡。
每個排班的簽到簽退可以打卡多次。
思路:簽到型別分組;簽到簽退按時間升序、降序;然後獲取第一條資料。
SELECT * FROM(
SELECT userid,workplanid,signtype,recorddate,signdatetime,
rank() over(PARTITION BY signtype,workplanid ORDER BY signdatetime ASC) AS rownumber
FROM pmm_signrecord
WHERE recorddate = CURRENT_DATE
AND userid = 1001
AND signtype = 1
) r
WHERE rownumber = 1
SELECT * FROM(
SELECT userid,workplanid,signtype,recorddate,signdatetime,
rank() over(PARTITION BY signtype,workplanid ORDER BY signdatetime DESC) AS rownumber
FROM pmm_signrecord
WHERE recorddate = CURRENT_DATE
AND userid = 1001
AND signtype = 2
) r
WHERE rownumber = 1
開窗函式 over 和 group by的區別。開窗函式更便捷;group by 也可以做到相同的效果,但是group by 不方便的地方在於,select後的欄位必須出現在group by 後面或者需要使用聚合函式。如果要使用額外的欄位,常常需要再巢狀一個子查詢。
當然開窗函式還有更多的使用方法; 如分頁、排名等等。
五、 pg 函式(其他資料稱為:儲存過程)
SELECT from produrcename()– 呼叫函式
perform produrcename – 執行,可以在一個函式中呼叫另外一個函式
CREATE OR REPLACE FUNCTION 過程名(引數名 引數型別,…..)
RETURNS 返回值型別 as
$body$
--宣告變數
DECLARE
變數名變數型別
-- 例如:flag Boolean;
--變數賦值方式(變數名型別 :=值)
BEGIN
-- 主體內容
return 變數名;
END
$body$
LANGUAGE plpgsql;
注: 語法中有 replace 關鍵字,如果函式名已經存在,可能被覆蓋,所以建立時用create;如果需要修改則使用replace
在編寫函式時,常常需要列印一些欄位的值,這個時候可以使用下面語法:
--raise的語法為:
raise notice 'param is %',param;
六、PostgreSQL自動增加
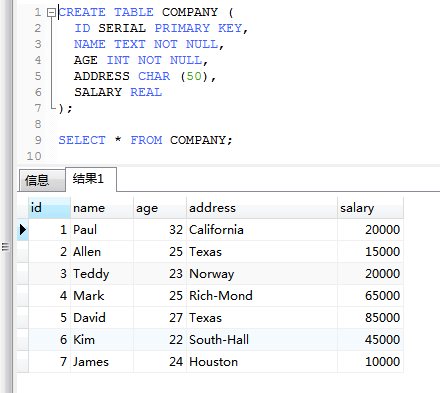
PostgreSQL擁有的資料型別smallserial,serial 和bigserial,這些都不是真正的型別,但僅僅是一個概念上的便利,為建立唯一識別符號列。這些都是相似到支援AUTO_INCREMENT屬性其他一些資料庫。
CREATE TABLE COMPANY (
ID SERIAL PRIMARY KEY,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (50),
SALARY REAL
);
關於postgresql中的資料型別,可以檢視這邊文章:https://www.cnblogs.com/kungfupanda/p/4478917.html。
其他
-
upset 處理衝突
插入資料時,可能會出現主鍵衝突等。當發生衝突事件時,需要採取補充措施。 -
資料抽樣
針對大量的資料,可能需要抽取隨機的幾條的資料,這個時候可以使用下面兩個函式:
system;bernoull
擴充套件
有興趣可以閱讀該文章 PostgreSQL 與 MySQL 相比,優勢何在?