
分解和合並:Java 也擅長輕鬆的並行程式設計!
作者:Julien Ponge
Java SE 7 提供的新分解/合併任務如何使編寫並行程式變得更輕鬆?
2011 年 7 月釋出
多核處理器現在已廣泛應用於伺服器、桌上型電腦和便攜機硬體。它們還擴充套件到到更小的裝置,如智慧電話和平板電腦。由於程序的執行緒可以在多個核心上並行執行,因此多核處理器為併發程式設計打開了一扇扇新的大門。為實現應用程式的最大效能,一項重要的技術就是將密集型任務拆分成可以並行執行的若干小塊,以便最大程度利用計算能力。
傳統上,處理併發(並行)程式設計一直很困難,因為您不得不處理執行緒同步和共享資料的問題。Groovy (GPar)、Scala 和 Clojure 社群的努力已經證明,人們對 Java 平臺上併發程式設計的語言級支援的興趣十分強烈。這些社群都嘗試提供全面的程式設計模型和高效的實現,以遮蔽與多執行緒和分散式應用程式相關的難點。但不應認為 Java 語言本身在這方面遜色。Java Platform, Standard Edition (Java SE) 5 及後來的 Java SE 6 引入了一組程式包,可以提供強大的併發構建塊。Java SE 7 通過新增並行支援進一步增強了這些構建塊。
下文首先簡單回顧了 Java 併發程式設計,從早期版本以來已經存在的低階機制開始。然後在介紹 Java SE 7 中由分解/合併框架提供的新增基本功能分解/合併任務之前,先介紹 java.util.concurrent 程式包新增的豐富基元。文中給出了這些新 API 的示例用法。最後,在結束之前對方法進行了討論。
下面,我們假定讀者擁有 Java SE 5 或 Java SE 6 程式設計背景。在此過程中,我們還將介紹 Java SE 7 一些實用的語言發展。
Java 併發程式設計
傳統執行緒
過去,Java 併發程式設計包括通過 java.lang.Thread 類和 java.lang.Runnable
Thread thread = new Thread() {
@Override public void run() {
System.out.println(">>> I am running in a separate thread!");
}
};
thread.start();
thread.join();
本示例中的程式碼所做的只是建立一個執行緒,該執行緒將一個字串列印到標準輸出流。主執行緒通過呼叫 join()
這樣直接操作執行緒對於簡單示例來說是不錯,但對於併發程式設計,這種程式碼很快就容易產生錯誤,尤其是當多個執行緒需要合作執行一個大型任務時。在這樣的情況下,需要協調其控制流。
例如,某個執行緒執行的完成可能依賴於其他執行緒執行完成。通常人們熟知的示例是生產者/使用者的例子,如果使用者的佇列已滿則生產者應等待使用者,當佇列為空時使用者應等待生產者。這一要求可通過共享狀態和條件佇列得到滿足,但您仍需要通過對共享狀態物件使用java.lang.Object.notify() 和 java.lang.Object.wait() 來使用同步,這很容易出錯。
最後,一個常見的問題是對大段程式碼甚至是整個方法使用同步和提供互斥。儘管此方法可產生執行緒安全的程式碼,但由於排除實際上過長所引起的有限並行度,該方法通常導致效能變差。
正如計算中經常發生的那樣,操作低階基元以實現複雜操作會開啟錯誤之門,因此開發人員應想辦法將複雜性封裝在高效的高階庫中。Java SE 5 正好為我們提供了這種能力。
java.util.concurrent 程式包的豐富基元
Java SE 5 引入了一個名為 java.util.concurrent 的程式包系列,Java SE 6 對其進行了進一步的增強。該程式包系列提供了以下併發程式設計基元、集合和特性:
-
執行器是對傳統執行緒的增強,因為它們是從執行緒池管理抽象而來的。它們執行與傳遞到執行緒的任務類似的任務(實際上,可封裝實現java.lang.Runnable 的例項)。有些實現提供了執行緒池和排程策略。而且,可以通過同步和非同步方式獲取執行結果。
-
執行緒安全佇列允許在併發任務之間傳遞資料。底層資料結構和併發行為有著豐富的實現,底層資料結構的實現包括陣列列表、連結列表或雙端佇列等,併發行為的實現包括阻塞、支援優先順序或延遲等。
-
細粒度的超時延遲規範,因為 java.util.concurrent 程式包中的大部分類均支援超時延遲。例如,如果任務在規定時間範圍內無法完成,執行器將中斷任務執行。
-
豐富的同步模式,不僅僅是 Java 中低階同步塊所提供的互斥。這些模式包括訊號或同步障礙等常用語法。
-
高效、併發的資料集合(對映、列表和集),通過使用寫時複製和細粒度鎖通常可在多執行緒上下文中產生出色的效能。
-
原子變數,可以使開發人員免於親自執行同步訪問。這些變數封裝了常用的基元型別,如整型或布林值,以及對其他物件的引用。
-
超出固有鎖所提供的鎖定/通知功能範圍的多種鎖,例如,支援重新進入、讀/寫鎖定、超時或基於輪詢的鎖定嘗試。
例如,考慮以下程式:
注意:由於 Java SE 7 引入的新的整數文字,可以在任意位置插入下劃線以提高可讀性(例如,1_000_000)。
import java.util.*;
import java.util.concurrent.*;
import static java.util.Arrays.asList;
public class Sums {
static class Sum implements Callable<Long> {
private final long from;
private final long to;
Sum(long from, long to) {
this.from = from;
this.to = to;
}
@Override
public Long call() {
long acc = 0;
for (long i = from; i <= to; i++) {
acc = acc + i;
}
return acc;
}
}
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(2);
List <Future<Long>> results = executor.invokeAll(asList(
new Sum(0, 10), new Sum(100, 1_000), new Sum(10_000, 1_000_000)
));
executor.shutdown();
for (Future<Long> result : results) {
System.out.println(result.get());
}
}
}
該示例程式利用執行器來計算多個長整型的和。內部 Sum 類實現了執行器用於計算結果的 Callable 介面,併發工作在 call() 方法內執行。java.util.concurrent.Executors 類提供了多種實用方法,如提供預配置執行器或將傳統 java.lang.Runnable 物件封裝到 Callable 例項中。與 Runnable 相比,使用 Callable 的優勢在於 Callable 能夠顯式返回一個值。
本示例使用一個執行器將工作分派給兩個執行緒。ExecutorService.invokeAll() 方法接受 Callable 例項的集合,並在返回之前等待所有這些例項完成。它會返回 Future 物件的列表,這些物件全都表示計算的“未來”結果。如果我們以非同步方式工作,就可以測試每個 Future 物件來檢查其對應的 Callable 是否已完成工作,並檢查其是否引發了異常,甚至可以取消其工作。相反,當使用普通傳統執行緒時,必須通過共享的可變布林值對取消邏輯進行編碼,並由於定期檢查此布林值而減緩程式碼的執行。因為 invokeAll() 容易產生阻塞,我們可以直接對 Future 例項進行遍歷並讀取其計算和。
還需注意,必須關閉執行器服務。如果未關閉,則在主方法退出時 Java 虛擬機器將不會退出,因為環境中還有活動執行緒。
分解/合併任務
概述
與傳統執行緒相比,執行器是一大進步,因為可以簡化併發任務的管理。有些型別的演算法要求任務建立子任務並與其他任務互相通訊以完成任務。這些是“分而治之”的演算法,也稱為“對映歸約”,類似函式語言中的齊名函式。其思路是將演算法要處理的資料空間拆分成較小的獨立塊。這是“對映”階段。一旦塊集處理完畢之後,就可以將部分結果收集起來形成最終結果。這是“歸約”階段。
一個簡單的示例是您希望計算一個大型整數陣列的總和(參見圖 1)。假定加法是可交換的,可以將陣列劃分為較小的部分,併發執行緒對這些部分計算部分和。然後將部分和相加,計算總和。因為對於此演算法,執行緒可以在陣列的不同區域上獨立執行,所以與對陣列中每個整數迴圈執行的單執行緒演算法相比,此演算法在多核架構上可以看到明顯的效能提升。
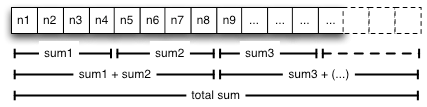
圖 1:整數陣列的部分和
使用執行器解決以上問題很簡單:將陣列分為 n 個可用物理處理單元,建立 Callable 例項以計算每個部分和,將部分和提交給管理 n 個執行緒的執行緒池的執行器,然後收集結果以計算最終和。
但對於其他型別的演算法和資料結構,執行計劃通常不會如此簡單。尤其是,標識“足夠小”可通過高效方式獨立處理的資料塊的“對映”階段預先不知道資料空間拓撲結構。對基於圖形和基於樹的資料結構來說尤為如此。在這些情況下,演算法應建立“各部分”的層次結構,在返回部分結果之前等待子任務完成。儘管類似圖 1 中的陣列並非最優,但可以使用多級併發部分和計算(例如,在雙核處理器上將陣列分為 4 個子任務)。
用於實現分而治之演算法的執行器的問題與建立子任務無關,因為 Callable 可自由向其執行器提交新的子任務,然後以同步或非同步方式等待其結果。問題出在並行上:當 Callable 等待另一個 Callable 的結果時,它被置於等待狀態,因此浪費了處理排隊等待執行的另一個Callable 的機會。
通過 Doug Lea 的努力,在 Java SE 7 中新增到 java.util.concurrent 程式包的分解/合併框架填補了這一空白。Java SE 5 和 Java SE 6 版本的 java.util.concurrent 幫助處理併發,Java SE 7 中另外增加了一些功能幫助處理並行。
用於支援並行的新增功能
核心新增功能是專用於執行實現 ForkJoinTask 例項的新的 ForkJoinPool 執行器。ForkJoinTask 物件支援建立子任務並等待子任務完成。通過這些明確的語義,執行器能夠通過在任務等待另一任務完成並且有待處理任務要執行時“竊取”作業,從而在其內部執行緒池中分派任務。
ForkJoinTask 物件有兩種特定方法:
-
fork() 方法允許計劃 ForkJoinTask 非同步執行。這允許從現有 ForkJoinTask 啟動新的 ForkJoinTask。
- 而 join() 方法允許 ForkJoinTask 等待另一個 ForkJoinTask 完成。
任務之間的合作通過 fork() 和 join() 來實現,如圖 2 所示。請注意,fork() 和 join() 方法名不應與其 POSIX 對應項(程序可通過它複製自身)混淆。其中,fork() 僅在 ForkJoinPool 中排程一個新任務,但不建立子
Java 虛擬機器。

圖 2:Fork 和 Join 任務之間的合作
有兩種型別的 ForkJoinTask 實現:
-
RecursiveAction 的例項表示不產生返回值的執行。
- 相反,RecursiveTask 的例項會產生返回值。
通常,優先選擇 RecursiveTask,因為大多數的分而治之演算法返回資料集的計算值。對於任務的執行,提供了不同的同步和非同步選項,從而有可能實現細緻的模式。
示例:計算某個單詞在文件中出現的次數
為了說明新的分解/合併框架的用法,我們舉一個簡單示例:計算某個單詞在一組文件中出現的次數。首先,分解/合併任務應作為“純”記憶體中演算法執行,其中不涉及 I/O 操作。同時,應儘可能避免任務之間通過共享狀態的通訊,因為這意味著可能必須執行鎖定。理想情況下,僅當一個任務分出另一個任務或一個任務併入另一個任務時,任務之間才進行通訊。
我們的應用程式執行在檔案目錄結構上,將每個檔案的內容載入到記憶體中。因此,需要以下類來表示該模型。文件表示為一系列行:
class Document {
private final List<String> lines;
Document(List<String> lines) {
this.lines = lines;
}
List<String> getLines() {
return this.lines;
}
static Document fromFile(File file) throws IOException {
List<String> lines = new LinkedList<>();
try(BufferedReader reader = new BufferedReader(new FileReader(file))) {
String line = reader.readLine();
while (line != null) {
lines.add(line);
line = reader.readLine();
}
}
return new Document(lines);
}
}
注意:如果您是初次接觸 Java SE7,fromFile() 方法有兩點會使您感到驚訝:
-
LinkedList 使用尖括號語法 (<>) 告知編譯器推斷通用型別引數。由於行是 List<String>,LinkedList<> 擴充套件為LinkedList<String>。使用尖括號運算子,對於那些能在編譯時輕鬆推斷的型別就不必再重複,從而使得通用型別的處理更輕鬆。
-
try 塊使用新的自動資源管理語言特性。在 try 塊的開頭可以使用實現 java.lang.AutoCloseable 的任何類。無論是否引發異常,當執行離開 try 塊時,在此宣告的任何資源都將正常關閉。在 Java SE 7 之前,正常關閉多個資源很快會變成一場巢狀if/try/catch/finally 塊的夢魘,這種巢狀塊通常很難正確編寫。
於是資料夾成為一個簡單的基於樹的結構:
class Folder {
private final List<Folder> subFolders;
private final List<Document> documents;
Folder(List<Folder> subFolders, List<Document> documents) {
this.subFolders = subFolders;
this.documents = documents;
}
List<Folder> getSubFolders() {
return this.subFolders;
}
List<Document> getDocuments() {
return this.documents;
}
static Folder fromDirectory(File dir) throws IOException {
List<Document> documents = new LinkedList<>();
List<Folder> subFolders = new LinkedList<>();
for (File entry : dir.listFiles()) {
if (entry.isDirectory()) {
subFolders.add(Folder.fromDirectory(entry));
} else {
documents.add(Document.fromFile(entry));
}
}
return new Folder(subFolders, documents);
}
}
現在我們可以開始實現主類:
import java.io.*;
import java.util.*;
import java.util.concurrent.*;
public class WordCounter {
String[] wordsIn(String line) {
return line.trim().split("(\\s|\\p{Punct})+");
}
Long occurrencesCount(Document document, String searchedWord) {
long count = 0;
for (String line : document.getLines()) {
for (String word : wordsIn(line)) {
if (searchedWord.equals(word)) {
count = count + 1;
}
}
}
return count;
}
}
occurrencesCount 方法利用 wordsIn 方法返回某個單詞在文件中出現的次數,wordsIn 方法在一行中生成該單詞的陣列。為此,該方法基於空格和標點字元對行進行拆分。
我們將實現兩種型別的分解/合併任務。直觀地說,一個資料夾中某個單詞出現的次數是該單詞在每個子資料夾和文件中出現的次數的總和。因此,我們將有一個任務用於計算文件中出現的次數,還有一個任務用於計算資料夾中出現的次數。後一型別分出子任務,然後將子任務合併以收集這些子任務的結果。
任務相關性易於掌握,因為它直接對映底層文件或資料夾樹結構,如圖 3 中所示。分解/合併框架通過確保可以在資料夾任務等待 join() 操作時執行一個待處理文件或資料夾的字數計算任務來使並行最大化。

圖 3:分解/合併字數計算任務
首先介紹 DocumentSearchTask,它計算某個單詞在文件中出現的次數:
class DocumentSearchTask extends RecursiveTask<Long> {
private final Document document;
private final String searchedWord;
DocumentSearchTask(Document document, String searchedWord) {
super();
this.document = document;
this.searchedWord = searchedWord;
}
@Override
protected Long compute() {
return occurrencesCount(document, searchedWord);
}
}
因為我們的任務產生值,這些任務擴充套件了 RecursiveTask 並接受 Long 作為通用型別,因為出現的次數將由一個 long 型整數表示。compute() 方法是所有 RecursiveTask 的核心。此處,它只是委託上述 occurrencesCount() 方法。現在我們可以處理FolderSearchTask 的實現,該任務執行在樹結構的資料夾元素上:
class FolderSearchTask extends RecursiveTask<Long> {
private final Folder folder;
private final String searchedWord;
FolderSearchTask(Folder folder, String searchedWord) {
super();
this.folder = folder;
this.searchedWord = searchedWord;
}
@Override
protected Long compute() {
long count = 0L;
List<RecursiveTask<Long>> forks = new LinkedList<>();
for (Folder subFolder : folder.getSubFolders()) {
FolderSearchTask task = new FolderSearchTask(subFolder, searchedWord);
forks.add(task);
task.fork();
}
for (Document document : folder.getDocuments()) {
DocumentSearchTask task = new DocumentSearchTask(document, searchedWord);
forks.add(task);
task.fork();
}
for (RecursiveTask<Long> task : forks) {
count = count + task.join();
}
return count;
}
}
在該任務中,compute() 方法的實現只是為已通過其建構函式傳遞的每個資料夾元素分解文件和資料夾任務。然後將合併所有這些任務以計算其部分和並返回該部分和。
現在我們只差一種方法來啟動分解/合併框架上的字數計算操作,以及一個分解/合併池執行器:
private final ForkJoinPool forkJoinPool = new ForkJoinPool();
Long countOccurrencesInParallel(Folder folder, String searchedWord) {
return forkJoinPool.invoke(new FolderSearchTask(folder, searchedWord));
}
初始 FolderSearchTask 將啟動所有這些操作。ForkJoinPool 的 invoke() 方法允許等待計算完成。在上面的例子中,
ForkJoinPool 是通過其空建構函式來使用的。並行度將與可用的硬體處理單元的數目相匹配(例如,在具有雙核處理器的計算機上並行度將為 2)。
現在我們可以編寫一個 main() 方法,該方法從命令列引數接受要在其上執行的資料夾以及要搜尋的字:
public static void main(String[] args) throws IOException {
WordCounter wordCounter = new WordCounter();
Folder folder = Folder.fromDirectory(new File(args[0]));
System.out.println(wordCounter.countOccurrencesOnSingleThread(folder, args[1]));
}
該示例的完整原始碼還包括此演算法更傳統的基於遞迴的實現,該實現工作在單執行緒上:
Long countOccurrencesOnSingleThread(Folder folder, String searchedWord) {
long count = 0;
for (Folder subFolder : folder.getSubFolders()) {
count = count + countOccurrencesOnSingleThread(subFolder, searchedWord);
}
for (Document document : folder.getDocuments()) {
count = count + occurrencesCount(document, searchedWord);
}
return count;
}
討論
在 Oracle 的 Sun Fire T2000 伺服器上進行了一次非正式測試,其中可以指定 Java 虛擬機器可用的核心數。同時運行了上例的分解/合併和單執行緒形式以找出 import 在 JDK 原始碼檔案中出現的次數。
多次運行了這些變化形式以確保 Java 虛擬機器熱點優化有足夠的時間完成部署。收集了 2 個、4 個、8 個和 12 個核心的最佳執行時間,然後計算了加速(即單執行緒上的時間/分解-合併上的時間之比)。結果反映在圖 4 和表 1 中。
正如您看到的,只需極少的努力即可在核心數上獲得近乎線性的加速,因為分解/合併框架會負責最大化並行度。
表 1:非正式測試執行時間和加速
|
核心數 |
單執行緒執行時間 (ms) |
分解/合併執行時間 (ms) |
加速 |
|
2 |
18798 |
11026 |
1.704879376 |
|
4 |
19473 |
8329 |
2.337975747 |
|
8 |
18911 |
4208 |
4.494058935 |
|
12 |
19410 |
2876 |
6.748956885 |
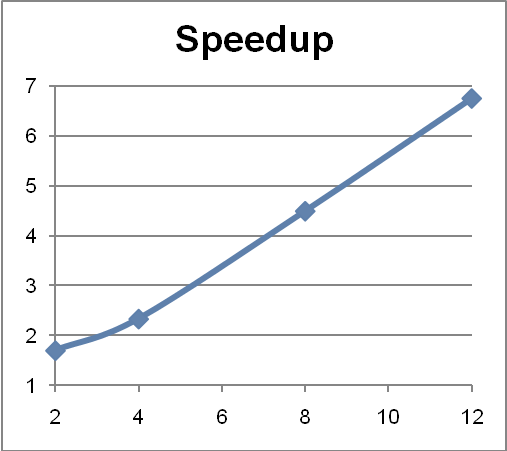
圖 4:加速(縱軸)與核心數(橫軸)有關
我們還可以對計算進行優化,分解任務使其在行級而不是在文件級執行。這將使併發任務有可能在同一文件的不同行上執行。但這有點牽強。實際上,分解/合併任務應執行“足夠”數量的計算以克服分解/合併執行緒池和任務管理的開銷。在行級工作將過於瑣碎,從而影響該方法的效率。
所包含的原始碼還提供基於對整數陣列執行合併-排序演算法的另一個分解/合併示例。這很有趣,因為它使用 RecursiveAction 來實現,該分解/合併任務對 join() 方法的呼叫不會產生值。相反,任務將共享可變狀態:要排序的陣列。同樣,實驗顯示核心數目上存在近乎線性的加速。
總結
本文討論了 Java 併發程式設計,重點強調 Java SE 7 為簡化並行程式編寫而提供的新的分解/合併任務。本文顯示,可以使用和組合豐富的基元來編寫可利用多核處理器的高效能程式,而完全無需處理執行緒和共享狀態同步的低階操作。本文在某單詞出現次數計算示例中闡釋了這些新 API 的使用,既引人注目又易於掌握。在非正式測試中,在核心數目上取得了近乎線性的加速。這些結果顯示分解/合併框架非常有用;因為我們既不必更改程式碼,也不必調整程式碼或 Java 虛擬機器,即可最大程度利用硬體核心。
您還可以將此技術應用於自己的問題和資料模型。只要您按無需 I/O 工作和鎖定的“分而治之”的方式重新編寫演算法,即可看到顯著的加速。
致謝
作者要感謝 Brian Goetz 和 Mike Duigou 對本文的早期版本提供了非常有用的反饋。還要感謝 Scott Oaks 和 Alexis Moussine-Pouchkine 幫助在適當的硬體上執行測試。
另請參見
Julien Ponge 是一位長期從事開源工作的技術高人。他建立了 IzPack 安裝程式框架,還參與了其他幾個專案,包括與 Sun Microsystems 合作的 GlassFish 應用伺服器。他擁有 UNSW Sydney 和 UBP Clermont-Ferrand 的計算科學博士學位,目前是 INSA de Lyon 計算機科學系的副教授,並且是 INRIA Amazones 團隊的研究人員。他在行業和學術界的兩棲身份給了他極大的動力來進一步推進這兩個領域的合作。