
MYSQL中為什麼索引不宜建在重複資料多的列上
阿新 • • 發佈:2019-01-01
昨天想了一天這個問題
首先我們先粗略的說一說:
加入有一個查詢語句要查詢性別為男生的資料,因為這樣的資料很多,我們要掃描很多次索引,然後再去取這個性別為男的資料。
那麼分為兩部分,先掃描索引,然後去取這個符合要求的資料
如果我們不建立索引,那麼去掃描整個表。
不建立索引需要的時間=T掃描整個表 建立索引需要的時間= T去索引中取+T取相應的資料條件
我們去考慮一種極限,如果性別全為男,那麼我們建立索引去查詢的時間就是T掃描整個索引表+T掃描整個表。那麼耗時肯定過大了。所以得出我們的結論
我們在通過innodb和MyISAM來細說
MyISAm中:就是類似於上面的描述,需要先去掃描索引樹,再去掃描表。
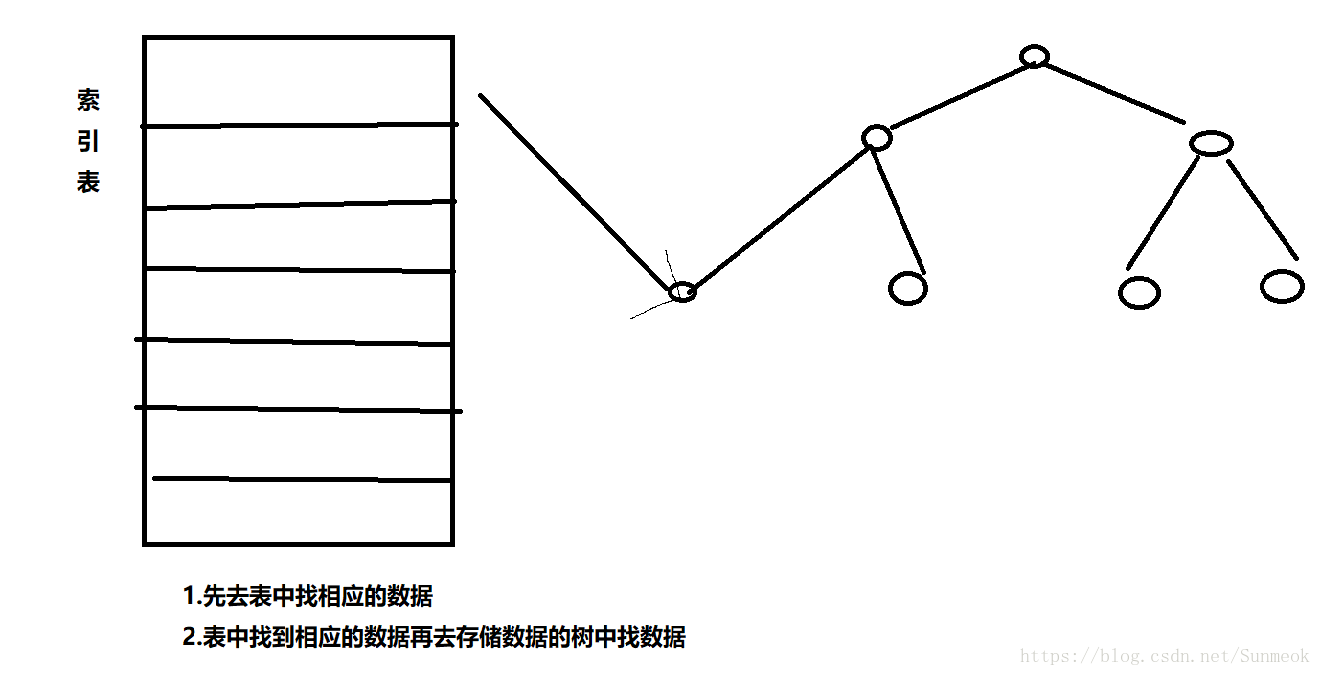
Innodb中:它的索引和資料在一起,它的非聚簇索引中保留了當前列和主鍵列的索引,每次查還要去主鍵索引查詢整個信心,因為主鍵的索引是包含所有節點資訊的,那麼非聚簇索引向聚簇索引轉換時就會出現問題時間消耗,如同上面的情況。
有人可能會問,如果放在聚簇索引上查詢重複多個列,那不就沒關係了,問題是聚集索引是唯一的,不能重複
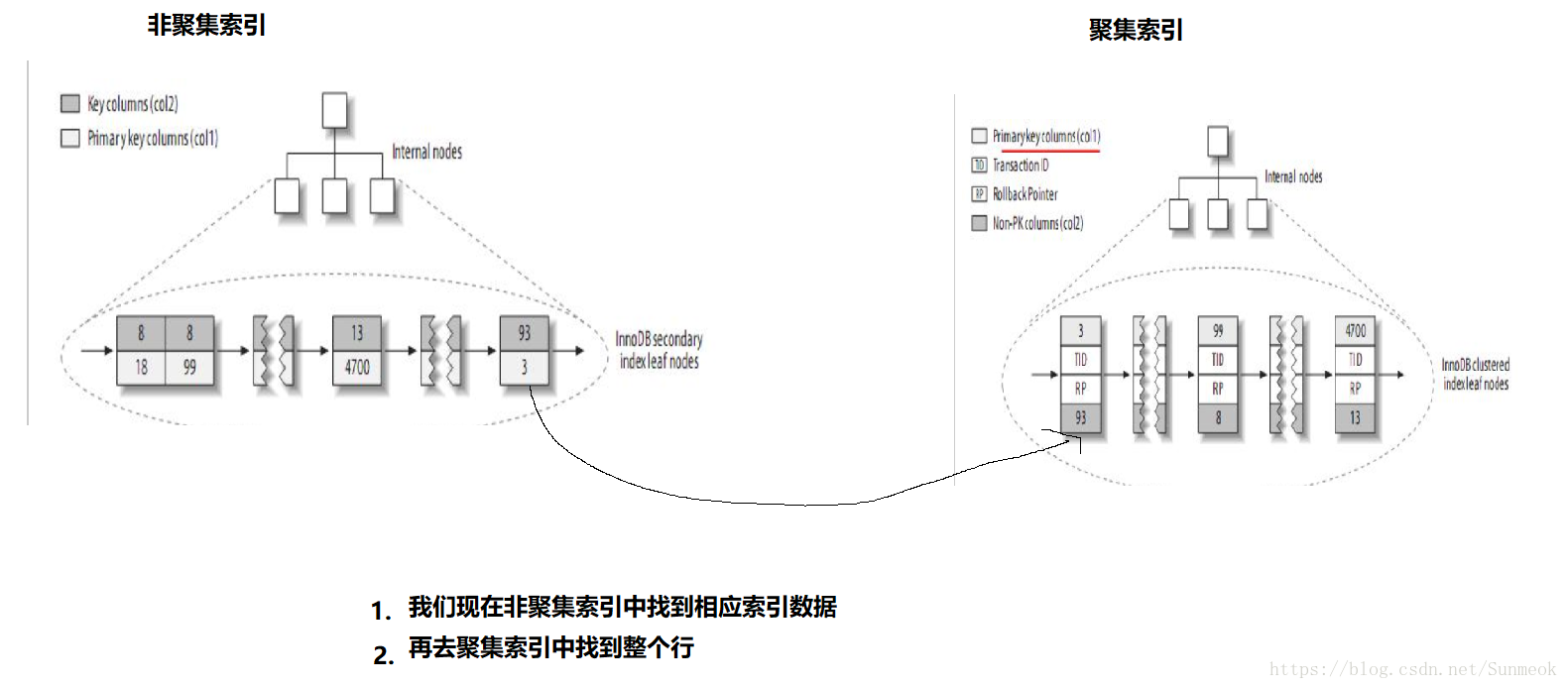
關於索引的儲存結構:
這兩篇文章都不錯,不過我覺得第一篇寫的更好。