
[轉]Quorum JournalNode作用(hadoop1.x與hadoop2.x對比)
阿新 • • 發佈:2019-01-01
轉載自:
https://blog.csdn.net/bocai8058/article/details/78843608
致謝,如轉載請附上原文出處.
文章目錄
概述
HA(High Available),高可用性叢集,是保證業務連續性的有效解決方案,一般有兩個或兩個以上的節點,且分為活動節點及備用節點。兩個NameNode為了資料同步,會通過一組稱作JournalNodes的獨立程序進行相互通訊。
-
當active狀態的NameNode的名稱空間有任何修改時,會告知大部分的JournalNodes程序。
-
standby狀態的NameNode有能力讀取JNs中的變更資訊,並且一直監控edit
log的變化,把變化應用於自己的名稱空間。standby可以確保在叢集出錯時,名稱空間狀態已經完全同步了。
hadoop 1.x與2.x針對性對比
| \ | hadoop 1.x | hadoop 2.x |
|---|---|---|
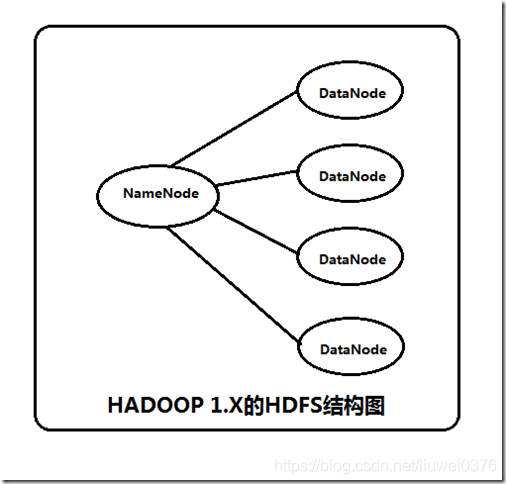
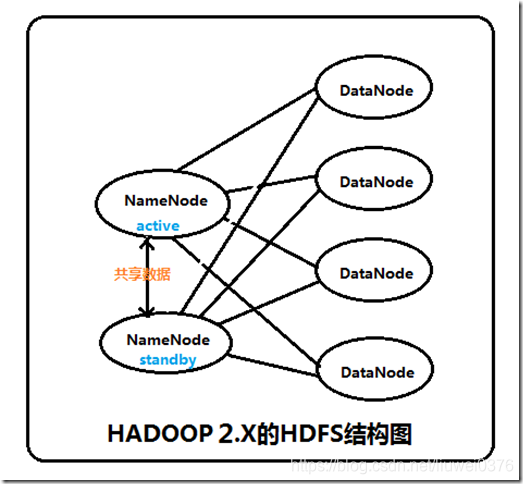
| 節點 | 只有1個NameNode。HDFS叢集的NN有單點故障問題。每個叢集只有一個單獨的NN,如果NN所在叢集宕機或者程序不可用,整個叢集也將不可用,直到NN被重啟或者指定到別的主機。(如左下圖) | 可以同時啟動2個NameNode。 HDFS HA特性通過提供選項,允許在同一個叢集以主動/被動方式,線上執行兩個冗餘的NN(一個處於工作狀態,另一個處於隨時待命狀態),解決了hadoop1.x單點故障問題。這樣,當一個NameNode所在的伺服器宕機時,可以在資料不丟失的情況下,手工或者自動切換到另一個NameNode提供服務。在一個典型的HA叢集中,每個NameNode是一臺獨立的伺服器。在任一時刻,只有一個NameNode處於active狀態,另一個處於standby狀態。其中,active狀態的NameNode負責所有的客戶端操作,standby狀態的NameNode處於從屬地位,維護著資料狀態,隨時準備切換 |
| 資料同步 | 將fsimage、edits檔案通過SecondaryNameNode合併。 | 多個NameNode之間共享資料,可以通過Network File System或者Quorum JournalNode(前者是通過linux共享的檔案系統,屬於作業系統的配置;後者是hadoop自身的東西,屬於軟體的配置),來保持資料狀態一致。(如右下圖) |
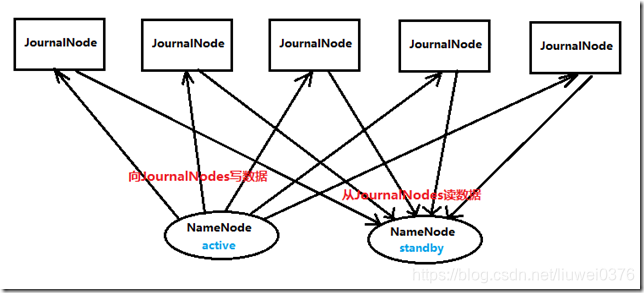
| 同步過程 | 從 NameNode上下載元資料資訊(fsimage、edits),然後利用SecondaryNameNode把二者合併,生成新的fsimage,在本地儲存,並將其推送到NameNode,替換舊的fsimage。即是editlogs。 | ①兩個NameNode為了資料同步,會通過一組稱作JournalNodes的獨立程序進行相互通訊。任何執行在活動NN的editlogs,將持久地記錄到大多數JN裡。備用NN能夠在這些JN裡讀取到editlogs,並且不斷的監控記錄的改變。當備用NN讀取到這些editlogs時,就把它們執行一遍。當發現故障恢復時,備份NN在確保從JN中讀取到所有editlogs後,就將自己提升為活動NN。這就確保了再發生故障恢復前名稱空間已完全同步。②為了提供快速的故障恢復,備用NN擁有最新的塊地址資訊也是非常重要的。為了實現這個要求,DN同時配置有兩個NN的地址,並且同時向兩者傳送塊地址資訊和心跳。③在同一時間裡,保證高可用叢集中只有一個活動NN是至關重要的。否則,兩個NN的狀態將很快出現不一致,資料有丟失的風險,或者其他錯誤的結果。為了確保這種屬性、防止所謂的腦裂場景(split-brain scenario),在同一時間裡,JN只允許一個NN寫editlogs。故障恢復期間,將成為活動節點的NN簡單的獲取寫editlogs的角色,這將有效的阻止其他NN繼續處於活動狀態,允許新活動節點安全的進行故障恢復。(如中下圖) |
硬體資源要求
為了部署HA(High Available)叢集,需要作如下準備:
- NameNode的要求:由HA的架構可知,存在兩個NameNode主機,一個為現役NameNode主機,一個為待機NameNode主機,二者的硬體配置應該相同,同時還要有執行JournalNodes的主機。
- JournalNode的要求:由於JournalNode守護程序是相對輕量級的,那麼這些守護程序可與其它Hadoop守護程序,如NameNode、JobTracker或者ResourceManager,執行在相同的主機上。由於edits日誌的改變必須寫入大多數(一半以上)JNs,所以至少存在3個JournalNodes守護程序,這樣系統能夠容忍單個主機故障。當然也可以執行多於3個JournalNodes,但為了增加系統能夠容忍的故障主機的數量,應該執行奇數個JNs。當執行N個JNs時,系統最多可以接受**(N-1)/2個主機故障並能繼續正常執行**。
參與的引用:
https://my.oschina.net/u/189445/blog/661561 |
http://hadoop.apache.org/docs/r2.5.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html | http://blog.csdn.net/skywalker_only/article/details/40078219