
深入淺出leveldb之高效能中鎖的使用
記得大學剛畢業那年看了侯俊傑的《深入淺出MFC》,就對深入淺出這四個字特別偏好,並且成為了自己對技術的要求標準——對於技術的理解要足夠的深刻以至於可以用很淺顯的道理給別人講明白。以下內容為個人見解,如有雷同,純屬巧合,如有錯誤,煩請指正。
因為leveldb很多型別的宣告和實現分別在.h和.cc兩個檔案中,為了程式碼註釋方便,我將二者合一(類似JAVA和GO類的定義方法),讀者在原始碼中找不到我引用的部分屬於正常現象。在閱讀被文章之前請先閱讀《深入淺出leveldb之基礎知識》和《深入淺出leveldb之MemTable》
目錄
言
在使用leveldb的時候,大家都知道leveldb是執行緒安全的,在我的認知裡執行緒安全和高效能多半二者取其一。道理很簡單,要想執行緒安全,一般都要有鎖的參與,有鎖參與很多時候無法實現較高的效能。當然這不是絕對的,無鎖佇列利用CPU的CAS指令實現原子操作是一種非常好設計,讀寫鎖也是一個好用的東東,而leveldb中對於鎖和原子的使用我也認為是一種非常不錯的設計。
首先要強調的是leveldb的中鎖和原子的使用多事基於leveldb的設計方案實現的,所以可能有些場景不適用,但是絕對是有參考價值的。
寫操作的執行緒安全
有些東西用語言描述不清楚的時候,最好的辦法就是用程式碼解釋,下面的程式碼是leveldb寫操作的原始碼,如果讀者起初對於部分註釋表示不清晰沒有關係,繼續往下看,等你把所有的註釋都看完了再回頭看就明白了。正所謂溫故而知新~
// 程式碼源自leveldb/db/db_impl.cc // 所有的leveldb寫入操作最終都會變成如下程式碼所示的批量寫入,無非是批量寫一個還是寫多個的問題 Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) { // 此處先不要計較Writer是個什麼東西,只要知道他是個結構體,用於記錄此次寫入的上下文(或者環境) Writer w(&mutex_); w.batch = my_batch; // 記錄要寫入的資料 w.sync = options.sync; // 記錄要寫入的選項,只有是否同步一個選項 w.done = false; // 寫入的狀態,完成或者未完成,當前肯定是未完成 // mutex_是leveldb的全域性鎖,在DBImpl有且只有這一個互斥鎖(還有一個檔案鎖除外),所有操作都要基於這一個鎖實現互斥 // 是不是感覺有點不可思議?MutexLock是個自動鎖,他的建構函式負責加鎖,解構函式負責解鎖 MutexLock l(&mutex_); // writers_是個std::deque<Writer*>,是DBImpl的成員變數,也就意味著多執行緒共享這個變數,所以是在加鎖狀態下操作的 writers_.push_back(&w); // 看到下面的程式碼有意思麼?這段程式碼保證了寫入是按照呼叫的先後順序執行的。 // 1.w.done不可能是true啊,剛剛賦值為false,為什麼還要判斷呢?除非有人改動,沒錯,後面有可能會被其他執行緒改動 // 2.剛剛放入佇列尾部,此時如果前面有執行緒寫,那麼&w != writers_.front()會為true,所以要等前面的寫完在喚醒 // 3.w.cv是一個可以理解為pthread_cond_t的變數,w.cv.Wait()其實是需要解鎖的,他解的就是mutex_這個鎖 while (!w.done && &w != writers_.front()) { w.cv.Wait(); } // 剛剛也提到了,雖然期望是自己執行緒把自己的資料寫入,因為資料放入了writers_這個佇列中,也就意味著別的執行緒也能看到 // 也就意味著別的執行緒也能把這個資料寫入,那麼什麼情況要需要其他執行緒幫這個執行緒寫入呢?“且聽下面分解” // 單田芳於昨日去世,作為粉絲紀念一下單田芳老爺子 if (w.done) { return w.status; } // 這個就是要判斷當前的空間是否能夠繼續寫入,包括MemTable以及SSTable,如果需要同步檔案或者合併檔案就要等待了 // 讀者自行分析那部分程式碼,或者等一段時間看我對這部分原始碼的分析 Status status = MakeRoomForWrite(my_batch == NULL); // 獲取當前最後一個順序號,這個好理解哈 uint64_t last_sequence = versions_->LastSequence(); // 接下來就是比較重點的部分了,last_writer記錄了一次真正寫入的最後一個Writer的地址,就是會合並多個Writer的資料寫入 // 當然,初始化是當前這個執行緒的Writer,因為很可能後面沒有其他執行緒執行寫入 Writer* last_writer = &w; // 開始寫入之前需要保證空間足夠並且確實有資料要寫 if (status.ok() && my_batch != NULL) { // NULL batch is for compactions // 此處就是合併寫入的過程,函式名字也能看出這個意思,感興趣的讀者自行看程式碼 WriteBatch* updates = BuildBatchGroup(&last_writer); // 為合併後的每條記錄都設定順序號,不是什麼重點,函式後面也不會展開分析 WriteBatchInternal::SetSequence(updates, last_sequence + 1); // 更新順序號,先記在臨時變數中,等操作全部成功後再更新資料庫狀態 last_sequence += WriteBatchInternal::Count(updates); // 前方高能,請讀者注意 { // 此處解鎖了,也就意味著其他執行緒可以同時讀取或者寫入leveldb,寫入肯定會被放到writers_隊尾等待 // 那讀取該如何保證執行緒安全性,解鎖後畢竟還是要操作MemTable的,這個後面章節會有詳細說明 // 這裡要說明的是,因為寫入操作要有檔案寫入,必要時還有檔案同步,如果不解鎖效能肯定很低 mutex_.Unlock(); // log_可以想象為一個檔案,AddRecord可以想象為檔案的追加(append)操作,就是所有記錄是先追加到日誌檔案 // 因為寫入的這個流程設計永遠都保證一個執行緒操作這個日誌檔案,所以不會出現亂序問題,而讀取是訪問MemTable // 所以不需要在加鎖狀態先執行 status = log_->AddRecord(WriteBatchInternal::Contents(updates)); // 如果使用者配置了同步選項,那麼就要執行檔案同步操作,可以想象為flush(),這樣比較安全,但是效能會第一點 bool sync_error = false; if (status.ok() && options.sync) { status = logfile_->Sync(); if (!status.ok()) { sync_error = true; } } // 寫入日誌檔案成功,那麼就要把資料同步到MemTable中了 if (status.ok()) { status = WriteBatchInternal::InsertInto(updates, mem_); } // 耗時的操作都完事了,重新進入加鎖狀態,後面要操作共享資源 mutex_.Lock(); // 如果上面的過程失敗了,那麼就要喚醒所有的執行緒報錯 if (sync_error) { RecordBackgroundError(status); } } if (updates == tmp_batch_) tmp_batch_->Clear(); // 更新最新的順序號,因為寫入操作已經成功 versions_->SetLastSequence(last_sequence); } // 還是比較有趣的程式碼,由於此次寫入可能會批量的把後面的多個數據一併寫入,所以此處就要逐一的告知後面寫入的執行緒 while (true) { // 從writers_取出一個元素 Writer* ready = writers_.front(); writers_.pop_front(); // 判斷這個Writer是不是自己執行緒的資料,如果不是,那就告訴那個執行緒資料已經被寫入了 if (ready != &w) { ready->status = status; ready->done = true; // 設定完成標記,上面的程式碼我們知道執行緒被喚醒後要判斷這個標記 ready->cv.Signal(); // 喚醒這個阻塞的執行緒,注意:當前還沒有解鎖,所以執行緒還沒有真正被喚醒 } // 直到處理完最後一個Writer為止 if (ready == last_writer) break; } // 如果writers_中還有資料,那就把列表頭中的那個執行緒喚醒,因為前面喚醒的是被這個執行緒一併順帶寫入的資料的執行緒 // 這些執行緒喚醒後直接回返回,不會繼續喚醒後面的執行緒 if (!writers_.empty()) { writers_.front()->cv.Signal(); } return status; }
如果一次沒看懂沒關係,那就多看幾次就明白了~我這裡總結一下leveldb實現寫操作的幾個關鍵點:
- 通過std::deque實現寫入執行緒按照呼叫時間先後順序執行,這就保證了寫入操作的執行緒安全性;
- 實際寫入是在無鎖狀體下執行的,意味著執行檔案和MemTable寫入的同時可以讀取和繼續向std::deque中追加,這樣的設計就為合併多次寫入操作提供了條件;比如在寫第一條資料的時候因為在加鎖狀態下無法合併第二條及以後的資料(因為此時執行緒因為鎖而掛起),但是第一條資料寫入檔案過程中第二、三、四......條資料已經在std::deque中排隊了,那麼開始寫入第二條資料的時候就可以合併第三、四....條資料了;
- 因為資料的合併寫入,使得寫入效能相比於逐條寫入提升不少,尤其是在有同步選項的時候;
讀寫操作的執行緒安全
上面我們分析了leveldb的寫入執行緒安全,因為std::deque、mutex、cond的巧妙使用,使得寫入執行緒可以排隊按序執行。但是在無鎖狀態下讀取和寫入是如何保證執行緒安全的呢?這就是這個章節討論的重點了。
首先,我們需要明確一點,寫入操作在無鎖狀態下只會操作日誌檔案和MemTable,MemTable其實就是日誌檔案的記憶體副本,只是表現形式不同罷了。那麼我們分析的切入點就變得很簡單了,因為其他在有鎖狀態下執行也就沒必要分析所謂的執行緒安全了。而讀取操作在無鎖狀態只會訪問MemTable和SSTable,不難看出二者的交叉點在MemTable,只要保證MemTable是執行緒安全的就可以了。這時候我相信大部分人第一想法是在MemTable加鎖,確實又簡單又方便,但是google大神可不這麼認為,大神用的是原子指標實現的。看過我《深入淺出leveldb之MemTable》的讀者知道,整個程式碼沒看到任何鎖的痕跡。當初我分析MemTable的時候就不理解為啥要用這老多的原子指標,直到我開始這篇部落格的時候才算真正理解大神的用意。好了,整那老多臭氧層也沒啥用,咱們說重點。
MemTable其實只是一個殼子(基本上就是在封裝),真正的實現還是SkipList,所以SkipList才是我們真正要分析的。具體寫入的程式碼此處不再分析了(看《深入淺出leveldb之MemTable》就可以了),我們用一個圖來表達寫入的過程:
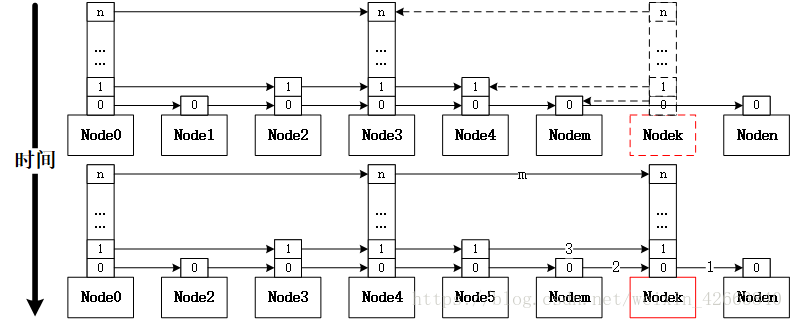
上圖中,紅色的是需要插入的節點(資料),虛線表示為區域性變數,因為區域性變數是執行緒安全的,所以通過區域性變數記錄了新節點需要插入時前向節點都是哪些(跳躍表每個節點都是有高度的,每個高度都有連結串列)。 然後先將節點的指標依次指向後向節點,再將Node的前向節點依次執行自己,依次的順序是高度從低到高(如上圖所示序號1、2、3.......m)。這個過程中所有獲取和設定指標都是原子指標操作,所以寫入和讀取都不會有打斷情況,也就是說保證寫入和讀取。有人肯定會問,難道這就能保證執行緒安全了麼?答案是肯定的,我們來分析這個過程:
- 整個寫入過程操作連結串列的時候有兩個步驟,分別是先讓節點指向後向節點,然後再讓前向節點指向自己,第一步因為沒有實際操作連結串列,所以本身就是安全的,只有第二步執行的過程如果執行緒切換或者同時讀取(畢竟都是多核的機器)才會有可能存在不安全的可能;
- 因為節點有高度,每個高度都要操作一次指標,所以整個過程並不是原子的,如果讀取時通過節點m訪問下一個節點是節點n,但是因為同時執行寫入實際讀取卻是k(因為讀取要seek,先比較再偏移下一個,是一個兩步操作),此時無非再通過節點k向節點n逼近一次就可以了,並不影響安全;
- 因為無論是寫入還是讀取(通過迭代器順序讀取除外),都是先要seek,即定位,seek是從高到低方式訪問連結串列逐漸逼近期望節點,而節點插入是從低到高插入連結串列,一旦seek過程訪問了還沒有插入完畢的節點時,該節點的低於當前高度的連結串列已經插入完畢,所以也不存在安全問題;
- 如果通過迭代器遍歷節點時,因為寫入和讀取指標都是原子的,所以也不存在安全問題;
- 所有的這一切源於一個大家可能不太在乎的關鍵點,那就是採用的單向連結串列,單向連結串列插入實際上只有一步操作,只要這個操作是原子的可以保證安全,這也是我在《深入淺出leveldb之MemTable》提到迭代器反向遍歷效率低,MemTable沒有采用雙向量表的核心原因,畢竟正向遍歷的使用概率還是比較高的;
- 因為MemTable沒有刪除操作,永遠是新增操作,也進一步鞏固了該設計方案,因為刪除操作會存在不安全的可能,即便通過前向節點直接指向後向節點一步操作實現刪除,但是問題在於本應該移動到節點k,實際確移動到了節點n,比較時節點k是小於指定鍵的,而實際偏移到的節點n可能大於指定鍵;
總結
經過系統性的分析,我們瞭解到leveldb實現高效能安全讀寫的幾個關鍵點:
- 利用佇列將寫入執行緒排隊有序執行,寫操作實現了邏輯上的單執行緒操作;
- 在寫入檔案和MemTable過程是無鎖狀態,此時可以同時寫入和讀取資料,合併多個數據寫入進一步提升寫入效能;
- 利用原子指標代替鎖避免了鎖本身帶來的執行緒切換開銷;
- 能用原子指標的必要條件是單向連結串列和無刪除操作;