
MySQL優化詳解
MYSQL優化
MYSQL優化主要分為以下四大方面:
設計:儲存引擎,欄位型別,正規化與逆正規化
功能:索引,快取,分割槽分表。
架構:主從複製,讀寫分離,負載均衡。
合理SQL:測試,經驗。
一、儲存引擎
在建立表的時候我們使用sql語句,Create table tableName () engine=myisam|innodb;
這裡就指明瞭儲存引擎是myisam還是innodb。儲存引擎是一種用來儲存MySQL中物件(記錄和索引)的一種特定的結構(檔案結構),處於MySQL伺服器的最底層,直接儲存資料。導致上層的操作,依賴於儲存引擎的選擇。地位如下圖:
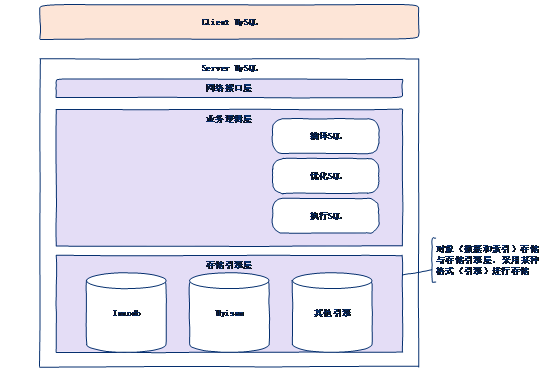
網路介面層:與客戶端通訊,比如傳輸資料等等。儲存引擎層:儲存資料的規則,方式。
本質:儲存引擎就是特定的資料儲存格式(方案)。
可以使用show engines命令來檢視當前MySQL支援的儲存引擎列表。
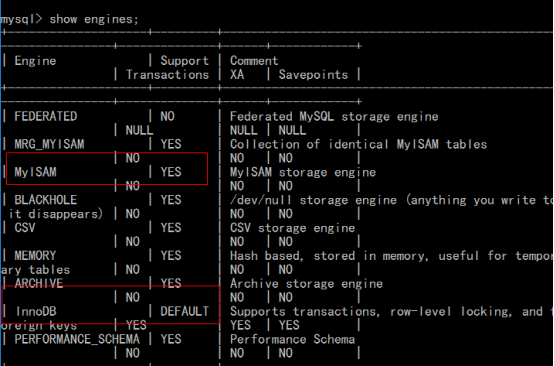
1、InnoDB儲存引擎介紹
Mysql版本>=5.5 預設的儲存引擎,MySQL推薦使用的儲存引擎。支援事務,行級鎖定,外來鍵約束。事務安全型儲存引擎。更加註重資料的完整性和安全性。
(1)儲存格式
資料,索引集中儲存,儲存於同一個表空間檔案中。
資料:記錄行。 索引:一種檢索機制,也需要一定的空間,就相當於一本字典的目錄。
示例: 建立一個test資料庫,新建一張student表,選擇儲存引擎為innodb, 然後開啟mysql的data下的test目錄,發現有以下3個檔案。

其中db.opt存放了資料庫的配置資訊,比如資料庫的字符集還有編碼格式。student.frm是表結構檔案,僅儲存了表的結構、元資料(meta),包括表結構定義資訊等。不論是哪個表引擎都會有一個frm檔案。student.ibd是表索引檔案,包括了單獨一個表的資料及索引內容。
如果往表裡插入了新的資料,則在mysql的data目錄下會生成ibdata1檔案,這個檔案是儲存了所有innodb表的資料。
關於innodb引擎的詳細介紹:
使用innodb引擎時,需要理解獨立表空間、共享表空間。
獨立表空間:每個表都會生成以獨立的檔案方式來儲存,每個表都一個.frm的描述檔案,還有一個.ibd檔案。其中這個檔案包括了單獨一個表的資料及索引內容,預設情況下它的儲存在mysql指定的目錄下。
獨立表空間優缺點
優點:
每個表都有自己獨立的表空間;每個表的資料和索引都會儲存在各個獨立的表空間中;可以實現單表在不同的資料進行遷移;表空間可以回收(除了drop table操作,表空不能自己回收);drop table 操作自動回收表空間,如果對統計分析或是日值表,刪除大量資料後可以通過 :alter table tablename engin=innodb進行回縮不用的空間;對於使用inodb-plugin的innodb使用truncate table會使用空間收縮。;對於使用獨立表空間,不管怎麼刪除,表空間的碎片都不會太嚴重。
缺點:
單表增加過大,如超過100G。對於單表增長過大的問題,如果使用共享表空間可以把檔案分開,但有同樣有一個問題,如果訪問的範圍過大同樣會訪問多個檔案,一樣會比較慢。對於獨立表空間也有一個解決辦法是:使用分割槽表,也可以把那個大的表空間移動到別的空間上然後做一個連線。其實從效能上出發,當一個表超過100個G有可能響應也是較慢了,對於獨立表空間還容易發現問題早做處理。
共享表空間:某一個數據庫所有的表資料,索引檔案全部都放在一個檔案中,預設這個共享表空間的檔案路徑在data目錄下,預設的檔名為 ibdata1,初始化為10M。
共享表空間優缺點
優點:可以將表空間分成多個檔案存放在各個磁碟上(表空間檔案大小不受表大小的限制,如一個表可以分佈在不同的檔案上),資料和檔案放在一起方便管理。
缺點:所有的資料和索引存放到一個檔案中,將來會是一個很大的檔案,雖然可以把一個大檔案分成多個小檔案,但是多個表及索引在表空間中混合儲存,這樣對一個表做了大量刪除操作後表空間將有大量的空隙,特別是對統計分析、日值系統這類應用最不適合用共享表空間。
如何開啟獨立表空間?
檢視是否開啟獨產表空間:
mysql> show variables like '%per_table';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | OFF |
+-----------------------+-------+
設定開啟:
在my.cnf檔案中[mysqld] 節點下新增innodb_file_per_table=1
或者通過命令:set global innodb_file_per_table=1;
注:
innodb_file_per_table值來進行修改即可,但是對於之前使用過的共享表空間則不會影響,除非手動的去進行修改或者是
innodb_file_per_table=1 為使用獨佔表空間
innodb_file_per_table=0 為使用共享表空間
修改獨佔空表空間的資料儲存位置
innodb_data_home_dir = "C:\mysql\data\"
innodb_log_group_home_dir = "C:\mysql\data\"
innodb_data_file_path=ibdata1:10M:autoextend
innodb_file_per_table=1
引數說明:
這個設定配置一個可擴充套件大小的尺寸為10MB的單獨檔案,名為ibdata1。沒有給出檔案的位置,所以預設的是在MySQL的資料目錄內。【對資料來進行初始化的設定】
innodb_data_home_dir 代表為資料庫檔案所存放的目錄
innodb_log_group_home_dir 為日誌存放目錄
innodb_file_per_table 是否使用共享以及獨佔表空間來
以上的幾個引數必須在一起加入。
對於引數一些注意的地方
InnoDB不建立目錄,所以在啟動伺服器之前請確認”所配置的路徑目錄”的確存在。這對你配置的任何日誌檔案目錄來說也是真實的。使用Unix或DOS的mkdir命令來建立任何必需的目錄。
通過把innodb_data_home_dir的值原原本本地部署到資料檔名,並在需要的地方新增斜槓或反斜槓,InnoDB為每個資料檔案形成目錄路徑。
如果innodb_data_home_dir選項根本沒有在my.cnf中提到,預設值是“dot”目錄 ./,這意思是MySQL資料目錄。
(2)資料按照主鍵順序儲存
插入時做排序工作,效率低。
(3)特定功能
事務、外來鍵約束 : 都是為了維護資料的完整性。
併發性處理:
innodb擅長處理併發的。因為它使用了行級鎖定,只該行鎖了,其它行沒有鎖。
行級鎖定:row-level locking,實現了行級鎖定,在一定情況下,可以選擇行級鎖來提升併發性。也支援表級鎖定,Innodb會自帶鎖,不需要我們自己設定。
多版本併發控制, MVCC,效果達到無阻塞讀操作。
(4)總結:innodb擅長事務、資料的完整性及高併發處理,不擅長快速插入(插入前要排序,消耗時間)和檢索。
2.MyISAM儲存引擎介紹
MySQL<= 5.5 MySQL預設的儲存引擎。
ISAM:Indexed Sequential Access Method(索引順序存取方法)的縮寫,是一種檔案系統。
擅長與處理,高速讀與寫。
(1)儲存方式
資料和索引分別儲存於不同的檔案中。

(2)資料的儲存順序為插入順序(沒有經過排序)
插入速度快,空間佔用量小。
(3)功能
a.全文索引支援。(mysql>=5.6時innodb 也支援)
b.資料的壓縮儲存。.MYD檔案的壓縮儲存。
壓縮前,資料是25600KB:

進行壓縮:使用工具 myisamPack完成壓縮功能:該工具mysql自帶

進入到需要壓縮表的資料目錄,執行壓縮指令 myisampack 表名。配置環境變數。
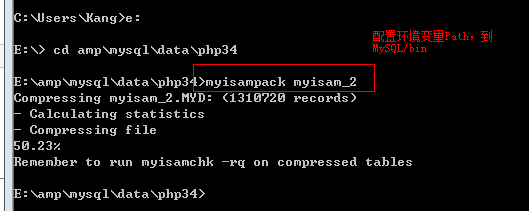
壓縮後:

注意,壓縮後,需要重新修復索引:
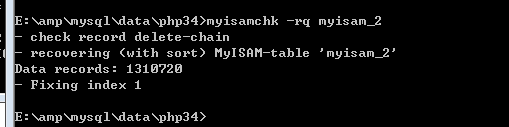
檢視結果,發現現在的資料變成12741KB了,比之前的更小了:

壓縮優勢:節省磁碟空間,減少磁碟IO開銷。 特點:壓縮後的表變成了只讀表,不可寫。
如果需要更新資料,則需要先解壓後更新。利用工具:myisamchk –unpack 表名 進行解壓

解壓後,變成了原來的25600KB

重新整理表的狀態:flush table myisam_2

c.併發性:
僅僅支援表級鎖定,不支援高併發。
支援併發插入。寫操作中的插入操作,不會阻塞讀操作(其他操作)
(4)關於Innodb 和 myisam的取捨:
Innodb :資料完整性,併發性處理,擅長更新,刪除。
myisam:高速查詢及插入。擅長插入和查詢。
具體舉例:
那麼對於微博專案來看,選擇哪一個儲存引擎呢?
a.微博主要是插入微博和查詢微博列表,較為適合MyISAM;
b.微博在更新微博和刪除微博,要少的多,較為適合MyISAM;
c.對資料完整性的需求並沒有那麼強烈,比如使用者刪除微博,關聯的轉播和評論並不要求都做相應的行為,較為適合MyISAM;
那麼對於記賬財務系統,選擇哪一款儲存引擎呢?
a.財務系統除了讀取和插入,經常要進行資料的修改和刪除,較為適合InnoDB;
b.在進行財務變更的時候,如果失敗需要回滾必須用到事務,較為適合InnoDB;
c.每個使用者的財務資料完整性和同步性非常重要,需要外來鍵支援,否則財務將會混亂,較為適合InnoDB。
3.其他儲存引擎
(1)Archive:存檔型,僅提供插入和查詢操作。非常高效阻塞的插入和查詢。
(2)Memory:記憶體型,資料儲存於記憶體中,儲存引擎。快取型儲存引擎。
(3)外掛式儲存引擎:用C和C++開發的儲存引擎。
4.鎖的概念:當客戶端操作表(記錄)時,為了保證操作的隔離性(多個客戶端操作不能互相影響),通過加鎖來處理。
操作方面:
讀鎖:讀操作時增加的鎖,也叫共享鎖,S-lock。特徵是阻塞其他客戶端的寫操作,不阻塞讀操作。(併發讀)
寫鎖:寫操作時增加的鎖,也叫獨佔鎖或排他鎖,X-lock。特徵是阻塞其他客戶端的讀,寫操作。
鎖定粒度(範圍):
行級:提升併發性,鎖本身開銷大
表級:不利於併發性,鎖本身開銷小。
二、欄位型別選擇
欄位型別應該要滿足需求,儘量要滿足以下需求。
儘可能小(佔用儲存空間少)、儘可能定長(佔用儲存空間固定)、儘可能使用整數。
1.列型別之數值
(1)整型
MySQL資料庫支援五種整型型別,包括:TINYINT、SMALLINT、MEDIUMINT、INT和BIGINT五種。
整型型別佔用空間和取值範圍
型別 位元組 最小值 最大值
TINYINT 1有符號:-128 無符號:0 有符號:127 無符號:255
SMALLINT 2有符號:-32768無符號:0有符號:32767無符號:65535
MEDIUMINT 3有符號:-8388608無符號:0有符號:8388607無符號:16777215
INT/INTEGER 4有符號:-2147483648無符號:0有符號:2147483647無符號:4294967295
BIGINT 8有符號:-9223372036854775808無符號:0 有符號:9223372036854775807無符號:18446744073709551615
五種整型的適用場景:
TINYINT,年齡,包含在0~255之間;
SMALLINT,埠號,包含在0~65535之間;
MEDIUMINT,中小型網站註冊會員,1600萬夠用;
INT,身份證編號,42億可以用很久;
BIGINT,Twitter微博量,幾百億
(2)浮點型(非精確)
MySQL資料庫支援兩種浮點型別:FLOAT(單精度)和DOUBLE(雙精度)兩種
浮點型(非精確)佔用空間和取值範圍
型別 位元組 範圍
FLOAT 4正數範圍:1.175494351E-38~3.402823466E+38,負數範圍:-3.402823466E+38~-1.175494351E-38
DOUBLE 8 正數範圍:1.7976931348623157E-308~2.2250738585072014E+308
負數範圍:-2.2250738585072014E+308~-1.7976931348623157E-308
(3)定點型(精確)
浮點型由於內部的儲存方式是數值,導致它在一定程度上取得的是近似值而非精確值。如果使用定點型,那麼就可以精確取得小數部分,因為它內部儲存方式是字串形式。
定點型(精確)佔用空間和取值範圍
型別 位元組 範圍
DECIMAL/NUMERIC M+2 M最大65位,D最大30位。
建立一個定點型格式:DECIMAL(M,D),表示小數點D位,整數部分M位及M位內。
2.列型別之日期
MySQL資料庫中有五個可用的日期時間資料型別,分別為:DATE、DATETIME、TIME、YEAR、TIMESTAMP。
日期時間型別佔用空間和取值範圍
型別 位元組 最小值 最大值
YEAR 1 1901 2155
TIME 3 -838:59:59838:59:59
DATE 4 1000-01-01 9999-12-31
TIMESTAMP 4 1970-01-01 00:00:00 2038-01-19 03:14:07
DATETIME 8 1000-01-01 00:00:00 9999-12-31 23:59:59
TIMESTAMP有幾個特點:
a.當更新一條資料的時候,設定此型別根據當前系統更新可自動更新時間;
b.如果插入一條NULL,也會自動插入當前系統時間;
c.建立欄位時,系統會自動給一個預設值;
d.會根據當前時區來儲存和查詢時間,儲存時對當前時區進行轉換,查詢時再轉換為當前的時區。
//檢視當前時區
SHOW VARIABLES LIKE 'time_zone';
//設定為東九區,查詢時間就會加1小時
SET time_zone='+9:00';
DATE佔用3個位元組,包含年月日,範圍和DATETIME一樣。DATE長度是0,無法設定。
YEAR佔用1個位元組,包年年份,長度預設為4位,無法設定。
TIME佔用3個位元組,包含時分秒,長度0到6之間,用於設定微秒。對於TIME的範圍的時是-838到838的原因,是因為TIME型別不但可以儲存一天的時,還可以包含時間之間的間隔。
綜上考慮:使用datetime,當然也可以使用int(11)來儲存時間戳。
關於INT(11)存放時間戳的優點如下:
a.INT佔4個位元組,DATETIME佔8個位元組;
b.INT儲存索引的空間比DATETIME小,查詢快,排序效率高;
c.在計算機時間差等範圍問題,比較方便。
3.列型別之字元
字符集校對規則utf8_general_ci表示校對時不區分大小寫,相對的cs表示區分大小寫。還有一個bin結尾的是位元組比較。而general是地區名,這裡是通用,utf8表示編碼。如果是gbk,可以使用gbk_chinese_ci,如果是utf8則用utf8_general。MySQL提供了多種對字元資料的儲存型別,包括:CHAR、VARCHAR、VARBINARY、BLOB、TEXT、ENUM和SET等多種字元型別。
(1)CHAR是儲存定長字串,而VARCHAR則是儲存變長字串。CHAR(5)表示必須儲存5個字元,而VARCHAR(5)則表示最大儲存字元為5。如果是UTF8編碼下,長度為5的CHAR型別,最多可以儲存15位元組,也就是5個漢字的內容。因為一個漢字佔3個位元組。
由於CHAR型別是定長,MySQL會根據定義的長度進行分配空間,在處理速度上比VARCHAR快的多,所以適合儲存例如手機、身份證這種定長的字元,否則就會造成浪費。那麼CHAR型別最大可以插入255個字元,最多可以儲存765個位元組。
(2)BINARY和VARBINARY是採用二進位制儲存的,沒有字符集概念,意義在於防止字符集的問題導致資料丟失,儲存中文會佔用兩個字元,會亂碼,半截會問號。因為是採用二進位制儲存,在比較字元和排序的時候,都是二進位制進行的,所以只有需要操作二進位制時才需要使用。
(3)八種適合文字內容的大資料型別:TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、TINYBLOG、BLOB、MEDIUMTEXT、LONGTEXT。
綜上:短文字定長用char,變長用varchar,長文字用text
4.列型別之屬性
無符號(UNSIGNED)和填充零(ZEROFILL),還有是否為空、預設值、主鍵、自動編號。
嚴格模式
我們使用的是WAMP整合環境,預設安裝的情況下,是非嚴格模式,用於部署階段。而開發除錯階段,強烈建議使用嚴格模式,方便開發中除錯將問題及時暴露出來。因為在非嚴格模式下將NULL插入NOTNULL等非法操作都是被執行的。設定嚴格模式只要開啟my.ini檔案,在末尾新增一句:
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
然後,重啟伺服器即可。檢查SQL_MODE狀態
SELECT @@global.sql_mode;
三、正規化與逆正規化
為了建立冗餘較小、結構合理的資料庫,設計資料庫時必須遵循一定的規則。在關係型資料庫中這種規則就稱為正規化。正規化是符合某一種設計要求的總結。要想設計一個結構合理的關係型資料庫,必須滿足一定的正規化。
第一正規化1NF,原子性
第二正規化2NF,消除部分依賴
第三正規化3NF,消除傳遞依賴
1、正規化
(1)第一正規化:具有原子性,確保每列保持原子性。
第一正規化是最基本的正規化。如果資料庫表中的所有欄位值都是不可分解的原子值,就說明該資料庫表滿足了第一正規化。第一正規化的合理遵循需要根據系統的實際需求來定。比如某些資料庫系統中需要用到“地址”這個屬性本來直接將“地址”屬性設計成一個數據庫表的欄位就行。但是如果系統經常會訪問“地址”屬性中的“城市”部分,那麼就非要將“地址”這個屬性重新拆分為省份、城市、詳細地址等多個部分進行儲存,這樣在對地址中某一部分操作的時候將非常方便。這樣設計才算滿足了資料庫的第一正規化。
(2)第二正規化:主鍵列與非主鍵列遵循完全函式依賴關係,確保表中的每列都和主鍵相關。
第二正規化在第一正規化的基礎之上更進一層。第二正規化需要確保資料庫表中的每一列都和主鍵相關,而不能只與主鍵的某一部分相關(主要針對聯合主鍵而言)。也就是說在一個數據庫表中,一個表中只能儲存一種資料,不可以把多種資料儲存在同一張資料庫表中。
(3)第三正規化:非主鍵列之間沒有傳遞函式依賴關係索引,確保每列都和主鍵列直接相關,而不是間接相關。
所謂傳遞函式依賴,指的是如果存在"A →B →C"的決定關係,則C傳遞函式依賴於A。因此,滿足第三正規化的資料庫表應該不存在如下依賴關係:
關鍵欄位→非關鍵欄位x →非關鍵欄位y
比如在設計一個訂單資料表的時候,可以將客戶編號作為一個外來鍵和訂單表建立相應的關係。而不可以在訂單表中新增關於客戶其它資訊(比如姓名、所屬公司等)的欄位。
先滿足第一正規化,再滿足第二正規化,才能滿足第三正規化。
2、逆正規化
逆正規化是指打破正規化,通過增加冗餘或重複的資料來提高資料庫的效能。
示例: 假如有一個商品表Goods:
欄位有Goods_id(商品表), goods_name(商品名稱), cat_id(所屬類別的id)。
還有一個分類表Category:
欄位有Cat_id(類別id), cat_name(類別名稱)。
現在要查詢類別id為3的商品的數量,例如分類列表查詢:
分類ID 分類名稱 商品數量
3 計算機 567
可以使用下列sql語句:
Select c.*, count(g.goods_id) as goods_count from category as c left join goods as g c.cat_id=g.cat_id group by c.cat_id;
但是,假如商品數量較大,那麼就比較耗效能了。這時,我們可以考慮重新設計Category表:增加存當前分類下商品數量的欄位。
Cat_id, cat_name, goods_count
每當商品改動時,修改對應分類的數量資訊。
再查詢分類列表時:Select * from category;
此時額外的消耗,出現在維護該欄位的正確性上,保證商品的任何更新都正確的處理該數量才可以。
四、索引
1.索引概述
利用關鍵字,就是記錄的部分資料(某個欄位,某些欄位,某個欄位的一部分),建立與記錄位置的對應關係,就是索引。索引的關鍵字一定是排序的。索引本質上是表字段的有序子集,它是提高查詢速度最有效的方法。一個沒有建立任何索引的表,就相當於一本沒有目錄的書,在每次查詢時就會進行全表掃描,這樣會導致查詢效率極低、速度也極慢。如果建立索引,那麼就好比一本新增的目錄,通過目錄的指引,迅速翻閱到指定的章節,提升的查詢效能,節約了查詢資源。
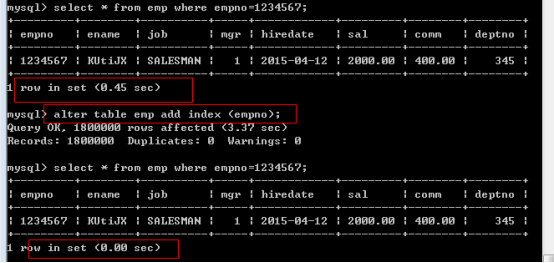
測試查詢,新增索引前後比對執行時間:
2.索引種類
從索引的定義方式和用途中來看:主鍵索引,唯一索引,普通索引,全文索引。
無論任何型別,都是通過建立關鍵字與位置的對應關係來實現的。索引是通過關鍵字找對應的記錄的地址。
以上型別的差異:對索引關鍵字的要求不同。
關鍵字:記錄的部分資料(某個欄位,某些欄位,某個欄位的一部分)。
普通索引,index:對關鍵字沒有要求。
唯一索引,unique index:要求關鍵字不能重複。同時增加唯一約束。
主鍵索引,primary key:要求關鍵字不能重複,也不能為NULL。同時增加主鍵約束。
全文索引,fulltext key:關鍵字的來源不是所有欄位的資料,而是從欄位中提取的特別關鍵詞。
關鍵字含義:可以是某個欄位,也可以是某些欄位。如果一個索引通過在多個欄位上提取的關鍵字,稱之為複合索引。 命令:alter table exp add index (field1, field2);
PS:這裡主鍵索引和唯一索引的區別在於:主鍵索引不能為空值,唯一索引允許空值;主鍵索引在一張表內只能建立一個,唯一索引可以建立多個。主鍵索引肯定是唯一索引,但唯一索引不一定是主鍵索引。
3.索引操作
(1)建立主鍵索引
建立一個無符號整型且自動增長的列,然後設定成主鍵即可。
//通過EXPLAIN語句檢視索引狀態
EXPLAIN SELECT * FROM think_user WHERE id=1;
(2)建立普通或唯一索引
直接進入navicat設計表的第二欄,選擇一個欄位(比如user欄位),新增一個Nomral(普通索引)或Unique(唯一索引)。
//通過EXPLAIN語句檢視索引狀態
EXPLAIN SELECT * FROM think_user WHERE user='蠟筆老新';
//查看錶所有索引情況
SHOW INDEX FROM think_user;
(3)使用sql語句的方式建立索引----建表時就建立索引
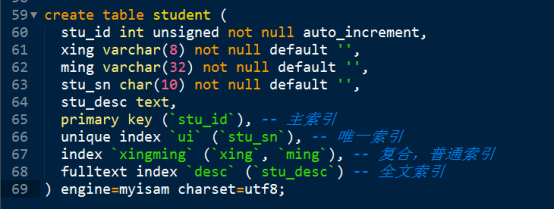
注意:索引可以起名字,但是主鍵索引不能起名字,因為一個表僅僅可以有一個主索引,其他索引可以出現多個。名字可以省略,mysql會預設生成,通常使用欄位名來充當。
(4)使用sql語句的方式建立索引----更新表時建立索引
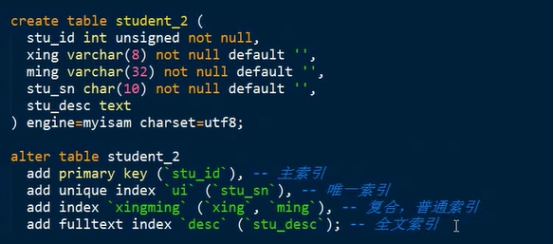
注意:如果表中存在資料,資料符合唯一或主鍵的約束才可能建立成功。 auto_increment屬性,依賴於一個KEY。
(5)使用sql語句的方式刪除索引,auto_increment依賴於KEY。

(6)Explain 執行計劃
可以通過在select語句前使用 explain,來獲取該查詢語句的執行計劃,而不是真正執行該語句。
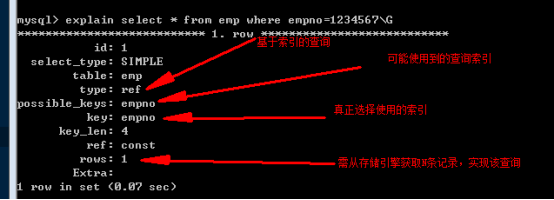
刪除索引時,再看執行計劃:

從查詢的行數可知,有索引時查詢會快的多,因為它只需要查詢一行,而沒有索引時,會造成全表掃描。
注意:select語句才能獲取到執行計劃。(新版本5.6會擴充套件其他語句的執行計劃的獲取)
4.索引原則
如果索引不遵循使用原則,則可能導致索引無效。
(1)列獨立
如果需要某個欄位上使用索引,則需要在欄位參與的表達中,保證欄位獨立在一側。

第三個語句 empno-1就不是列獨立:就不能用索引。類似函式等等。(write_time < unix_timestamp()-$gc_maxlifetime)
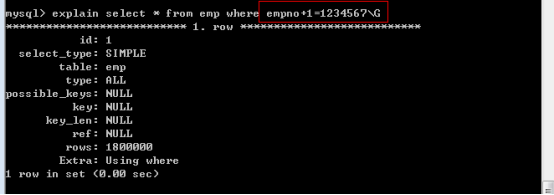
其他兩個列獨立可以使用:
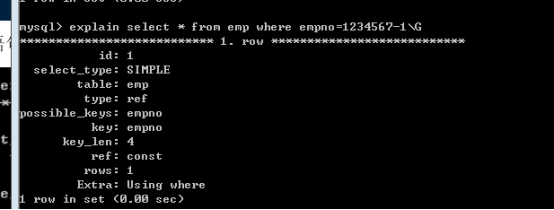
(2)左原則
Like:匹配模式必須要左邊確定不能以萬用字元開頭。
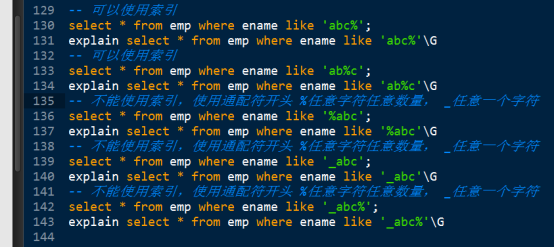
假如業務邏輯上出現: field like ‘%keywork%’;類似查詢,需要使用全文索引。
複合索引:一個索引關聯多個欄位,僅僅針對左邊欄位有效果。
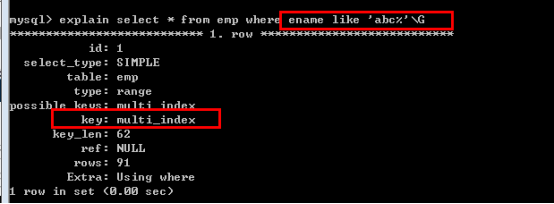
示例:新增複合索引

對Ename的查詢,使用了索引,結果如下:
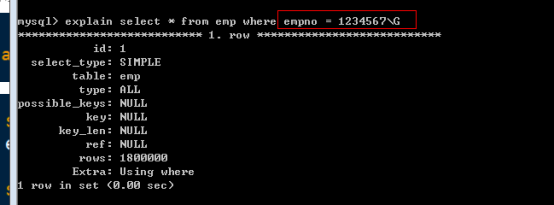
Empno的查詢沒有使用索引,結果如下:
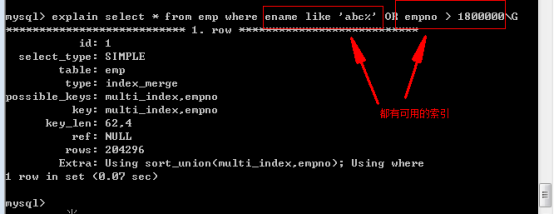
(3)OR的使用
必須要保證 OR 兩端的條件都存在可以用的索引,該查詢才可以使用索引。
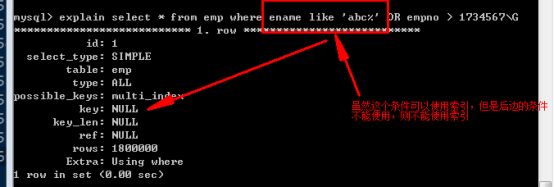
為後面的條件增加可以使用的索引後,再檢視執行計劃:
(4)MySQL智慧選擇
即使滿足了上面說原則,MySQL也能棄用索引:如下圖
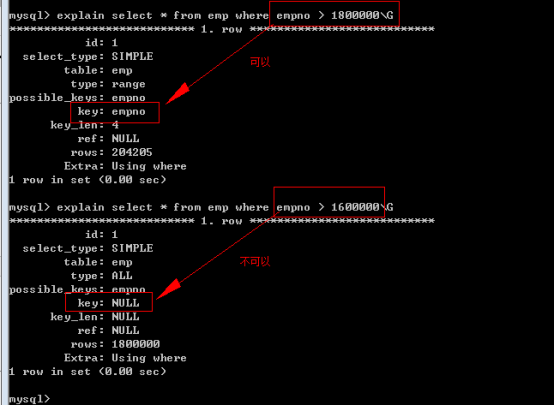
棄用索引的主要原因:
查詢即使使用索引,會導致出現大量的隨機IO,相對於從資料記錄的第一條遍歷到最後一條的順序IO開銷,還要大。
綜上歸納:
a、不要過度索引。索引越多,佔用空間越大,反而效能變慢;
b.只對WHERE子句中頻繁使用的建立索引;
c.儘可能使用唯一索引,重複值越少,索引效果越強;
d.使用短索引,如果char(255)太大,應該給它指定一個字首長度,大部分情況下前10位或20位值基本是唯一的,那麼就不要對整個列進行索引;
e.充分利用左字首,這是針對複合索引,因為WHERE語句如果有AND並列,只能識別一個索引(獲取記錄最少的那個),索引需要使用複合索引,那麼應該將WHERE最頻繁的放置在左邊。
f.索引存在,如果沒有滿足使用原則,也會導致索引無效:
5.索引的使用場景
(1)索引檢索:檢索資料時使用索引。
(2)索引排序
如果order by 排序需要的欄位上存在索引,則可能使用到索引。
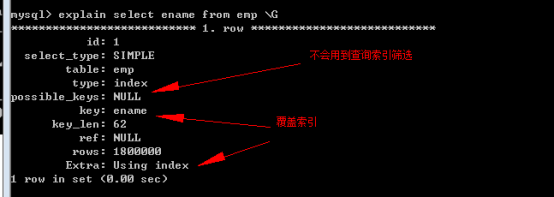
例如,按照ename欄位排序查詢:
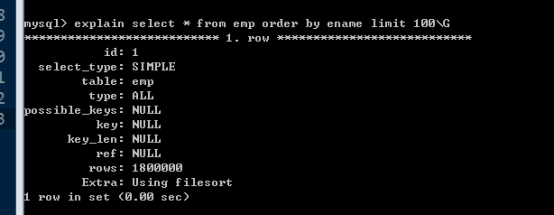
此時,沒有任何索引。在ename欄位上建立索引後:
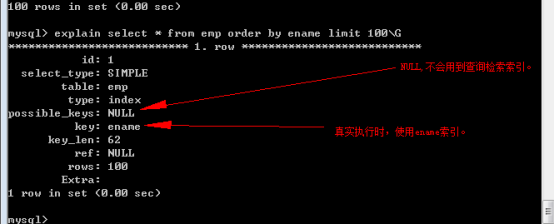
不會用到查詢檢索索引是因為沒有用where條件查詢,而真實執行時,就會用到排序索引。
Tip:對比以上兩個執行計劃:
extra位置:


其中:extra額外資訊。加了索引後就不用使用檔案排序了。
Using filesort,表示使用檔案排序(外部排序,記憶體外部)。
(3)索引覆蓋
索引擁有的關鍵字內容,覆蓋了查詢所需要的全部資料,此時,就不需要在資料區獲取資料,僅僅在索引區即可。覆蓋就是直接在索引區獲取內容,而不需要在資料區獲取。
例如,利用名字檢索:

可以在ename欄位建立索引:

分析執行:
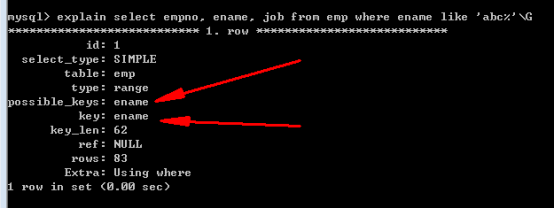
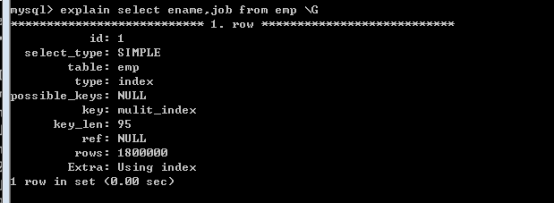
再增加一個索引:

完成相同的查詢:

查詢的欄位剛好是複合索引包含的欄位。所以就使用了複合索引。
說明,不是非要查詢用到,才可以索引覆蓋,只要滿足要求都可以覆蓋!
建立索引索引時,不要僅僅考慮where檢索,同時考慮其他的使用場景。(在所有的where欄位上增加索引,就是不合理的)
6.字首索引
字首索引是建立索引關鍵字一種方案。通常會使用欄位的整體作為索引關鍵字。有時,即使使用欄位前部分資料,也可以去識別某些記錄。就比如一個班級裡,我要找王xx,假如姓王的只有1個人,那麼就可以建一個字首索引,就是王。
語法:
Index `index_name` (`index_field`(N))使用index_name前N個字元建立的索引。
那麼N究竟是多少?使用N長度所達到的辨識度,極限接近於使用全部長度的辨識度即可!
先計算最大的辨識度M:
公式:先計算總的記錄數m,再求該欄位不重複的記錄數q,那麼M=m/q。然後依次取得前N個字元,N逐步增加,進行對比,直到找到極限接近於M的,那麼最後的N就是我們要找的N。

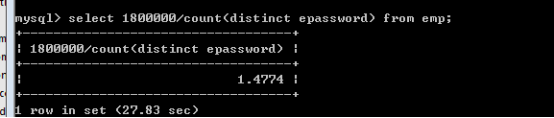
求得辨識度為1.4774.,也就是說一個字首索引可以對應1.4774條記錄。
然後依次取得前N個字元,進行對比,找到極限接近的:
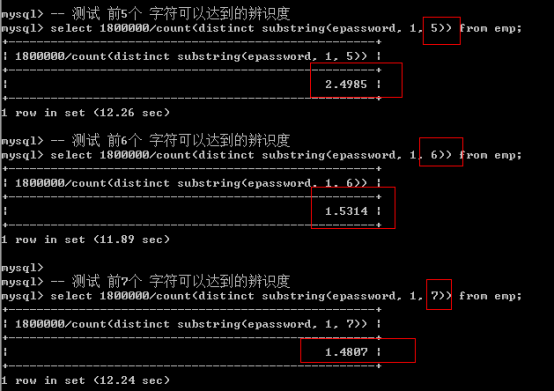
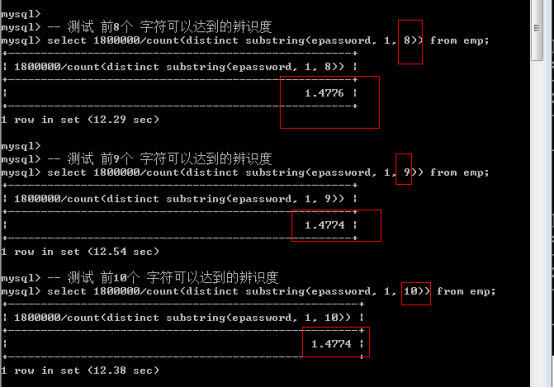
可見,9 時,已經極限接近,提高長度,不能明顯提升辨識度,因此可以使用前9個字元:
Tip:字首索引不能用於索引覆蓋!
7.全文索引
該型別的索引特殊在:關鍵字的建立上。是為了解決 like‘%keyword%’這類查詢的匹配問題。(mysql的全文索引幾乎不用,因為它不支援中文,我們應該使用sphinx全文索引)。
示例:
假如有一張表,表中有標題和內容兩個欄位,現在要查詢標題或者內容包含 “database” 關鍵字的記錄。
補充:text和varchar的區別是text的資料不存在記錄裡,一條記錄的最大空間是65535.
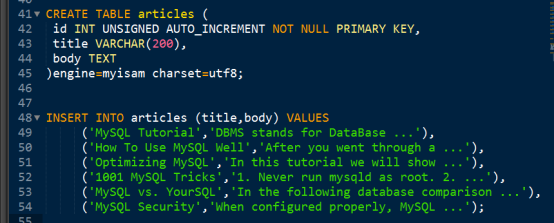
形成的SQL如下:
Select * from articles where title like ‘%database%’ or body like ‘%database%’;
此時不能建立普通索引,查詢不符合左原則,建立了也使用不了。
此時全文索引就可以發揮其作用了:

直接使用上面的SQL,需要使用特殊的全文索引匹配語法才可以生效: Match() against();
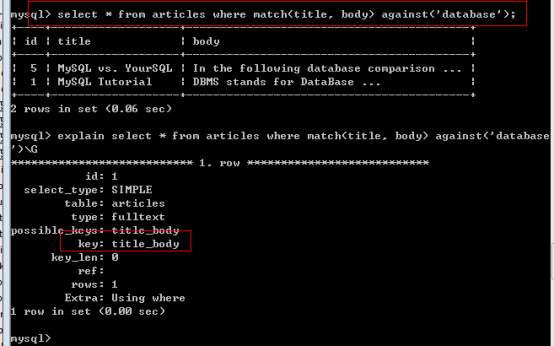
Tip: 該MYSQL提供的全文索引,不能對中文起作用!
使用Match() against() 返回關鍵字的匹配度(關鍵字與記錄的關聯程度)。
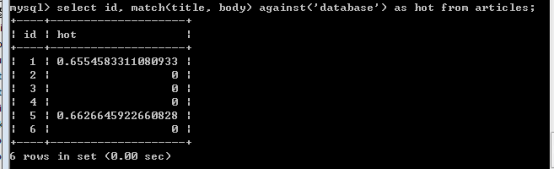
停止詞 in:

發現in這個詞,是不能被全文索引所檢索到的。因為in這個詞是不可以用在全文索引的關鍵詞裡的,沒有誰會在一段文本里檢索這樣一個詞。
思考:與 like %in% 是否相同?不同。
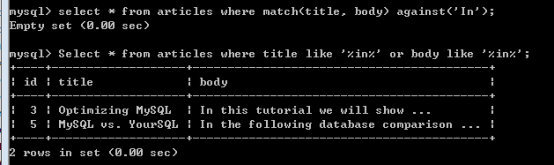
原因何在呢?全文索引,索引的的關鍵字,不是整個欄位資料,而是從資料中提取的關鍵詞。
8.索引結構-b-tree介紹
Hash、B-Tree(B樹)兩種資料結構。指的是mysql儲存索引所採用的資料結構。其中,使用者所維護的所有的索引結構 B-Tree結構。
MYSQL優化
MYSQL優化主要分為以下四大方面:
設計:儲存引擎,欄位型別,正規化與逆正規化
功能:索引,快取,分割槽分表。
架構:主從複製,讀寫分離,負載均衡。
合理SQL:測試,經驗。
一、儲 inno user val 事務 優化 好的 維護 排列 測試結果 對於一些數據量較大的系統,數據庫面臨的問題除了查詢效率低下,還有就是數據入庫時間長。特別像報表系統,每天花費在數據導入上的時間可能會長達幾個小時或十幾個小時之久。因此,優化數據庫插入性能是很有意義的。經過對
案例所用的表結構、索引、與資料如下:
索引失效與優化
1、全值匹配我最愛
2、最佳左字首法則(帶頭索引不能死,中間索引不能斷)
如果索引了多個列,要遵守最佳左字首法則。指的是查詢從索引的最左前列開始 並且 不跳過索引中的列。
正確的示例參考上圖。
錯誤的示例:
客戶端與MySQL伺服器的查詢通訊步驟如下
客戶端與伺服器進行通訊
SQL語句查詢MySQL服務的快取(如果伺服器開啟了快取)
解析器將SQL語句解析為解析樹
前處理器判斷解析樹是否符合規範
查詢優化器對SQl進行優化處理
查詢執行引擎查詢資料
返回
MySQL索引的概念 索引是一種特殊的檔案(InnoDB資料表上的索引是表空間的一個組成部分),它們包含著對資料表裡所有記錄的引用指標。更通俗的說,資料庫索引好比是一本書前面的目錄,能加快資料庫的查詢速度。 索引分為聚簇索引和非聚簇索引兩種,聚簇索引是按照資料存放
目錄
慢查詢日誌
1. 慢查詢日誌開啟
2. 慢查詢日誌設定與檢視
3.日誌分析工具mysqldumpslow
序言: 在我面試很多人的過程中,很多人談到S
目錄
MySQL之SQL優化詳解(二)
1. SQL的執行順序
1.1 手寫順序
1.2 機讀順序
2. 七種join
3. 索引
3.1 索
目錄
MySQL 之SQL優化詳解(三)
1. 索引優化
2. 剖析報告:Show Profile
MySQL 之SQL優化詳解(三)
1. 索引優化
一旦建立索引,selec mysqlmysql 索引詳解 nginx優化(1)nginx運行工作進程個數,一般設置cpu的核心或者核心數x2如果不了解cpu的核數,可以top命令之後按1看出來,也可以查看/proc/cpuinfo文件 grep ^processor /proc/cpuinfo | wc -l [[email protected]/* * 構造 bitset 更多 隱患 .net wrapper 屬性設置 似的 擔心 1 lucene簡介1.1 什麽是luceneLucene是一個全文搜索框架,而不是應用產品。因此它並不像www.baidu.com 或者google Desktop那麽拿來就能用,它只是提供了 null pen head 並不是 階段 後者 訪問類 union 查找 explain命令的使用及相關參數說明。
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
EXPLAIN Output Colu 臨時表 引用 edi 強制 順序存儲 實現 好的 float 空間 轉載自:http://www.jb51.net/article/71041.htm
如果不能設計一個合理的數據庫模型,不僅會增加客戶端和服務器段程序的編程和維護的難度,而且將會影響系統實際運行的性能。所以, 含義 訪問 面試題 增長 variable 切換 dos命令 技術 運行 第1章 數據庫1.1 數據庫概述l 什麽是數據庫數據庫就是存儲數據的倉庫,其本質是一個文件系統,數據按照特定的格式將數據存儲起來,用戶可以對數據庫中的數據進行增加,修改,刪除及查詢操作。l 什麽是數據 無限 bin esp mpat 活躍 壓縮 常見 定向 rms 1. 目的
通過優化tomcat提高網站的並發能力。
2. 服務器資源
服務器所能提供CPU、內存、硬盤的性能對處理能力有決定性影響。
3. 優化配置
3.1. 配置tomcat管理員賬戶
在con 監牢模式 優雅顯示 防盜鏈 非法解析 12 配置Nginx gzip壓縮實現性能優化
100k ---- 1s 90k
100k ---- 5s 10k
gzip on;
gzip_min_length 1k;
gzip_buffers 索引查找 ID dex 分別是 重新 system 類型 bsp 常常 在日常工作中,我們會有時會開慢查詢去記錄一些執行時間比較久的SQL語句,找出這些SQL語句並不意味著完事了,些時我們常常用到explain這個命令來查看一個這些SQL語句的執行計劃,查看該SQL語句有沒 ror sql log-error dex -i ria 二進制日誌 ble time 日誌分類:
一、錯誤日誌。
1、在配置文件中的配置是:log-error="DESKTOP-igoodful.err",查看參數的鍵值對:show variables like ‘ nginx優化 高並發 user www www;——配置nginx運行用戶和用戶組,使用之前創建用戶useradd www -s /sbin/nologin -M
worker_processes 4;——配置nginx worker進程數,根據cpu內核數設置,也可以設置成auto
worker 無需 文件中 就是 系統路徑 python 順序 使用方式 一行 系列 一、模塊
1.模塊的定義
模塊是一組包含了一組功能的python文件,比如test.py,模塊名為test,可以通過import test進行調用。模塊可以分為以下四個通用類別
1 使用python 相關推薦
MySQL優化詳解
MySQL批量SQL插入性能優化詳解
MySQL高階 之 索引失效與優化詳解
MySQL查詢優化詳解
Mysql索引詳解及優化(key和index區別)
MySQL之SQL優化詳解(一)
MySQL之SQL優化詳解(二)
MySQL之SQL優化詳解(三)
mysql 索引詳解
nginx配置項優化詳解
lucene、lucene.NET詳細使用與優化詳解[轉]
MySQL explain 詳解
大數據量高並發的數據庫優化詳解(MSSQL)
【傳智播客鄭州校區】數據庫MYSQL筆記詳解
Java Tomcat7性能監控與優化詳解
web網站集群之企業級Nginx Web服務優化詳解(二)
MySQL Explain詳解
mysql日誌詳解
nginx.conf 配置優化詳解
python之模塊定義、導入、優化詳解