
Python效能優化指南
1、使用生成器和列表解析
一個普遍被忽略的記憶體優化是生成器的使用。生成器讓我們建立一個函式一次只返回一條記錄,而不是一次返回所有的記錄,如果你正在使用python2.x,這就是你為啥使用xrange替代range或者使用ifilter替代filter的原因。一個很好地例子就是建立一個很大的列表並將它們拼合在一起。
輸出:import timeit import random def generate(num): while num: yield random.randrange(10) num -= 1 def create_list(num): numbers = [] while num: numbers.append(random.randrange(10)) num -= 1 return numbers print(timeit.timeit("sum(generate(999))", setup="from __main__ import generate", number=1000)) print(timeit.timeit("sum(create_list(999))", setup="from __main__ import create_list", number=1000))
1.00842191191
0.933518458666
列表解析要比在迴圈中重新構建一個新的 list 更為高效,因此我們可以利用這一特性來提高執行的效率。
使用列表解析:from time import time t = time() list = ['a','b','is','python','jason','hello','hill','with','phone','test', 'dfdf','apple','pddf','ind','basic','none','baecr','var','bana','dd','wrd'] total=[] for i in range(1000000): for w in list: total.append(w) print "total run time:" print time()-t
for i in range(1000000):
a = [w for w in list]2、Ctypes的介紹
對於關鍵性的效能程式碼python本身也提供給我們一個API來呼叫C方法,主要通過
import timeit
from ctypes import cdll
def generate_c(num):
#Load standard C library
#libc = cdll.LoadLibrary("libc.so.6") #Linux
libc = cdll.msvcrt #Windows
while num:
yield libc.rand() % 10
num -= 1
print(timeit.timeit("sum(generate_c(999))", setup="from __main__ import generate_c", number=1000))0.404974439902
僅僅換成了c的隨機函式,執行時間減了大半!現在如果我告訴你我們還能做得更好,你信嗎?
3、Cython的介紹
Cython 是python的一個超集,允許我們呼叫C函式以及宣告變數來提高效能。嘗試使用之前我們需要先安裝Cython.
sudo pip install cythonCython 本質上是另一個不再開發的類似類庫Pyrex的分支,它將我們的類Python程式碼編譯成C庫,我們可以在一個python檔案中呼叫。對於你的python檔案使用.pyx字尾替代.py字尾,讓我們看一下使用Cython如何來執行我們的生成器程式碼。
#cython_generator.pyx
import random
def generate(num):
while num:
yield random.randrange(10)
num -= 1from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
setup(
cmdclass = {'build_ext': build_ext},
ext_modules = [Extension("generator", ["cython_generator.pyx"])]
)python setup.py build_ext--inplace
你應該可以看到兩個檔案cython_generator.c 檔案和generator.so檔案,我們使用下面方法測試我們的程式:
import timeit
print(timeit.timeit("sum(generator.generate(999))", setup="import generator", number=1000))
>>> 0.835658073425#cython_generator.pyx
cdef extern from "stdlib.h":
int c_libc_rand "rand"()
def generate(int num):
while num:
yield c_libc_rand() % 10
num -= 1>>> 0.033586025238
僅僅的幾個改變帶來了不賴的結果。然而,有時這個改變很乏味,因此讓我們來看看如何使用規則的python來實現吧。
4、PyPy的介紹
PyPy 是一個Python2.7.3的即時編譯器(JIT),通俗地說這意味著讓你的程式碼執行的更快。Quora在生產環境中使用了PyPy。PyPy在它們的下載頁面有一些安裝說明,但是如果你使用的Ubuntu系統,你可以通過apt-get來安裝。它的執行方式是立即可用的,因此沒有瘋狂的bash或者執行指令碼,只需下載然後執行即可。讓我們看看我們原始的生成器程式碼在PyPy下的效能如何。
import timeit
import random
def generate(num):
while num:
yield random.randrange(10)
num -= 1
def create_list(num):
numbers = []
while num:
numbers.append(random.randrange(10))
num -= 1
return numbers
print(timeit.timeit("sum(generate(999))", setup="from __main__ import generate", number=1000))
>>> 0.115154981613 #PyPy 1.9
>>> 0.118431091309 #PyPy 2.0b1
print(timeit.timeit("sum(create_list(999))", setup="from __main__ import create_list", number=1000))
>>> 0.140175104141 #PyPy 1.9
>>> 0.140514850616 #PyPy 2.0b15、進一步測試
為什麼還要進一步研究?PyPy是冠軍!並不全對。雖然大多數程式可以執行在PyPy上,但是還是有一些庫沒有被完全支援。而且,為你的專案寫C的擴充套件相比換一個編譯器更加容易。讓我們更加深入一些,看看ctypes如何讓我們使用C來寫庫。我們來測試一下歸併排序和計算斐波那契數列的速度。下面是我們要用到的C程式碼(functions.c):
/* functions.c */
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
/* http://rosettacode.org/wiki/Sorting_algorithms/Merge_sort#C */
inline
void merge(int *left, int l_len, int *right, int r_len, int *out)
{
int i, j, k;
for (i = j = k = 0; i < l_len && j < r_len; )
out[k++] = left[i] < right[j] ? left[i++] : right[j++];
while (i < l_len) out[k++] = left[i++];
while (j < r_len) out[k++] = right[j++];
}
/* inner recursion of merge sort */
void recur(int *buf, int *tmp, int len)
{
int l = len / 2;
if (len <= 1) return;
/* note that buf and tmp are swapped */
recur(tmp, buf, l);
recur(tmp + l, buf + l, len - l);
merge(tmp, l, tmp + l, len - l, buf);
}
/* preparation work before recursion */
void merge_sort(int *buf, int len)
{
/* call alloc, copy and free only once */
int *tmp = malloc(sizeof(int) * len);
memcpy(tmp, buf, sizeof(int) * len);
recur(buf, tmp, len);
free(tmp);
}
int fibRec(int n){
if(n < 2)
return n;
else
return fibRec(n-1) + fibRec(n-2);
}gcc -Wall-fPIC-c
functions.c
gcc -shared-o libfunctions.so functions.o
使用ctypes, 通過載入”libfunctions.so”這個共享庫,就像我們前邊對標準C庫所作的那樣,就可以使用這個庫了。這裡我們將要比較Python實現和C實現。現在我們開始計算斐波那契數列:
#functions.py
from ctypes import *
import time
libfunctions = cdll.LoadLibrary("./libfunctions.so")
def fibRec(n):
if n < 2:
return n
else:
return fibRec(n-1) + fibRec(n-2)
start = time.time()
fibRec(32)
finish = time.time()
print("Python: " + str(finish - start))
#C Fibonacci
start = time.time()
x = libfunctions.fibRec(32)
finish = time.time()
print("C: " + str(finish - start))Python: 1.18783187866 #Python 2.7
Python: 1.272292137145996 #Python 3.2
Python: 0.563600063324 #PyPy 1.9
Python: 0.567229032516 #PyPy 2.0b1
C: 0.043830871582 #Python 2.7 + ctypes
C: 0.04574108123779297 #Python 3.2 + ctypes
C: 0.0481240749359 #PyPy 1.9 + ctypes
C: 0.046403169632 #PyPy 2.0b1 + ctypes正如我們預料的那樣,C比Python和PyPy更快。我們也可以用同樣的方式比較歸併排序。
我們還沒有深挖Cypes庫,所以這些例子並沒有反映python強大的一面,Cypes庫只有少量的標準型別限制,比如int型,char陣列,float型,位元組(bytes)等等。預設情況下,沒有整形陣列,然而通過與c_int相乘(ctype為int型別)我們可以間接獲得這樣的陣列。這也是程式碼第7行所要呈現的。我們建立了一個c_int陣列,有關我們數字的陣列並分解打包到c_int陣列中
主要的是c語言不能這樣做,而且你也不想。我們用指標來修改函式體。為了通過我們的c_numbers的數列,我們必須通過引用傳遞merge_sort功能。執行merge_sort後,我們利用c_numbers陣列進行排序,我已經把下面的程式碼加到我的functions.py檔案中了。
#Python Merge Sort
from random import shuffle, sample
#Generate 9999 random numbers between 0 and 100000
numbers = sample(range(100000), 9999)
shuffle(numbers)
c_numbers = (c_int * len(numbers))(*numbers)
from heapq import merge
def merge_sort(m):
if len(m) <= 1:
return m
middle = len(m) // 2
left = m[:middle]
right = m[middle:]
left = merge_sort(left)
right = merge_sort(right)
return list(merge(left, right))
start = time.time()
numbers = merge_sort(numbers)
finish = time.time()
print("Python: " + str(finish - start))
#C Merge Sort
start = time.time()
libfunctions.merge_sort(byref(c_numbers), len(numbers))
finish = time.time()
print("C: " + str(finish - start))Python: 0.190635919571 #Python 2.7
Python: 0.11785483360290527 #Python 3.2
Python: 0.266992092133 #PyPy 1.9
Python: 0.265724897385 #PyPy 2.0b1
C: 0.00201296806335 #Python 2.7 + ctypes
C: 0.0019741058349609375 #Python 3.2 + ctypes
C: 0.0029308795929 #PyPy 1.9 + ctypes
C: 0.00287103652954 #PyPy 2.0b1 + ctypes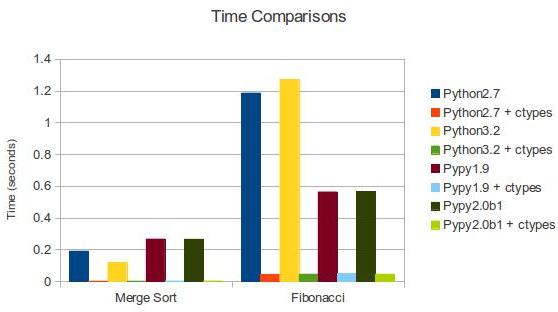
| Merge Sort | Fibonacci | |
|---|---|---|
| Python 2.7 | 0.191 | 1.187 |
| Python 2.7 + ctypes | 0.002 | 0.044 |
| Python 3.2 | 0.118 | 1.272 |
| Python 3.2 + ctypes | 0.002 | 0.046 |
| PyPy 1.9 | 0.267 | 0.564 |
| PyPy 1.9 + ctypes | 0.003 | 0.048 |
| PyPy 2.0b1 | 0.266 | 0.567 |
| PyPy 2.0b1 + ctypes | 0.003 | 0.046 |
程式碼優化能夠讓程式執行更快,它是在不改變程式執行結果的情況下使得程式的執行效率更高,根據 80/20 原則,實現程式的重構、優化、擴充套件以及文件相關的事情通常需要消耗 80% 的工作量。優化通常包含兩方面的內容:減小程式碼的體積,提高程式碼的執行效率。
6、改進演算法,選擇合適的資料結構
一個良好的演算法能夠對效能起到關鍵作用,因此效能改進的首要點是對演算法的改進。在演算法的時間複雜度排序上依次是:
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
因此如果能夠在時間複雜度上對演算法進行一定的改進,對效能的提高不言而喻。但對具體演算法的改進不屬於本文討論的範圍,讀者可以自行參考這方面資料。下面的內容將集中討論資料結構的選擇。
● 字典 (dictionary) 與列表 (list)
Python 字典中使用了hash table,因此查詢操作的複雜度為 O(1),而 list 實際是個陣列,在 list 中,查詢需要遍歷整個 list,其複雜度為 O(n),因此對成員的查詢訪問等操作字典要比 list 更快。
清單 1. 程式碼 dict.py
from time import time
t = time()
list = ['a','b','is','python','jason','hello','hill','with','phone','test',
'dfdf','apple','pddf','ind','basic','none','baecr','var','bana','dd','wrd']
#list = dict.fromkeys(list,True)
print list
filter = []
for i in range (1000000):
for find in ['is','hat','new','list','old','.']:
if find not in list:
filter.append(find)
print "total run time:"
print time()-t上述程式碼執行大概需要 16.09seconds。如果去掉行 #list = dict.fromkeys(list,True) 的註釋,將 list 轉換為字典之後再執行,時間大約為 8.375 seconds,效率大概提高了一半。因此在需要多資料成員進行頻繁的查詢或者訪問的時候,使用 dict 而不是 list 是一個較好的選擇。
● 集合 (set) 與列表 (list)
set 的 union, intersection,difference 操作要比 list 的迭代要快。因此如果涉及到求 list 交集,並集或者差的問題可以轉換為 set 來操作。
清單 2. 求 list 的交集:
from time import time
t = time()
lista=[1,2,3,4,5,6,7,8,9,13,34,53,42,44]
listb=[2,4,6,9,23]
intersection=[]
for i in range (1000000):
for a in lista:
for b in listb:
if a == b:
intersection.append(a)
print "total run time:"
print time()-ttotal run time: 38.4070000648清單 3. 使用 set 求交集
from time import time
t = time()
lista=[1,2,3,4,5,6,7,8,9,13,34,53,42,44]
listb=[2,4,6,9,23]
intersection=[]
for i in range (1000000):
list(set(lista)&set(listb))
print "total run time:"
print time()-t改為 set 後程序的執行時間縮減為 8.75,提高了 4 倍多,執行時間大大縮短。讀者可以自行使用表 1 其他的操作進行測試。
表 1. set 常見用法
| 語法 | 操作 | 說明 |
|---|---|---|
| set(list1) | set(list2) | union | 包含 list1 和 list2 所有資料的新集合 |
| set(list1) & set(list2) | intersection | 包含 list1 和 list2 中共同元素的新集合 |
| set(list1) - set(list2) | difference | 在 list1 中出現但不在 list2 中出現的元素的集合 |
7、對迴圈的優化
對迴圈的優化所遵循的原則是儘量減少迴圈過程中的計算量,有多重迴圈的儘量將內層的計算提到上一層。 下面通過例項來對比迴圈優化後所帶來的效能的提高。程式清單 4 中,如果不進行迴圈優化,其大概的執行時間約為 132.375。
清單 4. 為進行迴圈優化前
from time import time
t = time()
lista = [1,2,3,4,5,6,7,8,9,10]
listb =[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.01]
for i in range (1000000):
for a in range(len(lista)):
for b in range(len(listb)):
x=lista[a]+listb[b]
print "total run time:"
print time()-t現在進行如下優化,將長度計算提到迴圈外,range 用 xrange 代替,同時將第三層的計算 lista[a] 提到迴圈的第二層。
清單 5. 迴圈優化後
from time import time
t = time()
lista = [1,2,3,4,5,6,7,8,9,10]
listb =[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.01]
len1=len(lista)
len2=len(listb)
for i in xrange (1000000):
for a in xrange(len1):
temp=lista[a]
for b in xrange(len2):
x=temp+listb[b]
print "total run time:"
print time()-t8、充分利用 Lazy if-evaluation 的特性
python 中條件表示式是 lazy evaluation 的,也就是說如果存在條件表示式 if x and y,在 x 為 false 的情況下 y 表示式的值將不再計算。因此可以利用該特性在一定程度上提高程式效率。
清單 6. 利用 Lazy if-evaluation 的特性
from time import time
t = time()
abbreviations = ['cf.', 'e.g.', 'ex.', 'etc.', 'fig.', 'i.e.', 'Mr.', 'vs.']
for i in range (1000000):
for w in ('Mr.', 'Hat', 'is', 'chasing', 'the', 'black', 'cat', '.'):
if w in abbreviations:
#if w[-1] == '.' and w in abbreviations:
pass
print "total run time:"
print time()-t在未進行優化之前程式的執行時間大概為 8.84,如果使用註釋行代替第一個 if,執行的時間大概為 6.17。
9、字串的優化
python 中的字串物件是不可改變的,因此對任何字串的操作如拼接,修改等都將產生一個新的字串物件,而不是基於原字串,因此這種持續的 copy 會在一定程度上影響 python 的效能。對字串的優化也是改善效能的一個重要的方面,特別是在處理文字較多的情況下。字串的優化主要集中在以下幾個方面:
1、在字串連線的使用盡量使用 join() 而不是 +:在程式碼清單 7 中使用 + 進行字串連線大概需要 0.125 s,而使用 join 縮短為 0.016s。因此在字元的操作上 join 比 + 要快,因此要儘量使用 join 而不是 +。
清單 7. 使用 join 而不是 + 連線字串
from time import time
t = time()
s = ""
list = ['a','b','b','d','e','f','g','h','i','j','k','l','m','n']
for i in range (10000):
for substr in list:
s+= substr
print "total run time:"
print time()-ts = ""
for x in list:
s += func(x)slist = [func(elt) for elt in somelist]
s = "".join(slist)2、當對字串可以使用正則表示式或者內建函式來處理的時候,選擇內建函式。如 str.isalpha(),str.isdigit(),str.startswith((‘x’, ‘yz’)),str.endswith((‘x’, ‘yz’))
3、對字元進行格式化比直接串聯讀取要快,因此要使用
out = "%s%s%s%s" % (head, prologue, query, tail)out = "" + head + prologue + query + tail + ""10、其他優化技巧
1、如果需要交換兩個變數的值使用 a,b=b,a 而不是藉助中間變數 t=a;a=b;b=t;
>>> from timeit import Timer
>>> Timer("t=a;a=b;b=t","a=1;b=2").timeit()
0.25154118749729365
>>> Timer("a,b=b,a","a=1;b=2").timeit()
0.17156677734181258
>>>2、在迴圈的時候使用 xrange 而不是 range。使用 xrange 可以節省大量的系統記憶體,因為 xrange() 在序列中每次呼叫只產生一個整數元素。而 range() 將直接返回完整的元素列表,用於迴圈時會有不必要的開銷。在 python3 中 xrange 不再存在,裡面 range 提供一個可以遍歷任意長度的範圍的 iterator。
3、使用區域性變數,避免”global” 關鍵字。python 訪問區域性變數會比全域性變數要快得多,因 此可以利用這一特性提升效能。
4、if done is not None 比語句 if done != None 更快,讀者可以自行驗證;
5、在耗時較多的迴圈中,可以把函式的呼叫改為內聯的方式;
6、使用級聯比較 “x < y < z” 而不是 “x < y and y < z”;
7、while 1 要比 while True 更快(當然後者的可讀性更好);
8、build in 函式通常較快,add(a,b) 要優於 a+b。
11、定位程式效能瓶頸
對程式碼優化的前提是需要了解效能瓶頸在什麼地方,程式執行的主要時間是消耗在哪裡,對於比較複雜的程式碼可以藉助一些工具來定位,python 內建了豐富的效能分析工具,如 profile,cProfile 與 hotshot 等。其中 Profiler 是 python 自帶的一組程式,能夠描述程式執行時候的效能,並提供各種統計幫助使用者定位程式的效能瓶頸。Python 標準模組提供三種 profilers:cProfile,profile 以及 hotshot。
profile 的使用非常簡單,只需要在使用之前進行 import 即可。具體例項如下:
清單 8. 使用 profile 進行效能分析
import profile
def profileTest():
Total =1;
for i in range(10):
Total=Total*(i+1)
print Total
return Total
if __name__ == "__main__":
profile.run("profileTest()")1
2
6
24
120
720
5040
40320
362880
3628800
5 function calls in 0.015 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :0(range)
1 0.015 0.015 0.015 0.015 :0(setprofile)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 performance.py:2(profileTest)
1 0.000 0.000 0.015 0.015 profile:0(profileTest())
0 0.000 0.000 profile:0(profiler)其中輸出每列的具體解釋如下:
●ncalls:表示函式呼叫的次數;
●tottime:表示指定函式的總的執行時間,除掉函式中呼叫子函式的執行時間;
●percall:(第一個 percall)等於 tottime/ncalls;
●cumtime:表示該函式及其所有子函式的呼叫執行的時間,即函式開始呼叫到返回的時間;
●percall:(第二個 percall)即函式執行一次的平均時間,等於 cumtime/ncalls;
●filename:lineno(function):每個函式呼叫的具體資訊;
如果需要將輸出以日誌的形式儲存,只需要在呼叫的時候加入另外一個引數。如 profile.run(“profileTest()”,”testprof”)。
對於 profile 的剖析資料,如果以二進位制檔案的時候儲存結果的時候,可以通過 pstats 模組進行文字報表分析,它支援多種形式的報表輸出,是文字介面下一個較為實用的工具。使用非常簡單:
import pstats
p = pstats.Stats('testprof')
p.sort_stats("name").print_stats()其中 sort_stats() 方法能夠對剖分資料進行排序, 可以接受多個排序欄位,如 sort_stats(‘name’, ‘file’) 將首先按照函式名稱進行排序,然後再按照檔名進行排序。常見的排序欄位有 calls( 被呼叫的次數 ),time(函式內部執行時間),cumulative(執行的總時間)等。此外 pstats 也提供了命令列互動工具,執行 python – m pstats 後可以通過 help 瞭解更多使用方式。
對於大型應用程式,如果能夠將效能分析的結果以圖形的方式呈現,將會非常實用和直觀,常見的視覺化工具有 Gprof2Dot,visualpytune,KCacheGrind 等。
12、效能分析的基本思路
儘管並非每個你寫的Python程式都需要嚴格的效能分析,但瞭解一下Python的生態系統中很多優秀的在你需要做效能分析的時候可以使用的工具仍然是一件值得去做的事。
分析一個程式的效能,最終都歸結為回答4個基本的問題:
- 程式執行速度有多快?
- 執行速度瓶頸在哪兒?
- 程式使用了多少記憶體?
- 記憶體洩露發生在哪裡?
使用time工具粗糙定時
首先,我們可以使用快速然而粗糙的工具:古老的unix工具time,來為我們的程式碼檢測執行時間。
$ time python yourprogram.py
real 0m1.028s
user 0m0.001s
sys 0m0.003s- real - 表示實際的程式執行時間
- user - 表示程式在使用者態的cpu總時間
- sys - 表示在核心態的cpu總時間
通過sys和user時間的求和,你可以直觀的得到系統上沒有其他程式執行時你的程式執行所需要的CPU週期。
若sys和user時間之和遠遠少於real時間,那麼你可以猜測你的程式的主要效能問題很可能與IO等待相關。
使用計時上下文管理器進行細粒度計時
我們的下一個技術涉及訪問細粒度計時資訊的直接程式碼指令。這是一小段程式碼,我發現使用專門的計時測量是非常重要的:
timer.py
import time
class Timer(object):
def __init__(self, verbose=False):
self.verbose = verbose
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
self.end = time.time()
self.secs = self.end - self.start
self.msecs = self.secs * 1000 # millisecs
if self.verbose:
print 'elapsed time: %f ms' % self.msecs
為了使用它,你需要用Python的with關鍵字和Timer上下文管理器包裝想要計時的程式碼塊。它將會在你的程式碼塊開始執行的時候啟動計時器,在你的程式碼塊結束的時候停止計時器。
這是一個使用上述程式碼片段的例子:
from timer import Timer
from redis import Redis
rdb = Redis()
with Timer() as t:
rdb.lpush("foo", "bar")
print "=> elasped lpush: %s s" % t.secs
with Timer() as t:
rdb.lpop("foo")
print "=> elasped lpop: %s s" % t.secs
我經常將這些計時器的輸出記錄到檔案中,這樣就可以觀察我的程式的效能如何隨著時間進化。
使用分析器逐行統計時間和執行頻率
Robert Kern有一個稱作line_profiler的不錯的專案,我經常使用它檢視我的腳步中每行程式碼多快多頻繁的被執行。
想要使用它,你需要通過pip安裝該python包:
$ pip install line_profiler一旦安裝完成,你將會使用一個稱做“line_profiler”的新模組和一個“kernprof.py”可執行指令碼。
想要使用該工具,首先修改你的原始碼,在想要測量的函式上裝飾@profile裝飾器。不要擔心,你不需要匯入任何模組。kernprof.py指令碼將會在執行的時候將它自動地注入到你的腳步的執行時。
primes.py
@profile
def primes(n):
if n==2:
return [2]
elif n<2:
return []
s=range(3,n+1,2)
mroot = n ** 0.5
half=(n+1)/2-1
i=0
m=3
while m <= mroot:
if s[i]:
j=(m*m-3)/2
s[j]=0
while j<half:
s[j]=0
j+=m
i=i+1
m=2*i+3
return [2]+[x for x in s if x]
primes(100)
kernprof.py -l -v fib.pyWrote profile results to primes.py.lprof
Timer unit: 1e-06 s
File: primes.py
Function: primes at line 2
Total time: 0.00019 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
2 @profile
3 def primes(n):
4 1 2 2.0 1.1 if n==2:
5 return [2]
6 1 1 1.0 0.5 elif n<2:
7 return []
8 1 4 4.0 2.1 s=range(3,n+1,2)
9 1 10 10.0 5.3 mroot = n ** 0.5
10 1 2 2.0 1.1 half=(n+1)/2-1
11 1 1 1.0 0.5 i=0
12 1 1 1.0 0.5 m=3
13 5 7 1.4 3.7 while m <= mroot:
14 4 4 1.0 2.1 if s[i]:
15 3 4 1.3 2.1 j=(m*m-3)/2
16 3 4 1.3 2.1 s[j]=0
17 31 31 1.0 16.3 while j<half:
18 28 28 1.0 14.7 s[j]=0
19 28 29 1.0 15.3 j+=m
20 4 4 1.0 2.1 i=i+1
21 4 4 1.0 2.1 m=2*i+3
22 50 54 1.1 28.4 return [2]+[x for x in s if x]程式使用了多少記憶體?
現在我們對計時有了較好的理解,那麼讓我們繼續弄清楚程式使用了多少記憶體。我們很幸運,Fabian Pedregosa模仿Robert Kern的line_profiler實現了一個不錯的記憶體分析器。
首先使用pip安裝:
$ pip install -U memory_profiler
$ pip install psutil(這裡建議安裝psutil包,因為它可以大大改善memory_profiler的效能)。
就像line_profiler,memory_profiler也需要在感興趣的函式上面裝飾@profile裝飾器:
@profile
def primes(n):
...
...
$ python -m memory_profiler primes.pyFilename: primes.py
Line # Mem usage Increment Line Contents
==============================================
2 @profile
3 7.9219 MB 0.0000 MB def primes(n):
4 7.9219 MB 0.0000 MB if n==2:
5 return [2]
6 7.9219 MB 0.0000 MB elif n<2:
7 return []
8 7.9219 MB 0.0000 MB s=range(3,n+1,2)
9 7.9258 MB 0.0039 MB mroot = n ** 0.5
10 7.9258 MB 0.0000 MB half=(n+1)/2-1
11 7.9258 MB 0.0000 MB i=0
12 7.9258 MB 0.0000 MB m=3
13 7.9297 MB 0.0039 MB while m <= mroot:
14 7.9297 MB 0.0000 MB if s[i]:
15 7.9297 MB 0.0000 MB j=(m*m-3)/2
16 7.9258 MB -0.0039 MB s[j]=0
17 7.9297 MB 0.0039 MB while j<half:
18 7.9297 MB 0.0000 MB s[j]=0
19 7.9297 MB 0.0000 MB j+=m
20 7.9297 MB 0.0000 MB i=i+1
21 7.9297 MB 0.0000 MB m=2*i+3
22 7.9297 MB 0.0000 MB return [2]+[x for x in s if x]line_profiler和memory_profiler的IPython快捷方式
memory_profiler和line_profiler有一個鮮為人知的小竅門,兩者都有在IPython中的快捷命令。你需要做的就是在IPython會話中輸入以下內容:
%load_ext memory_profiler
%load_ext line_profilerIn [1]: from primes import primes
In [2]: %mprun -f primes primes(1000)
In [3]: %lprun -f primes primes(1000)記憶體洩漏在哪裡?
cPython直譯器使用引用計數做為記錄記憶體使用的主要方法。這意味著每個物件包含一個計數器,當某處對該物件的引用被儲存時計數器增加,當引用被刪除時計數器遞減。當計數器到達零時,cPython直譯器就知道該物件不再被使用,所以刪除物件,釋放佔用的記憶體。
如果程式中不再被使用的物件的引用一直被佔有,那麼就經常發生記憶體洩漏。
查詢這種“記憶體洩漏”最快的方式是使用Marius Gedminas編寫的objgraph,這是一個極好的工具。該工具允許你檢視記憶體中物件的數量,定位含有該物件的引用的所有程式碼的位置。
一開始,首先安裝objgraph:
pip install objgraph一旦你已經安裝了這個工具,在你的程式碼中插入一行宣告呼叫偵錯程式:
import pdb; pdb.set_trace()最普遍的物件是哪些?
在執行的時候,你可以通過執行下述指令檢視程式中前20個最普遍的物件:
(pdb) import objgraph
(pdb) objgraph.show_most_common_types()
MyBigFatObject 20000
tuple 16938
function 4310
dict 2790
wrapper_descriptor 1181
builtin_function_or_method 934
weakref 764
list 634
method_descriptor 507
getset_descriptor 451
type 439哪些物件已經被新增或刪除?
我們也可以檢視兩個時間點之間那些物件已經被新增或刪除:
(pdb) import objgraph
(pdb) objgraph.show_growth()
.
.
.
(pdb) objgraph.show_growth() # this only shows objects that has been added or deleted since last show_growth() call
traceback 4 +2
KeyboardInterrupt 1 +1
frame 24 +1
list 667 +1
tuple 16969 +1誰引用著洩漏的物件?
繼續,你還可以檢視哪裡包含給定物件的引用。讓我們以下述簡單的程式做為一個例子:
x = [1]
y = [x, [x], {"a":x}]
import pdb; pdb.set_trace()
(pdb) import objgraph
(pdb) objgraph.show_backref([x], filename="/tmp/backrefs.png")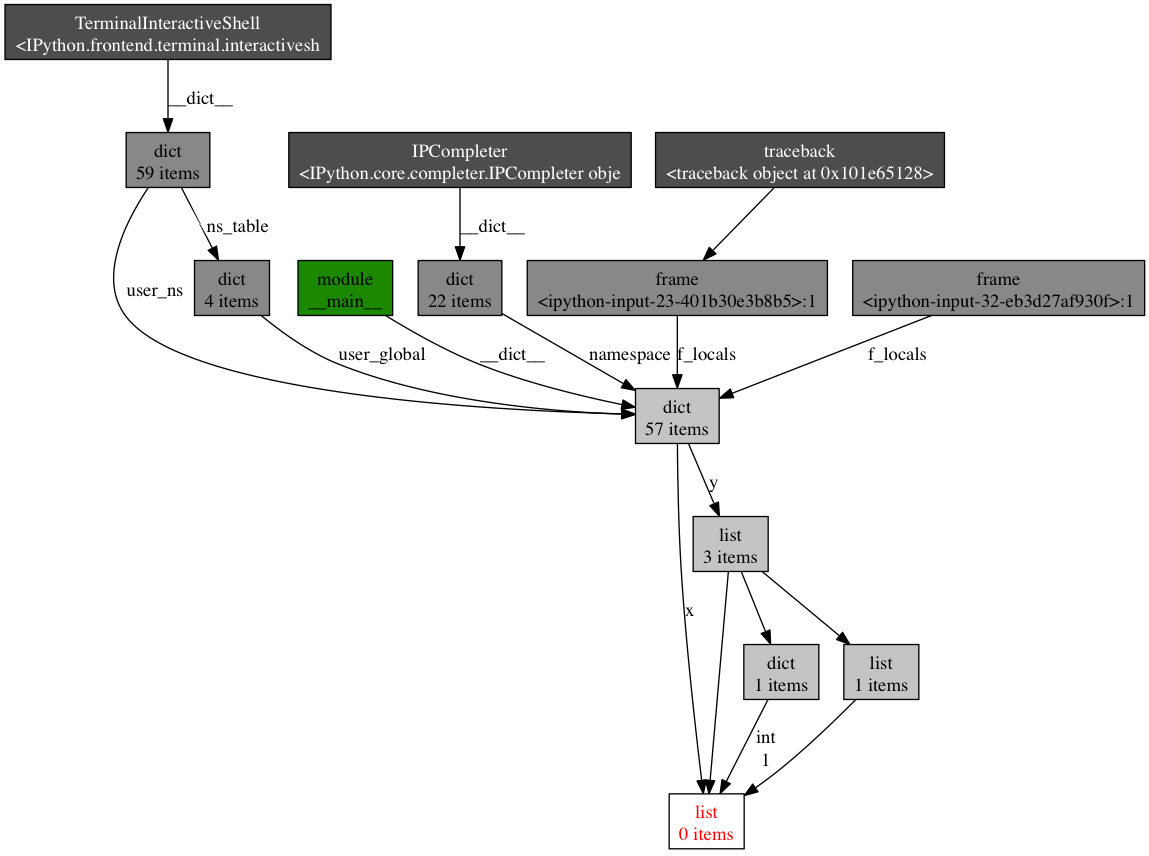
最下面有紅字的盒子是我們感興趣的物件。我們可以看到,它被符號x引用了一次,被列表y引用了三次。如果是x引起了一個記憶體洩漏,我們可以使用這個方法,通過跟蹤它的所有引用,來檢查為什麼它沒有自動的被釋放。
- 顯示佔據python程式記憶體的頭N個物件
- 顯示一段時間以後哪些物件被刪除活增加了
- 在我們的指令碼中顯示某個給定物件的所有引用
努力與精度
在本帖中,我給你顯示了怎樣用幾個工具來分析python程式的效能。通過這些工具與技術的武裝,你可以獲得所有需要的資訊,來跟蹤一個python程式中大多數的記憶體洩漏,以及識別出其速度瓶頸。
對許多其他觀點來說,執行一次效能分析就意味著在努力目標與事實精度之間做出平衡。如果感到困惑,那麼就實現能適應你目前需求的最簡單的解決方案。
參考文章: