python_sklearn機器學習算法系列之AdaBoost------人臉識別(PCA,決策樹)
本文主要目的是通過一個簡單的小例子和很短的程式碼來快速學習python 中的sklearn.ensemble的 AdaBoost這一模組的基本操作和使用,注意不是用python純粹從頭到尾自己構建AdaBoost,既然sklearn提供了現成的我們直接拿來用就可以了,當然其原理十分重要,下面做簡單介紹:
其實說到AdaBoost就不得不提到bagging,那麼它究竟是什麼東東呢?它是一種自舉匯聚發,比如現在有一個數據集M,我們每次從中有放回的抽取S個樣本生成一個新的資料集合(注意這個集合裡面可能包括多個重複的樣本,也有可能不包括原資料集中有的樣本),那麼我們重複K次這樣的操作就形成K個數據集對吧即N1,N2,N3……NK。每個資料集裡面有S個樣本,接下來將某個學習演算法分別作用於每個資料集就得到S個分類(迴歸)器,當我們要對新資料進行分類(迴歸)時,就可以應用這S個分類(迴歸)器進行作業,與此同時,選擇分類器中投票結果最多的類別作為最後分類結果(對於迴歸問題則採用S個結果的均值作為結果)(隨機森林就是一種高階的bagging)。
注意AdaBoost在分類和迴歸問題中都可以應運,原理大體相同,下面就都以分類來介紹。
那麼什麼是boosting呢?它和bagging十分相似,但在其基礎上增加了一些權值,即在下一次訓練的時候會根據上一次訓練結果改變樣本的權值,即上一次分對的樣本的權重會降低,相反則權重增加。另外它還對每個分類器分配了一個權重值alpha,這些alpha值是根據每個弱分類器(就是那些基本的分類器)的錯誤率進行計算的。
總之一句話通過引入這些權重來進一步減低錯誤率,而本文AdaBoost全稱是adaptive boosting(自適應boosting)屬於boosting的一種,說到這裡就要注意一下使用AdaBoost組合的弱分類器必須支援權重計算,小編當時就犯了這個低階錯誤,為了方便直接用了我上篇文章

所以我們下面程式使用決策樹這個弱分類,好了這些概念和它們之間的關係我們屢清後,我們看看python 中的sklearn.ensemble的 AdaBoost
它包含兩個函式AdaBoostClassifier和AdaBoostRegresso顧名思義分別解決分類和迴歸問題接下來我們分別介紹
對於AdaBoostClassifier()有幾個比較重要的引數:(1) base_estimator就是指定我們要用的弱分類器,(2) algorithm是我們的AdaBoostClassifier選用什麼演算法,具體的有AMME和SAMME.R兩者的主要區別就是後者使用概率作為我們上面介紹的權重,所以如果我們這裡選用了SAMME.R演算法那麼base_estimator也要選有概率預測的弱分類器就是有沒有predict_proba這一函式(3)n_estimators就是迭代的次數(4)learning_rate每個弱學習器的權重縮減係數
注意AdaBoostClassifier調參主要就是n_estimators和learning_rate,理論上兩者越大越好,但不是絕對要聯合調參
對於AdaBoostRegresso (1) base_estimator同上,(2)loss有是三個選項linear、square、exponential三種選擇說白了就是對樣本的誤差處理對應為線性,平方和指數,預設為linear(3)n_estimators同上(4)learning_rate同上
到此知識性的東西差不多講解完了,接下來就讓我們實踐一下吧,再次說明:希望先看上一篇文章再來看下面的程式碼比較容易些,也對後面的對比有比較快的認識。
#PCA
import warnings
from sklearn import tree
from sklearn import metrics
from sklearn.cross_validation import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.ensemble import AdaBoostClassifier
#忽略一些版本不相容等警告
warnings.filterwarnings("ignore")
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
x=lfw_people.data
n_features=x.shape[1]
y=lfw_people.target
target_names=lfw_people.target_names
#分割訓練集和測試集
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.6)
#先訓練PCA模型
PCA=PCA(n_components=100).fit(x_train)
#返回測試集和訓練集降維後的資料集
x_train_pca = PCA.transform(x_train)
x_test_pca = PCA.transform(x_test)
#決策樹核心程式碼
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(x_train_pca, y_train)
#宣告使用AdaBoostClassifier
Ada1 = AdaBoostClassifier(tree.DecisionTreeClassifier(criterion='entropy'),
n_estimators=100,algorithm="SAMME", learning_rate=0.2)
Ada1.fit(x_train_pca,y_train) #訓練
Ada2 = AdaBoostClassifier(tree.DecisionTreeClassifier(criterion='entropy'),
n_estimators=300,algorithm="SAMME",learning_rate=0.2)
Ada2.fit(x_train_pca,y_train)
#識別測試集中的人臉
y_test_predict1=clf.predict(x_test_pca)
y_test_predict2=Ada1.predict(x_test_pca)
y_test_predict3=Ada2.predict(x_test_pca)
'''
#輸出
for i in range(len(y_test_predict)):
print(target_names[y_test_predict[i]])
'''
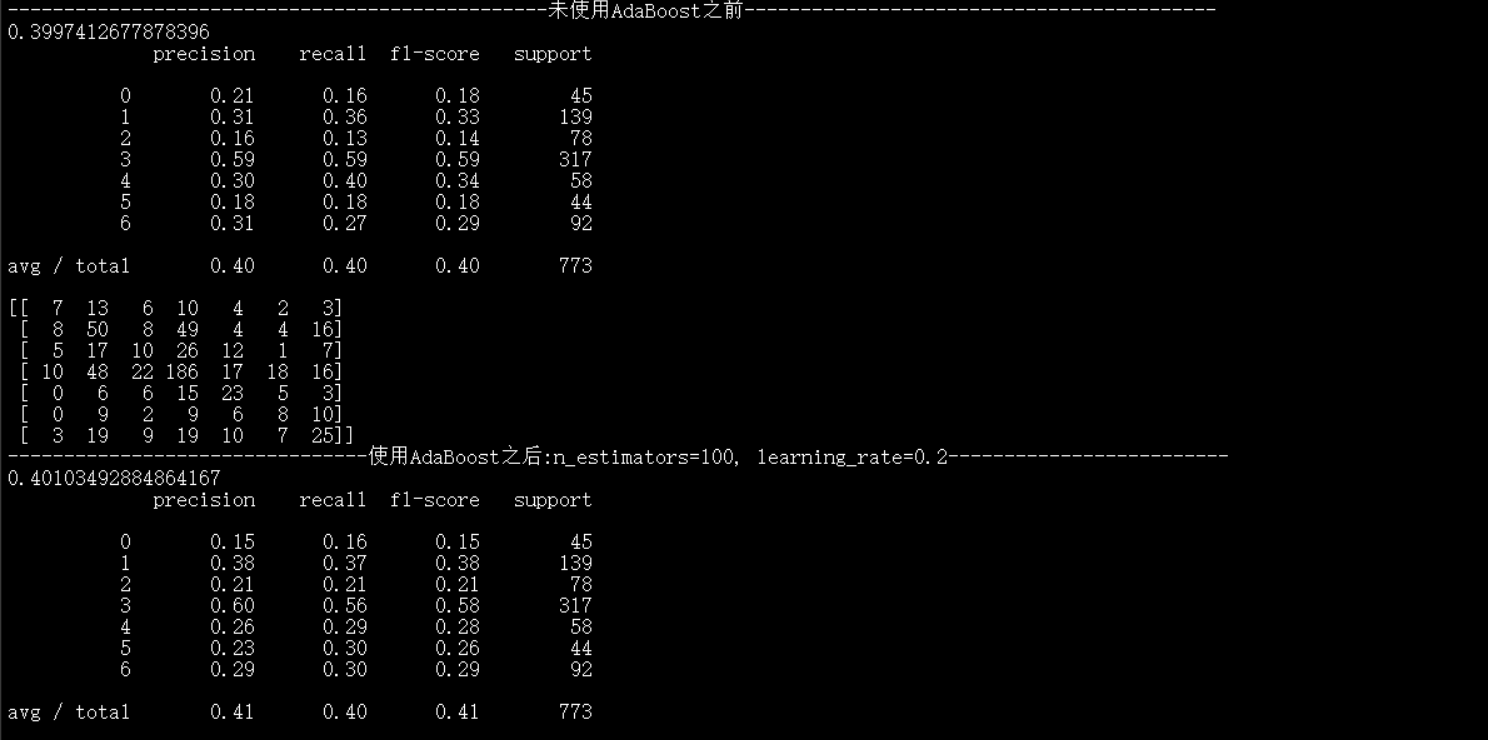
print("------------------------------------------------未使用AdaBoost之前------------------------------------------")
print(clf.score(x_test_pca, y_test)) #預測準確率
print(metrics.classification_report(y_test,y_test_predict1)) #包含準確率,召回率等資訊表
print(metrics.confusion_matrix(y_test,y_test_predict1)) #混淆矩陣
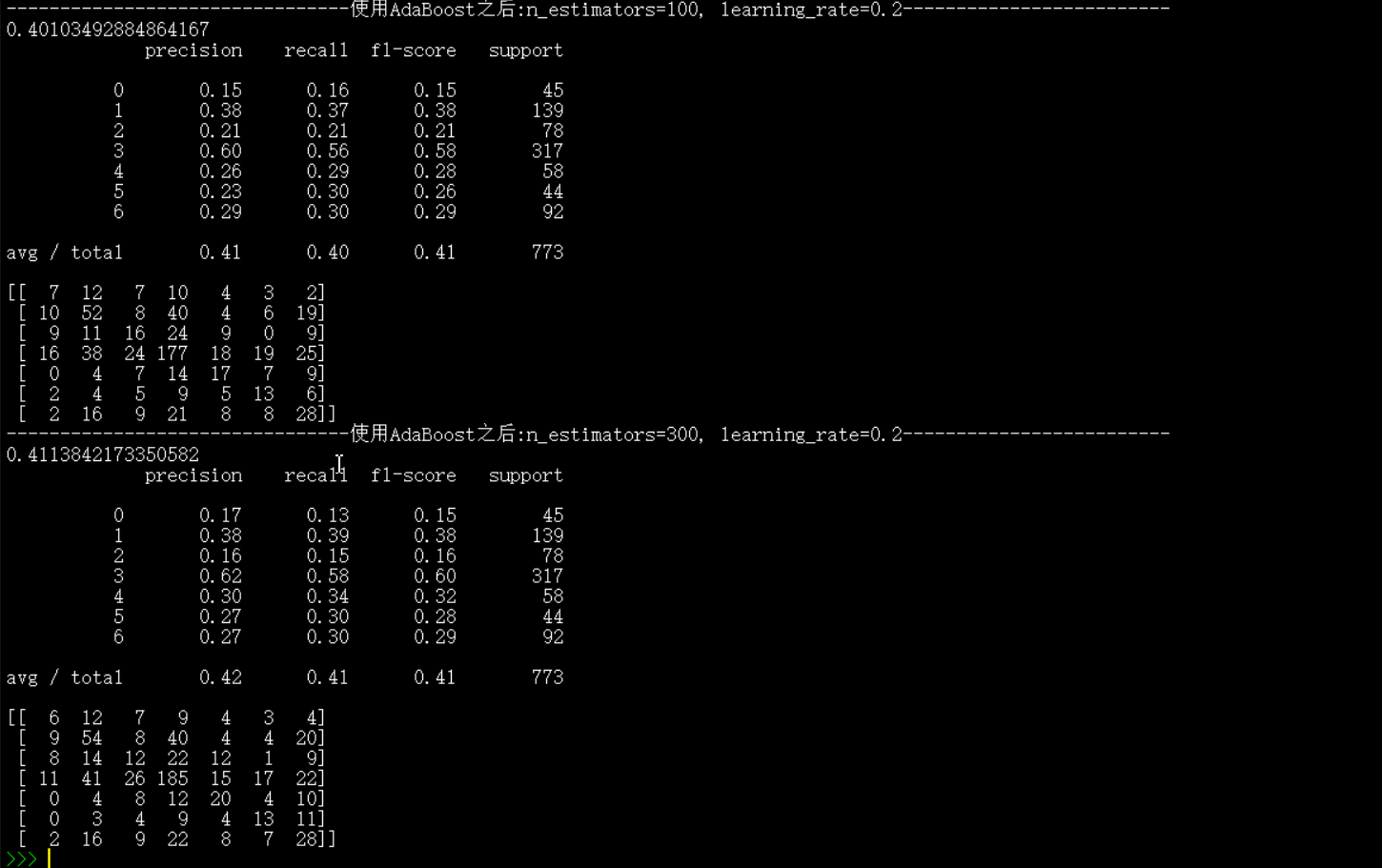
print("--------------------------------使用AdaBoost之後:n_estimators=100, learning_rate=0.2-------------------------")
print(Ada1.score(x_test_pca, y_test)) #預測準確率
print(metrics.classification_report(y_test,y_test_predict2)) #包含準確率,召回率等資訊表
print(metrics.confusion_matrix(y_test,y_test_predict2)) #混淆矩陣
print("--------------------------------使用AdaBoost之後:n_estimators=300, learning_rate=0.2-------------------------")
print(Ada2.score(x_test_pca, y_test)) #預測準確率
print(metrics.classification_report(y_test,y_test_predict3)) #包含準確率,召回率等資訊表
print(metrics.confusion_matrix(y_test,y_test_predict3)) #混淆矩陣
執行結果: