
Hadoop教程(一) Hadoop入門教程
1 Hadoop入門教程
Hadoop是Apache開源組織的一個分散式計算開源框架(http://hadoop.apache.org/),用java語言實現開源軟體框架,實現在大量計算機組成的叢集中對海量資料進行分散式計算。Hadoop框架中最核心設計就是:HDFS和MapReduce,HDFS實現儲存,而MapReduce實現原理分析處理,這兩部分是hadoop的核心。資料在Hadoop中處理的流程可以簡單的按照下圖來理解:資料通過Haddop的叢集處理後得到結果,它是一個高效能處理海量資料集的工具。
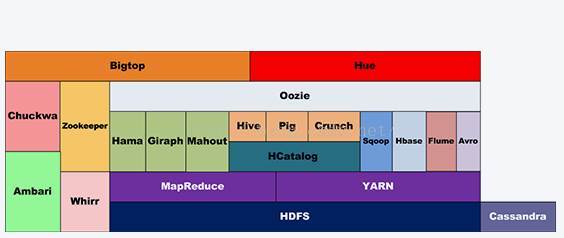
1.1 Hadoop家族
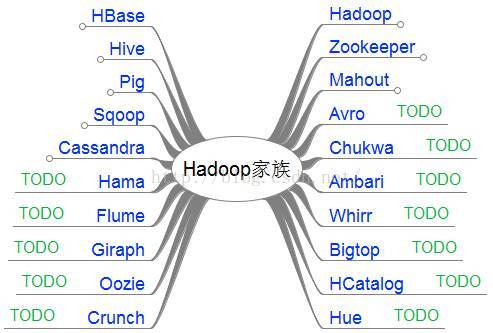
1、是Apache開源組織的一個分散式計算開源框架,提供了一個分散式檔案系統子專案
2、是基於Hadoop的一個數據倉庫工具,可以將結構化的資料檔案對映為一張資料庫表,通過類SQL語句快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合資料倉庫的統計分析。
3、是一個基於Hadoop的大規模資料分析工具,它提供的SQL-LIKE語言叫PigLatin,該語言的編譯器會把類SQL的資料分析請求轉換為一系列經過優化處理的MapReduce運算。
4、是一個高可靠性、高效能、面向列、可伸縮的分散式儲存系統,利用HBase技術可在廉價PCServer上搭建起大規模結構化儲存叢集。
5、
6、是一個為分散式應用所設計的分佈的、開源的協調服務,它主要是用來解決分散式應用中經常遇到的一些資料管理問題,簡化分散式應用協調及其管理的難度,提供高效能的分散式服務。
7、是基於Hadoop的機器學習和資料探勘的一個分散式框架。Mahout用MapReduce實現了部分資料探勘演算法,解決了並行挖掘的問題。
8、是一套開源分散式NoSQL資料庫系統。它最初由Facebook
9、是一個數據序列化系統,設計用於支援資料密集型,大批量資料交換的應用。Avro是新的資料序列化格式與傳輸工具,將逐步取代Hadoop原有的IPC機制。
10、是一種基於Web的工具,支援Hadoop叢集的供應、管理和監控。
11、是一個開源的用於監控大型分散式系統的資料收集系統,它可以將各種各樣型別的資料收整合適合Hadoop處理的檔案儲存在HDFS中供Hadoop進行各種MapReduce操作。
12、是一個基於HDFS的BSP(BulkSynchronousParallel)平行計算框架,Hama可用於包括圖、矩陣和網路演算法在內的大規模、大資料計算。
13、是一個分佈的、可靠的、高可用的海量日誌聚合的系統,可用於日誌資料收集,日誌資料處理,日誌資料傳輸。
14、是一個可伸縮的分散式迭代圖處理系統,基於Hadoop平臺,靈感來自BSP(bulksynchronousparallel)和Google的Pregel。
15、是一個工作流引擎伺服器,用於管理和協調執行在Hadoop平臺上(HDFS、Pig和MapReduce)的任務。
16、是基於Google的FlumeJava庫編寫的Java庫,用於建立MapReduce程式。與Hive,Pig類似,Crunch提供了用於實現如連線資料、執行聚合和排序記錄等常見任務的模式庫。
17、是一套運行於雲服務的類庫(包括Hadoop),可提供高度的互補性。Whirr學支援AmazonEC2和Rackspace的服務。
18、是一個對Hadoop及其周邊生態進行打包,分發和測試的工具。
19、是基於Hadoop的資料表和儲存管理,實現中央的元資料和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供關係檢視。
20、是一個基於WEB的監控和管理系統,實現對HDFS,MapReduce/YARN,HBase,Hive,Pig的web化操作和管理。
1.2 HDFS檔案系統
HDFS(Hadoop Distributed File System,Hadoop分散式檔案系統),它是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的資料訪問,適合那些有著超大資料集(largedata set)的應用程式。
HDFS的設計特點:
1、大資料檔案,非常適合上T級別的大檔案或者一堆大資料檔案的儲存。
2、檔案分塊儲存,HDFS會將一個完整的大檔案平均分塊儲存到不同計算器上,它的意義在於讀取檔案時可以同時從多個主機取不同區塊的檔案,多主機讀取比單主機讀取效率要高得多。
3、流式資料訪問,一次寫入多次讀寫,這種模式跟傳統檔案不同,它不支援動態改變檔案內容,而是要求讓檔案一次寫入就不做變化,要變化也只能在檔案末新增內容。
4、廉價硬體,HDFS可以應用在普通PC機上,這種機制能夠讓給一些公司用幾十臺廉價的計算機就可以撐起一個大資料叢集。
5、硬體故障,HDFS認為所有計算機都可能會出問題,為了防止某個主機失效讀取不到該主機的塊檔案,它將同一個檔案塊副本分配到其它某幾個主機上,如果其中一臺主機失效,可以迅速找另一塊副本取檔案。
HDFS的master/slave構架:
一個HDFS叢集是有一個Namenode和一定數目的Datanode組成。Namenode是一箇中心伺服器,負責管理檔案系統的namespace和客戶端對檔案的訪問。Datanode在叢集中一般是一個節點一個,負責管理節點上它們附帶的儲存。在內部,一個檔案其實分成一個或多個block,這些block儲存在Datanode集合裡。Namenode執行檔案系統的namespace操作,例如開啟、關閉、重新命名檔案和目錄,同時決定block到具體Datanode節點的對映。Datanode在Namenode的指揮下進行block的建立、刪除和複製。Namenode和Datanode都是設計成可以跑在普通的廉價的執行linux的機器上。
HDFS的關鍵元素:
1、Block:將一個檔案進行分塊,通常是64M。
2、NameNode:儲存整個檔案系統的目錄資訊、檔案資訊及分塊資訊,這是由唯一一臺主機專門儲存,當然這臺主機如果出錯,NameNode就失效了。在Hadoop2.*開始支援activity-standy模式----如果主NameNode失效,啟動備用主機執行NameNode。
3、DataNode:分佈在廉價的計算機上,用於儲存Block塊檔案。
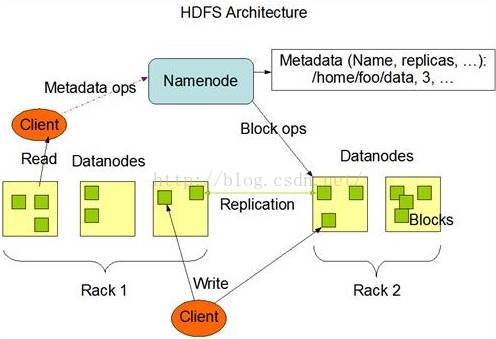
HDFS架構圖
4、Namenode全權管理資料塊的複製,它週期性地從叢集中的每個Datanode接收心跳訊號和塊狀態報告(Blockreport)。接收到心跳訊號意味著該Datanode節點工作正常。塊狀態報告包含了一個該Datanode上所有資料塊的列表。
5、參考資料
1.3 MapReduce檔案系統
MapReduce是一種程式設計模型,用於大規模資料集(大於1TB)的並行運算。MapReduce將分成兩個部分"Map(對映)"和"Reduce(歸約)"。
當你向MapReduce框架提交一個計算作業時,它會首先把計算作業拆分成若干個Map任務,然後分配到不同的節點上去執行,每一個Map任務處理輸入資料中的一部分,當Map任務完成後,它會生成一些中間檔案,這些中間檔案將會作為Reduce任務的輸入資料。Reduce任務的主要目標就是把前面若干個Map的輸出彙總到一起並輸出。
MapReduce流程圖:
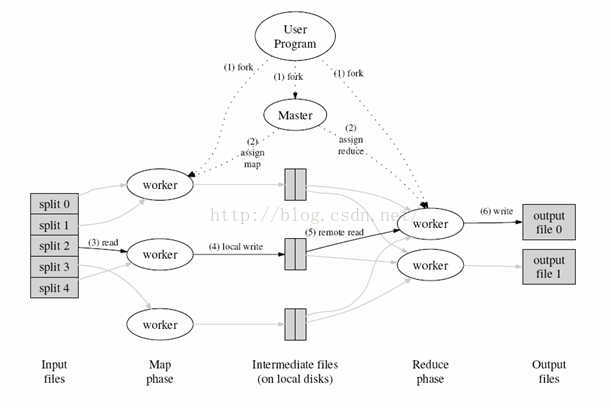
MapReduce流程圖
步驟1:首先對輸入資料來源進行切片
步驟2:master排程worker執行map任務
步驟3:worker讀取輸入源片段
步驟4:worker執行map任務,將任務輸出儲存在本地
步驟5:master排程worker執行reduce任務,reduce worker讀取map任務的輸出檔案
步驟6:執行reduce任務,將任務輸出儲存到HDFS
1.4 學習Linux推薦書籍:
--以上為《Hadoop入門教程》,如有不當之處請指出,我後續逐步完善更正,大家共同提高。謝謝大家對我的關注。——厚積薄發(yuanxw)